comfyUI
一个从输入到输出的完整工作流程, 最大的意义在于提高了我们运用 sd 的自由度. 使用其他界面时, 只能按照开发者设定好的 ui 调节有限的参数来进行一个固定流程的生成. 但是在 confyui 里, 各种功能节点可以自由组合, 可以用演变出成百上千种不同的生成方式. 让我们原本需要在不同的板块, 插件里进行的工作, 可以环环相扣的组合在一起. 实现一些复杂工作流程的全自动化运作. 理论上来说绝大部分的 AIGC 应用需要封装 sd 的功能时, 都是基于工作流搭建的.
一个个节点就像是一个个函数. 管道函数
可迁移性强, 可以导出为一个完整的文件并且分享给其他人. 其他打开这个文件即可复现全部的提示词和参数
webUI 生成的图片, 自身带有参数信息, 可以直接导入 comfyUI 的工作流中. 会自动生成该图片生成所需的工作流
优秀工作流搜集
cuteYou: CuteYou 工作流升级2.0 - AI卡通画像最佳选择_哔哩哔哩_bilibili 一键转绘泡泡马特风格玩偶
直接上 openart 上面找就行 ComfyUI Workflows - Developer Community
UI 操作
左键按住就可以拖拽
按住 control 拖动鼠标来框选. mac 上是 mac 健
在空白处双击, 可以调起搜索面板, 快速插入自己想要的节点
左上角折叠不需要操作的节点
可以手动调节的接口都可以转换为一个输入端口, 通过另一个节点输入参数
直接从出参端口拉一条线, 松开, 就会提示可用的下一个节点. 不用每个都自己 add 或者 搜索
右键 bypass 忽略节点, 快捷键 C+B
从 workflow 保存列表里拖出来的可以做合并. 也可以右键, save as template
最基础的文生图
- 选择大模型
- prompt
load checkpoint 节点
clip text Enode 节点
empty latent image
KSampler
VAE Decode
Save Image
节点端口
也就是节点的入参和出参
端口的颜色就代表了参数的类型. 相同颜色的端口即可连线传参
一个输出端口的数据, 可以输出到多个端口上.
但是一个端口不能同时接受多个输入
Loader
Loaders 分类内的各种节点一般被用于加载 Stable Diffusion 生我过程中需要用到的各种模型一一不只是 Checkpoint 大模型, 包括 LoRA、VAE 乃至 ControlNet 在内的各种模型都可以借助它里面的节点来加载。
Load Checkpoint
输出可能包含 vae. 因为有的大模型是自带 vae 的
Load Vae
有些大模型自带的 vae 出图的效果并不好. 可以加在一个单独的 load vae 的节点
Load LoRA
接在大模型后面. 因为端口很接近. 而且是在 UNet 层操作的
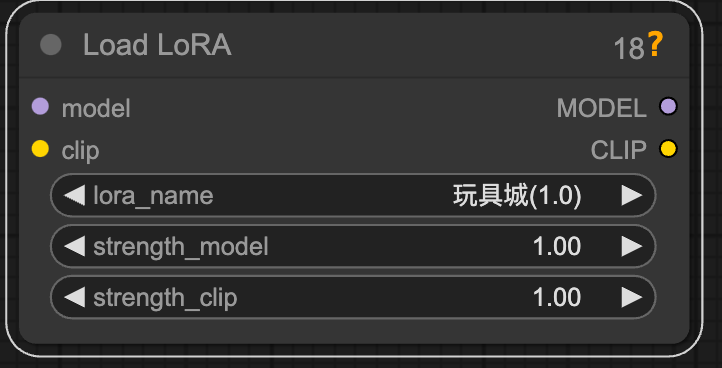
这两个权重数值分别被用于调节模型内的 CLIP 与主模型的权重。在大多数 UI 中, 这两个选项会被 " 合并 " 为一个数字。例如, 将 LoRA 强度设置为 0.8 与将 strength_model 和 strength_clip 都设置为 0.8 相同。
Conditioning
Conditioning 分类内的各种节点一般被用于为 Stable Diffusion 的生成过程添加各种条件, 并对这些条件进行编辑、重组。提示词 (Prompt) 可以被当做一种文本条件, 通常是是这些条件里最为核心的一部分.
Sampling
大名鼎鼎的 KSampler. 采样去噪.
have four entry point. you need to fill them all to make sampler run.
种子
与 webui 不同, 通过 control_after_generate 来控制. use fixed to freeze seed
increment & decrement will change seed by 1. suitable to fine tuning denoise result
Denoise
重绘幅度. 文生图的时候, 不会发挥作用
Latent
Latent 分类内的各种节点主管与 " 潜空间 " 有关的操作。反映到具体操作上, 包括图像的编解码 (VAE)、尺寸定义及缩放等。如果你了解了 Latent 的原理, 你会对它在这些流畅中的 " 作用 " 有更清晰的认知。
Empty Latend Image
VAE Decode
将 latend 数据转变为 image
VAE Encode
将图片转换为 latend 数据.
需要接受大模型的 vae 作为输入
Upscale Latend
为了避免 latend 的大小严格和导入的图像相同, 需要单独再整一个
Images
Images 分类内的各种节点则主管与像素空间内的 " 图片 " 有关的操作。从基础的图片加载、保存、预览, 到对图片做指定的裁切、放大 (运用放大模型), 都可以实现。
Save Image
Load Image
图生图
可以作为图片信息输入, 也可以作为蒙版使用. 对应不同的端口
自定义节点
通过 Git Clone 以及 ComfyUI Manager 等方式管理节点
comfyUI/custom_nodes
ComfyUI Manager
ComfyUI Manager install missing node
Preview Method
开启节点预览, 怎么会放在 manager 的 options 里面
Badge
显示节点创建顺序和内置的标签, 可以判断自定义节点和内置节点
Import Failed
custom node 导入失败, 删除文件夹之后, 重新通过 manager 安装可以解决. 使用 manager 内的 git clone 也行的
实用节点推荐
很多其实都是 webUI 功能在 comfyUI 的平替
Prompt 类
ComfyUI-Custom-Scripts
comfyUI 不支持以提示词的方式来读取 lora
通过翻译节点使用中文自然语言 pormpt, 效果嘛, 不确定.
Tagger 节点
clip 文本框转换为接受 text 输入, 就可以接受 tagger 的输出了.
第一次执行完之后 tagger 的反推词会出现在下面, 可以进行手动修改
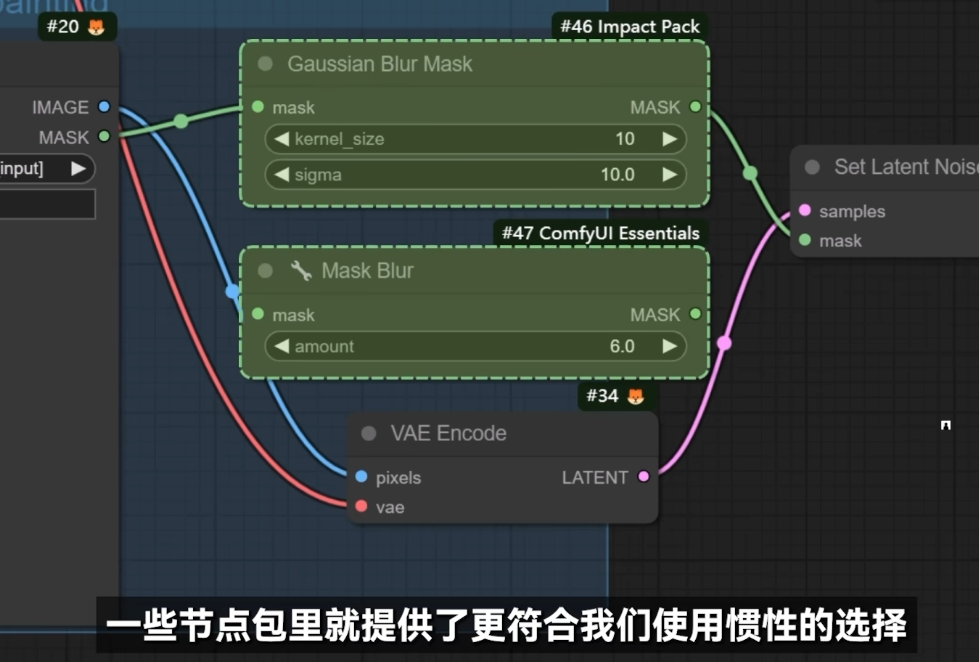
节点包
高清修复: 在生图结束之后再进行一次图生图, 所以一个工作流里面会有两个 KSampler
通过 pipe 式的 KSampler 来简化操作.
Impack Pack
Efficiency Nodes
效率节点
tinyterraNodes
典型工作流拆解
Upscale
2 Pass Txt2Img (Hires fix) Examples | ComfyUI_examples
高清修复
适当的重绘幅度, 去噪强度 0.5 左右. 因为本质就是更大分辨率的图生图.
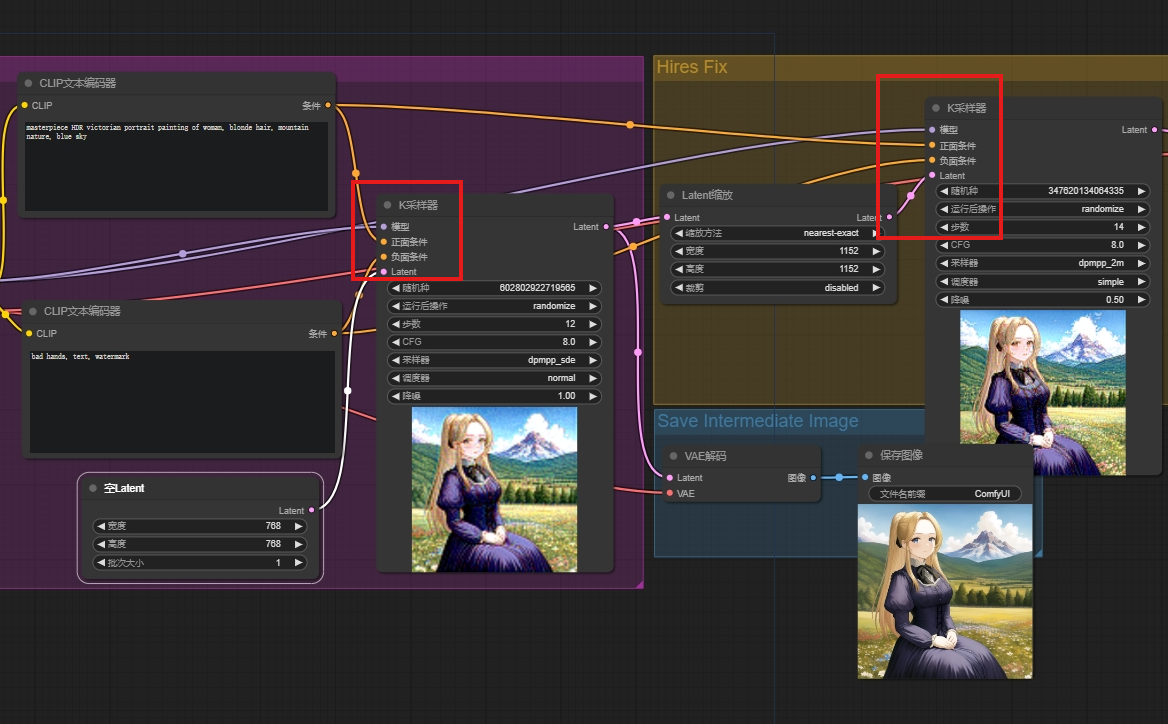
可以看到, 两次 KSampler 最大的区别就是 latent size 的不同. 其他的输入基本上可以说是一致的.
重绘幅度低于 0.5, 容易出现噪声没有去除干净的情况. 重绘幅度高于 0.8, 画面的改变就会很明显了. 也不好
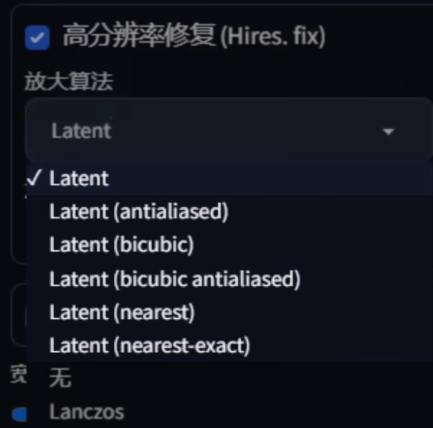
Non Latent Uspacling
同样是高清修复的一种, 就是 webUI 里经典的那个 RealESTAGN. 上面的 latent 类型的高清修复其实对应的是我们不常用的几个 options
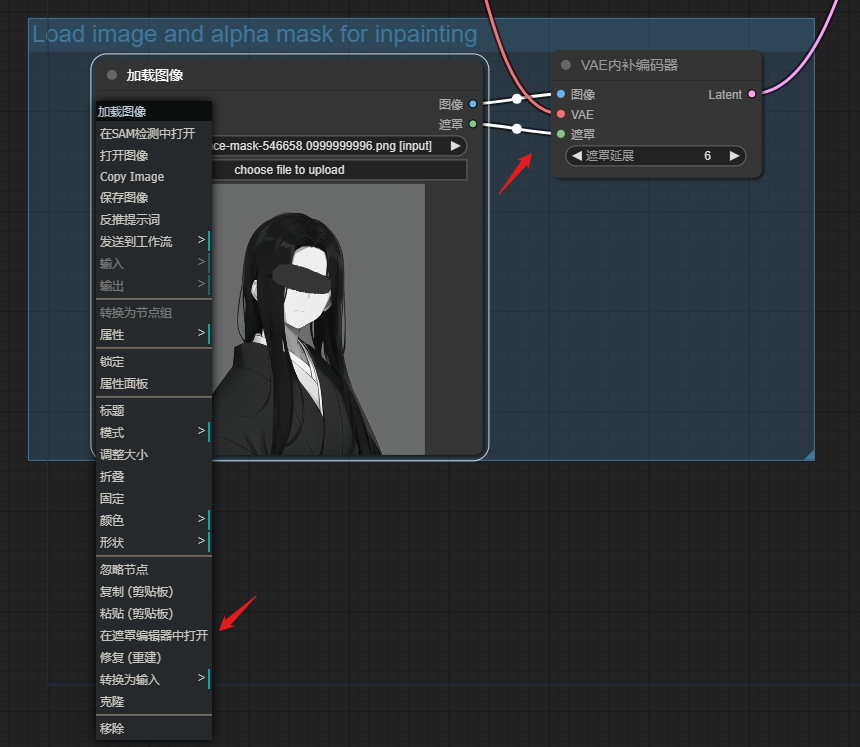
Inpaint
Mask
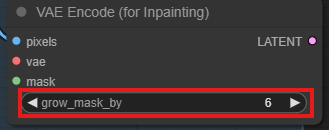
这个 vae 是专门为重绘服务的, 同时提供图片和遮罩给 vae encoder 即可
右键是橡皮擦
根据蒙版的指示, 只在蒙版区域做编码, 从而控制只在蒙版里做重绘. 重绘幅度不能太低, 否则就会生成非常违和的纯色块
因为这种重绘方式, 将我们绘制的区域转换为了空白潜空间, 再在此基础上重新加噪去噪生成. 因为如果不使用较高的力度去噪, 就很难生成新的形象.
因此利用 vae decode for inpainting 更适合用于对画面进行比较大的, 彻底的修改
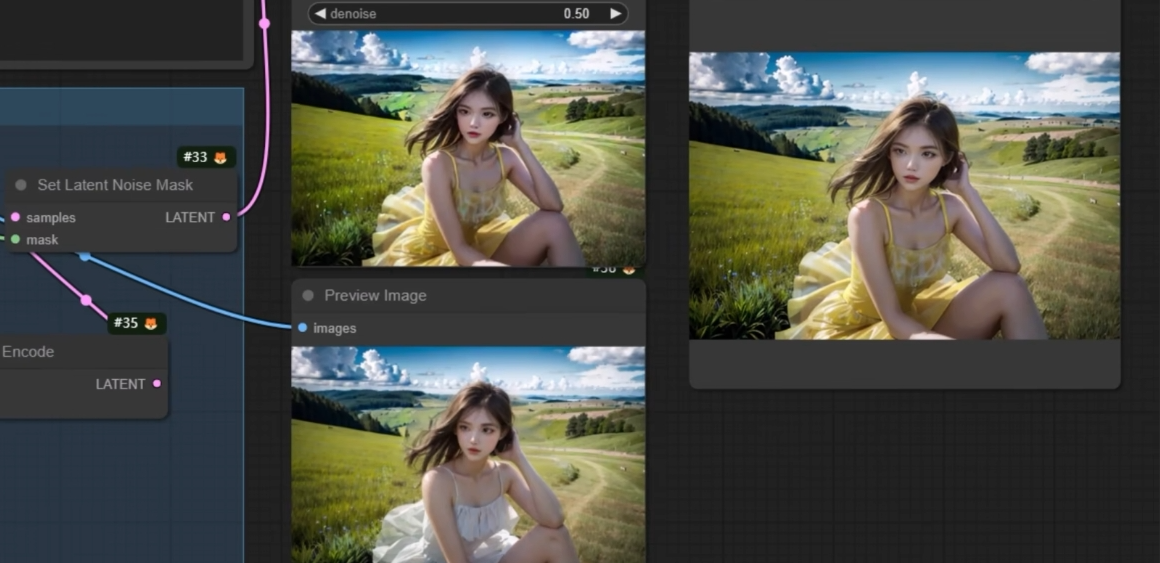
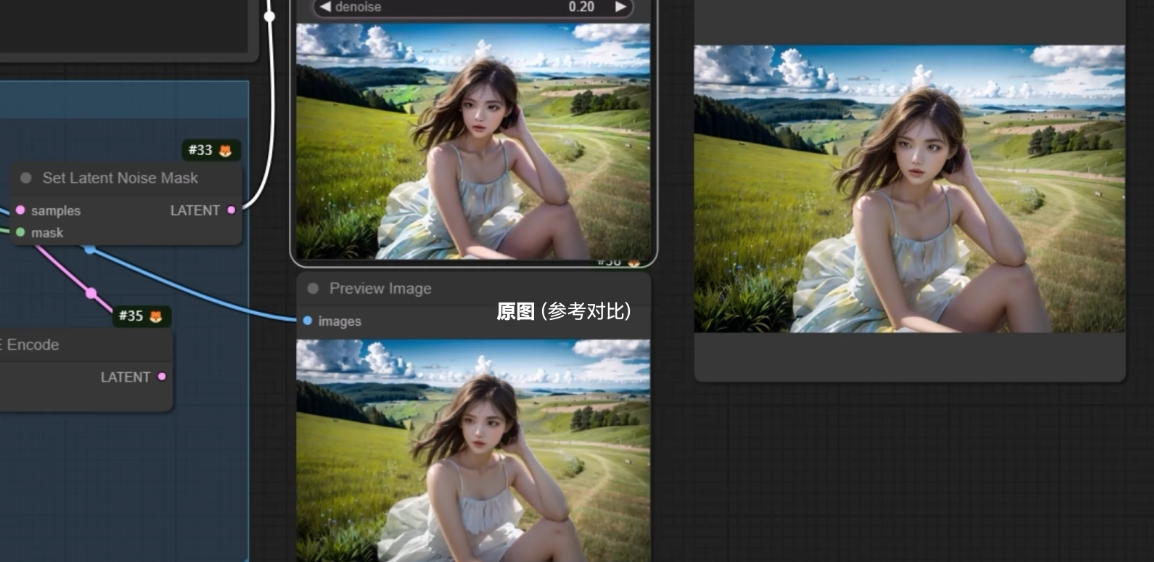
Set Latend Noise Mask
可以在 0.5 - 0.6 的中等重绘幅度之下, 实现和原图更像的局部重绘.
将指定区域原图像像素信息转换为潜空间数据之后, 在重新采样.
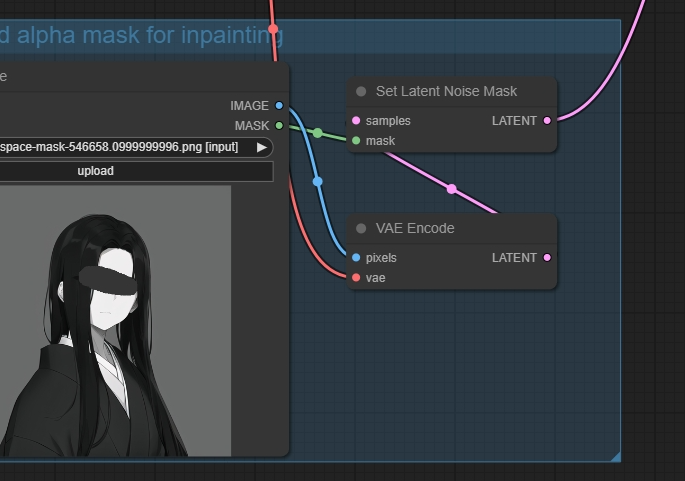
重绘编码器相当于是把指定区域单独挖出来做文生图, 原图里是什么和新生成的内容没有任何关系. 对应 webUI 里局部重绘的空白前空间模式
噪声蒙版会把原图对应的部分扣下来, 做一次图生图, 所以才可以保留原图的大致内容. 对应 webUI 里局部重绘的原图模式.
解决蒙版边缘的缝合感问题
在 webUI 里很多都是默认参数就帮我们解决了. 在 comfyUI 则被分散到了各种节点里面
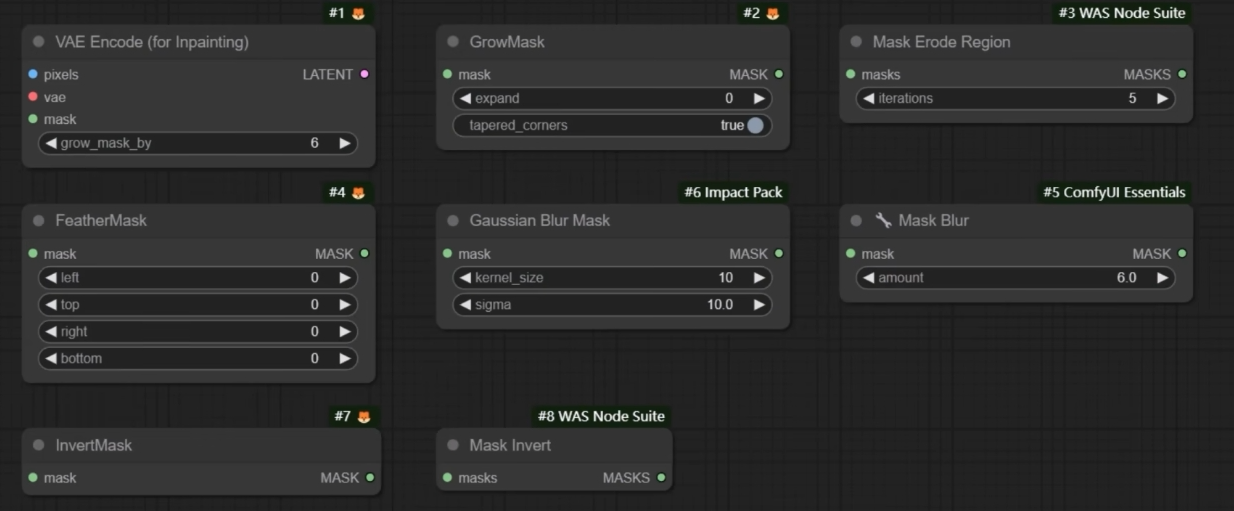
扩展
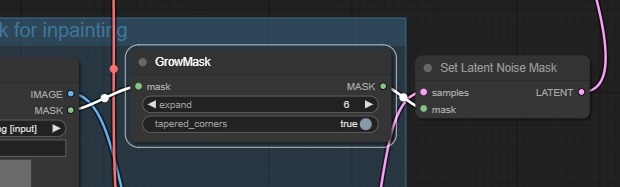
收缩
mask erode region
羽化
默认的 featherMask 只能模糊整个 mask 的边缘, 而不是 mask 边缘与原图的接缝处. 不是很好用
Invert
对应 webUI 的绘制蒙版还是非蒙版区域的控制. 原版就有自带的节点
Convert Mask to Image + Preview Image
使用一个专门的节点, 看看处理完之后的蒙版图片长什么样子
Covert Image to Mask
专门的节点. 实现上传蒙版遮罩的功能
Embeddings
直接在 prompt 里通过 emmbeddings 前缀就可以调用
Lora
在 webUI 里可以使用提示词引用 lora. 但是在 comfyUI 则不行. 因为 embeddings 本质上来说是 prompt 合集. 但是 lora 则是一组经过训练的附加权重.
在 comfyUI 里, 同样的, lora 需要通过连接, 附加到大模型上使用
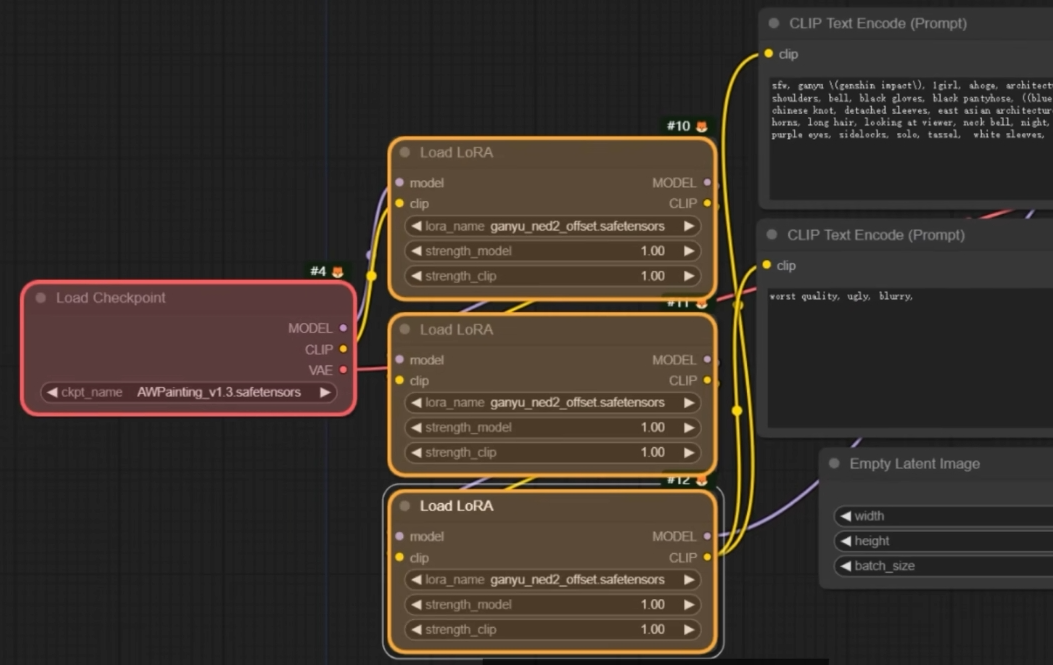

因为 lora 其实同时在文本和 unet 做了训练.
当二者相等的时候, 产生的效果就和在 webUI 里使用 priority 差不多
controlNet
实践
Condition
Concat
处理提示的一个非常有效的方法是通过条件连接节点。
该模型通常不善于理解多个概念和将不同元素的特征情境化。例如,指定不同颜色的对象可能非常困难。
采取提示:a blue ball a red bucket on the beach。

在这种情况下,成功率非常低,大约每 25 张图像中就有 1 张实际上显示的是一个红色桶和一个蓝色的球。
我们可以像这样使用 concat 来增加机会:
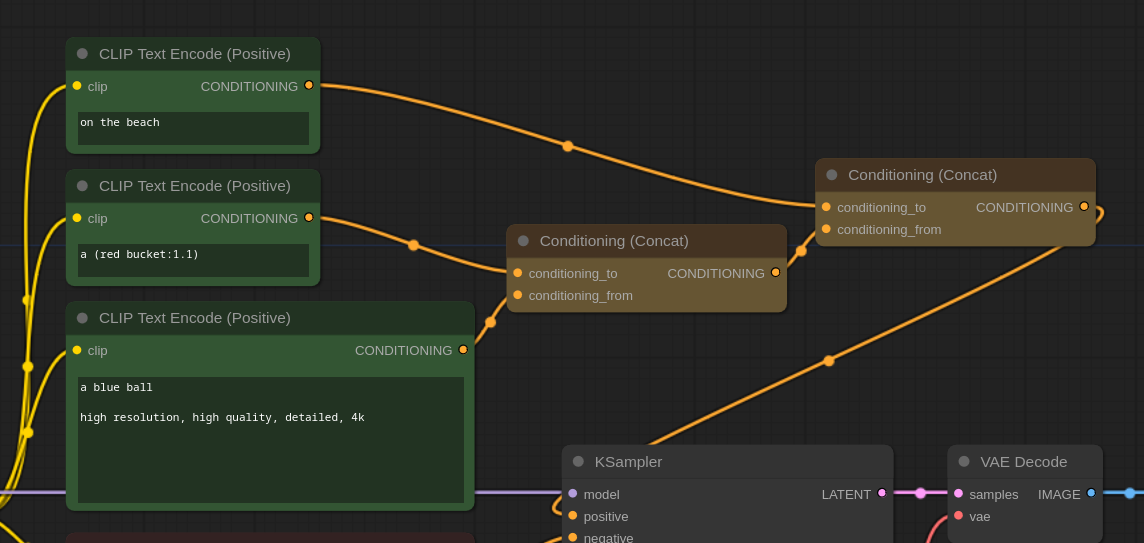
在这种情况下,我们的成功率约为三分之一。

Average
Sometimes you want to merge two concept together, like... a zebra-chameleon:

You can get lucky with simple prompting but a better option is by using the conditioning average node.
Area Conditioning
Sometimes you need to position objects spacially inside your image. The easiest way without using a ControlNet is with the area conditioning node. The syntax is very simple:
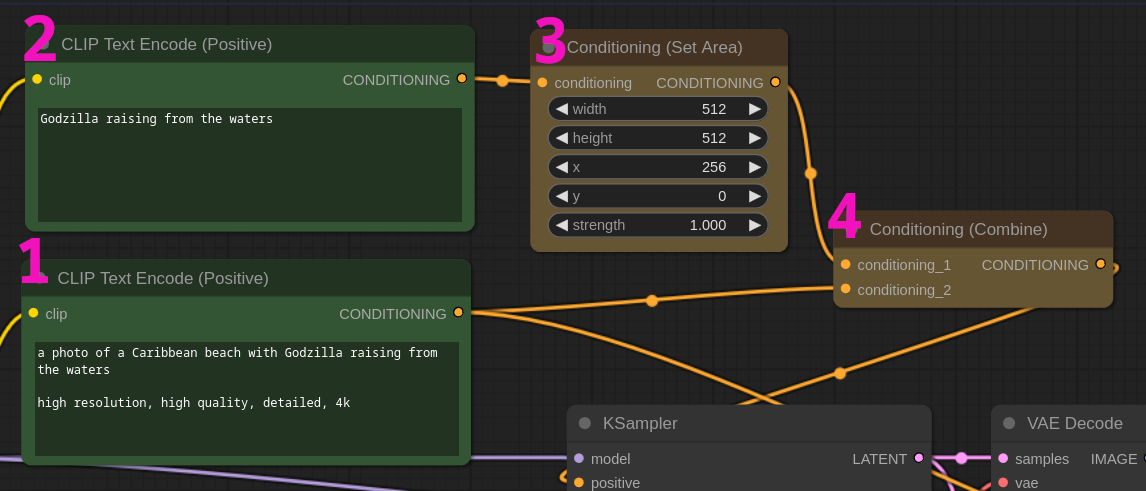
- Use a prompt to describe your scene
- Use a second prompt to describe the thing that you want to position
- Connect the second prompt to a conditioning area node and set the area size and position. In this example we have a 768x512 latent and we want "godzilla" to be on the far right. We set an area conditioning of 512x512 and push it to 256px on the X axis.
- Connect the scene prompt and the spacial conditioning with a Conditioning combine node.
All left to do is to send the conditioning combine to the KSampler positive prompt and wait for the magic to happen.
Of course you can use this technique to position multiple objects not just one like in this example.
👉 Note: the provided workflow does something a little different. It first sets two areas (one on the left and one on the right) and then apply a second pass on the whole image to make everything uniform. This the best way to make it work on SDXL.
Timestepping
ConditioningSetTimestepRange is a new node in ComfyUI and also one of the most powerful text conditioning tools we have.
The node lets you set a start/stop temporal position for each prompt. Let's say we have 20 steps, you can tell the sampler to start "painting" a cat for 5 steps (that are likely the most important) and then forget about the cat and start generating a dog for the remaining 15.
This is an incredibly effective way to mix prompts, possibly the one that grants the higher level of finetuning. Each prompt doesn't need to start where the previous ends, but they can also fade into each other so that in a few steps two concepts will merged.
In this workflow we try to generate an freckled African-American/Japanese woman. To do so we mix 3 concepts (freckels, Japanese, African-American) with different timing inside the denoise phase. The result is pretty impressive.

👉 Note: You can have multiple timestep nodes and each can start/stop at different timing but it is important that no timeframe is left unconditioned. Ie: if you have two prompts and the first ends at 0.5, the second should start anywhere between 0 and 0.5 but not at 0.6 otherwise you'll have some steps without conditioning.
典型工作流
典型工作流要整理扎实.
ComfyUI 官方示范 https://comfyanonymous.github.io/ComfyUI_examples/
- sdxl 的几个工作流, 效果很惊艳哇
工作流分享网站 https://comfyworkflows.com/
Civitai 也有不少工作流分享
反推
更快更小更精确,新反推模型Florence使用介绍_哔哩哔哩_bilibili
latent_batch
先批量出图, 然后 enable 放大节点再次点击就会只放大那一张, 好神奇的逻辑. 因为会把工作流中没有执行完的节点都完整执行完才会结束一轮. 比如在途中有节点报错了. 也不会直接退出, 修改好之后就可以接着执行
IPAdapter_canny
IP-Adapter精准风格迁移,新的权重类型precise style transfer,开发节点mad scientist_哔哩哔哩_bilibili
Tile controlNet Upscale
tile diffusion 的核心维护者已经离开了. 所以没有继续提供 sdxl 的 tile diffusion
xl_more_art-full / xl_real / Enhancer - xl_more_art-full-v1 | Stable Diffusion LoRA | Civitai
Stable Diffusion ComfyUI 基础教程(六)图片放大与细节修复_comfyui怎么用放大算法-CSDN博客
图片16倍超清放大工作流,极其激进的组合CCSR+SUPIR+UltimateSDUpscale_哔哩哔哩_bilibili
controlNet
【实测】SDXL的controlnet救星来了!效果媲美midjourney?_哔哩哔哩_bilibili
AnyTest多功能合一SDXL-ControlNet实测,五套工作流分享,重绘+类Tile+线类_哔哩哔哩_bilibili
模型对比
忘了SD3 Medium吧,这些模型效果更好!_哔哩哔哩_bilibili
直出2K大场景图像,极具创造力,Lumina Next的ComfyUI实现_哔哩哔哩_bilibili
像 webUI 一样使用 Sdxl comfyUI
我要把 sdxl 的基础工作流给搭建起来, 然后给每个选项加上开关, 做到可以像 webUI 一样使用 comfyUI
无限可能
只要参数是 text, 那么我是不是可以接入 llm, 让他输出的文本作为 prompt 输入?
只要参数是 image, 那么我是不是可以直接把 mj 节点接入进来?
FAQ
Custom Node Import Failed
现在最让我感到沮丧的就是 Sdxl 的使用太麻烦了
在 webUI 里完全没有办法正常使用, 出来的图都很垃圾
在 comfyUI 里使用起来也很困难, 除了官方的基础示例, 使用其他工作流完全出不了图
我只是想要一个 sdxl comfyUI 的, 支持 lineart, depth, ipadapter / revision 的工作流而已
现阶段有原创能力的 up 主根本就没有几个. 搜一搜 comfyui, 然后过一遍关注一下就齐活了. 和 obsidian 的环境差不多
Comfyui 最大的问题就是各种不同的实现太多了
需要一个非常灵活的对比方案, 可以快速选择不同的实现.
比如增强细节的 lora 就有一堆. 放大的方法也有一堆. 不知道哪个好, 实测下来, 哪个都不好
Comfyui 不会爆显存
[ComfyUI]显存够却报错?ComfyUI崩溃消失?我来给你解决方案。_哔哩哔哩_bilibili
cpu 都可以跑, 虚拟内存都可以跑
SDXL Comfyui
sd1.5 的生态直接舍弃了. 因为上限太低了
GitHub - sepro/SDXL-ComfyUI-workflows: A collection of my own ComfyUI workflows for working with SDXL 非常基础和实用的 sdxl 工作流. 可以作为学习的基础
comfyUI_ipadapter 的基础工作流: SDXL Lightning + IPAdapter plus
SDXL Workflow Templates for ComfyUI with ControlNet - v2.1 | Stable Diffusion Workflows | Civitai
SDXL Workflow for ComfyUI with Multi-ControlNet - v1.0 | Stable Diffusion Workflows | Civitai
原版的 comfyUI ipadatper 节点, 但是好像都是 sd1.5 的. 没有仔细看. 里面还有一个 comfy ui 的理解教程. GitHub - cubiq/ComfyUI_IPAdapter_plus
我现在需要的就是一个 multiControlNet + 风格迁移 + 高清细节的工作流
ComfyUI 16 Controlnet + IPAdapter Workflow (free download) - YouTube
Practice
The SDXL base checkpoint can be used like any regular checkpoint in ComfyUI. The only important thing is that for optimal performance the resolution should be set to 1024x1024 or other resolutions with the same amount of pixels but a different aspect ratio. For example: 896x1152 or 1536x640 are good resolutions.
SDXL 基本检查点可以像 ComfyUI 中的任何常规检查点一样使用。唯一重要的是,为了获得最佳性能,分辨率应设置为 1024x1024 或具有相同像素数但不同宽高比的其他分辨率。例如:896x1152 或 1536x640 都是不错的分辨率。
16:9 = 1365* 768
- 5460 * 3072
- 2730 * 1536
优质的参考图也是出图的关键. 需要有一个优秀的图库
Prompt
Juggernaut XL - V9+RDPhoto2-Lightning_4S | Stable Diffusion Checkpoint | Civitai
参考主宰 xl, cfg 要低, 才会真实
目前工作流的必备模型
ByteDance/SDXL-Lightning at main
stabilityai/stable-diffusion-xl-refiner-1.0 at main