stable-diffusion-animation
已经过时的动画处理
图生图批量处理
Mov2Mov
23 年 7 月之前就已经有了. 已经不怎么维护了. 毕竟只是脚本级别的东西
主要是用作转绘. 对于视频的每一帧做图生图. 图生图批量处理就是转绘的基础形态了
提示词不能描述的太仔细, 因为会对每一张图都生效.

调整好风格之后, 固定随机种子
EbSynth 插件结合 EbSynth 工作流
10倍效率,打造无闪烁丝滑AI动画!EbSynth插件全流程操作解析与原理分析,超智能的“补帧”动画制作揭秘!| Stable Diffusion扩展插件教程_哔哩哔哩_bilibili
Deforum
特点
23 年 6-7 月份出现的. 场景很特定, 就是做瞬息宇宙的效果
都支持 controlNet
只是 AnimaeDiff 镜头控制需要厍模型,Deforum 不需要,直接调参数,Deforum 可以控制 Z 值。
目前火的瞬息全宇宙效果用 Deforum,因为更多的丝滑和患象空间,更过的控制参數,镜头更多的控制。
可以一张图片自接进入一个光怪陆离的世界,转成一个字。
而 AnimaeDiff 更多的是保持统一一性,转成很丝滑,但是风格或者人物保持统一,说白了,提示词和下一个提示词自接,发挥想象的空间比较少
一种风格化的视频创作工具, 而非是稳定的生视频.
显存要求低. 随便跑的
基本使用
基本参数都不用改. 直接去提示词区域输入一下 prompt travel 就可以了
提示词
{
"0": "A cup of coffee steaming on the table",
"30": "A small boat was ailing on the stormy sea",
"60": "A snowy mountain with aurora in the skys"
}
数字代表了从多少帧开始生效, 下一行开头的帧数结束. 上面的 prompt travel 就是每 30 帧切换一个画面.
下方的正反提示词会对每一帧生效. 如果要针对特定的时间写提示词可以在后面加上 --neg 参数
关键帧
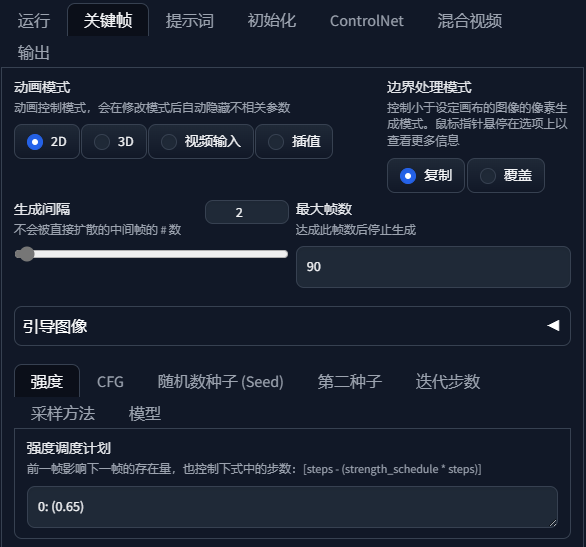
生成间隔
太低了闪动会很频繁, 太高了会有迟滞感. 一般就是 2 或者 3. 搭配补帧功能做帧插值, 就可以兼顾生成速度与流畅性了
强度
上一帧影响下一帧的强度. 锁定画面的强度, 如果追求画面的连续流畅, 可以尝试 0.7 - 0.8 的高强度. 如果追求迷幻, 多样就设置 0.3 - 0.5 的低强度
运动
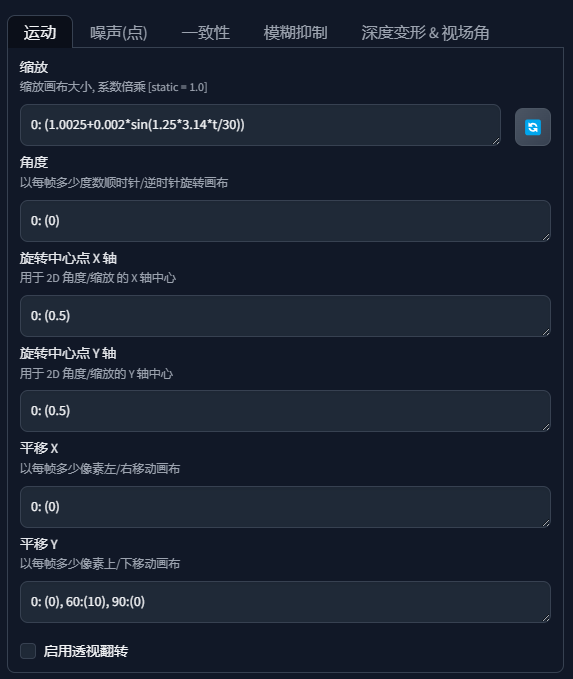
最核心的参数, 直接管理了运镜的过程
defurom 里的动画模式分为 4 种, 2d 和 3d 都是可以设置镜头运动的
如果是 3d 的视频, 就会多出一个 z 轴, 用来控制画面的前后移动. 表现就像是 2d 画面的缩放一样
视频的 xyz 是相对于屏幕而言的. 以前的 2d 画面自然就是屏幕的 x 和 y. 而 z 是 3d 才有的, 就像是往屏幕里面走和往屏幕外面走一样.
分段控制
前面的 0 序号就对应着 prompt travel 里的动画帧
所有的参数都可以使用关键帧的形式做控制
前半段用一个模型, 后半段则用另一个
使用变量 T 定义随时间转换的参数
t 代表这当前帧
引导图像关键帧
初始化
图片初始化
图片初始化, 上传一张图片作为演化的第一帧.
在视频软件里做一下反转就可以定义成最后一帧了.
采用了色彩一致性算法, 来保证后面的生成画面不会有太大的跳跃感.
蒙版初始化
可以设定一个人物蒙版, 然后只变化背景, 实现超体的视频效果
视频初始化
转绘 & deforum 风格化视频
AnimeDiff
GitHub - guoyww/AnimateDiff: Official implementation of AnimateDiff.
真正想要生视频, 还是要抓住关键帧. AnimateDiff 针对视频片段做训练, 让 ai 学习不同事物做运动的方式, 训练出了运动模块. 让我们可以把一系列运动的帧一次性画出来
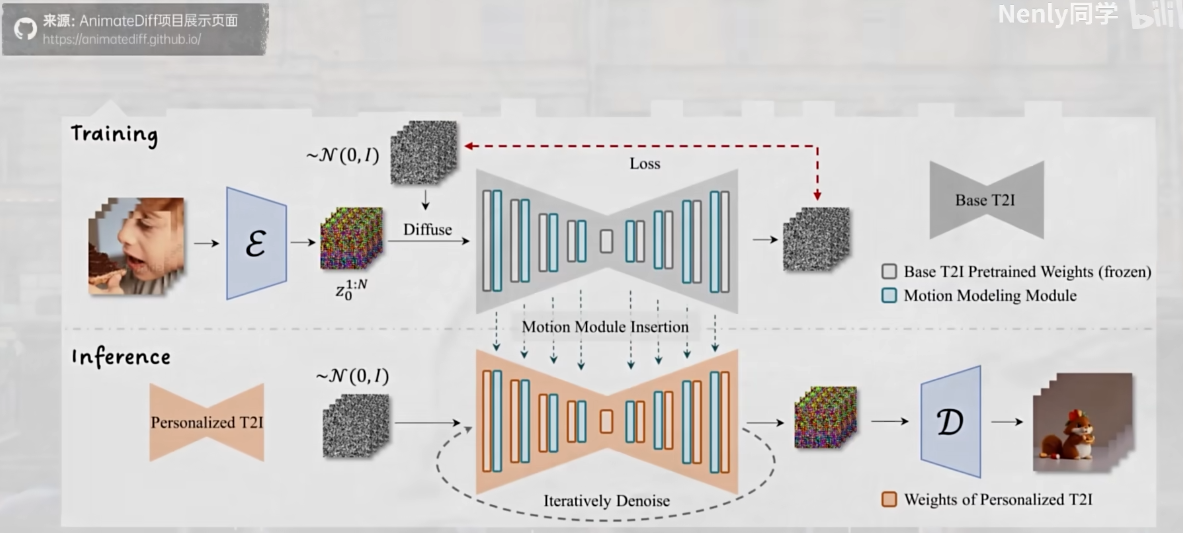
运动模块是独立于大模型的. 可以附加到任意一个大模型身上.
基本使用

使用 webUI 里的扩展需要 12 GB 显存.对于 N 卡用户而言, 开启 xFormers 后能显著优化显存占用, 最低只需要 5 GB 就可以畅玩了
下载官网的几个 v3 的模型
在设置里开启几个优化选项
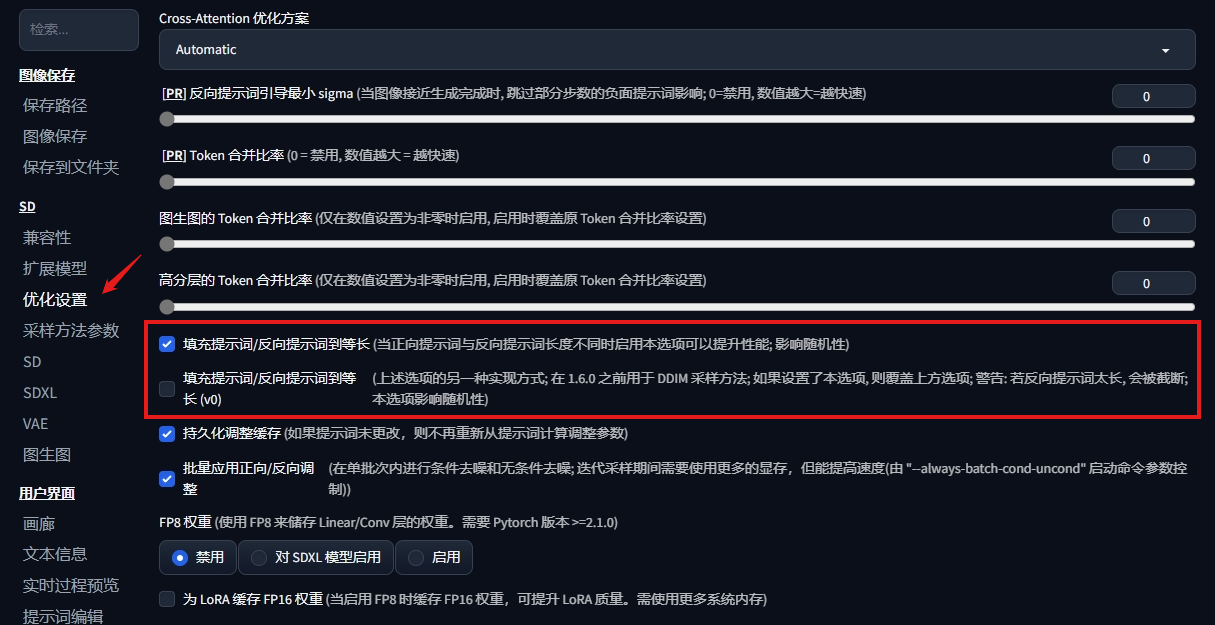
最新版本扩展没有找到 xformers 的选项
设置完, 记得保存设置并重启 UI
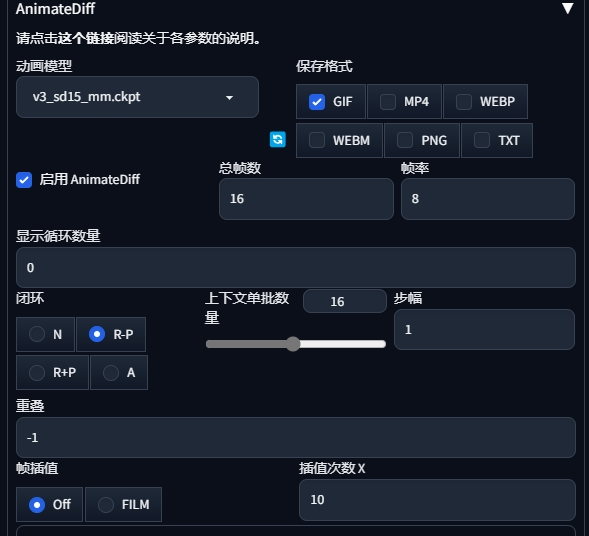
animateDiff 的开发者针对 SD1.5 训练过三代模型, 一般就是用 v3
参数详解
上下文单批数量
最影响绘制效果的参数. 运动模块的作用原理是一次性将多张连续的画面输入进去绘制. 输入数量的多少就是由该参数决定
会显著的影响动画流畅度. 因为只有同一批次里的运动关联是最稳固的
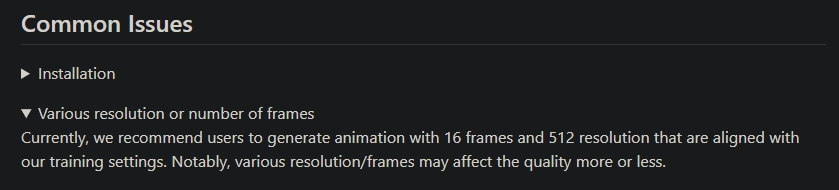
因此这个数不超过 16 帧是最好的. 将单批数量削减到 8, 可以再额外节约 1G 左右的显存
闭环
越靠后的选项, 循环越死, 播放观感越自然连贯

设置了循环之后, 步幅和重叠会对动画效果造成一定影响, 反正用默认数值才是最流畅的
视频时长
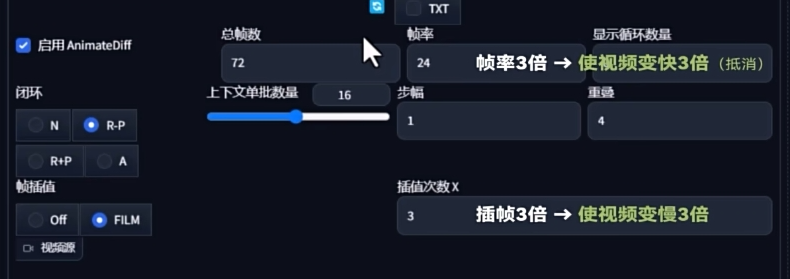
默认的帧率 8 不变, 帧数 / 帧率 = 时间. 因此生成一个 2s 的视频, 帧数是 16, 一个 5s 的视频帧数是 40
帧率
不宜直接提高, 会增加显卡负担和闪烁概率. 用点补帧手段就行
图生视频
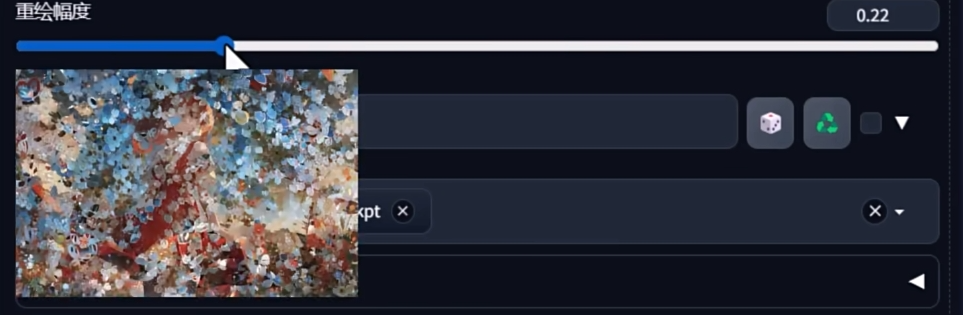
最佳实践的参数都和文生图差不多. 但是重绘幅度不能太低, 推荐在默认值 0.75 之上
然后再增加一些描绘画面特征的 prompt, 特别是涉及到运动和变化的
fluttering skirts, flying petals,

Latend Power 和 Latend Scale
导入的图像会经过一次图生图再给 animateDiff 做动画. 而且越到后面会变得越不像原图, 因为 animateDiff 会不断往图里添加噪声然后扩散了促成运动.
但是重绘幅度也不能降得太低, 当重绘幅度低于 0.6 时会出现雪花点, 影响观感
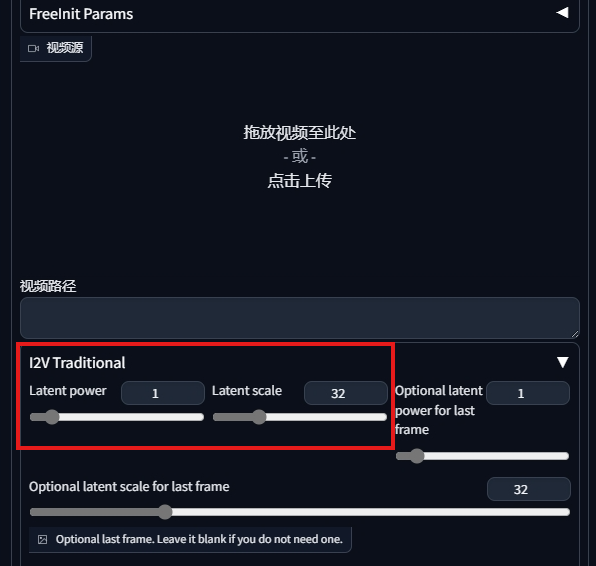
使用图生图中这两个参数可以控制基于原图的变化幅度.
从实践上来说, power 越小, scale 越大, 动画基于原图演化的幅度就会越小. 因为它对图像的影响和时间 (帧数) 相关, 而且是指数型的. 因此调整的幅度要相对谨慎. 如果希望动画和原图更像, 可以这样设置:
- 重绘幅度降低到 0.6 - 0.7
- power 降低到 0.8 - 0.9 , scale 提高到 48 - 64.
- 设置总帧数不超过 16
但是这样运动的幅度就会很小
视频生视频
推荐在文生图的过程中使用它. 图生图生视频互相影响. 效果不太好
搭配 controlNet 使用来控制人物动作, 像往常画单张图一样即可
和传统的逐帧转绘有点像, 但是 animateDiff 的特性会让动画更加连贯, 可以做到基本消除闪烁感

直接使用骨骼图视频即可
直接使用处理完的骨骼图视频
openpose 预处理图序列帧视频, 帧数 8 -12 帧即可
AI动画:Stable Diffusion X AnimateDiff 的终极奥义_哔哩哔哩_bilibili
通过 animateDiff 做拆帧处理
通过批量处理来生成单帧的转绘, 只是利用了 animateDiff 所以效果会更好
直接开一个 Tile 模型做风格转换就行了
Prompt-tarvel

实现人物从睁眼到闭眼
best quality, masterpiece, 1girl, upper body, detailed face, looking at viewer, outdoors, upper body, standing, outdoors,
0: (spring:1.2), cherry blossoms, falling petals, pink theme,
16: (summer:1.2), sun flowers, hot summer, green theme,
32: (autumn:1.2), falling leaves, maple leaf, yellow trees, orange theme,
48: (winter:1.2), snowing, snowflakes, white theme,

搭配 Lora 使用
V2 运动 Lora
用于控制运动

V3 Adapter Lora

一般都可以加上, 摸索一下权重, 权重越高, 运动的多样性就会降低
Animate Diff 转绘工作流
不换背景
小钱的工作流
给视频单独做了一个工作流, 前期的预处理, 把视频的 opense, depth, mask 全都单独处理到不同的文件夹内了
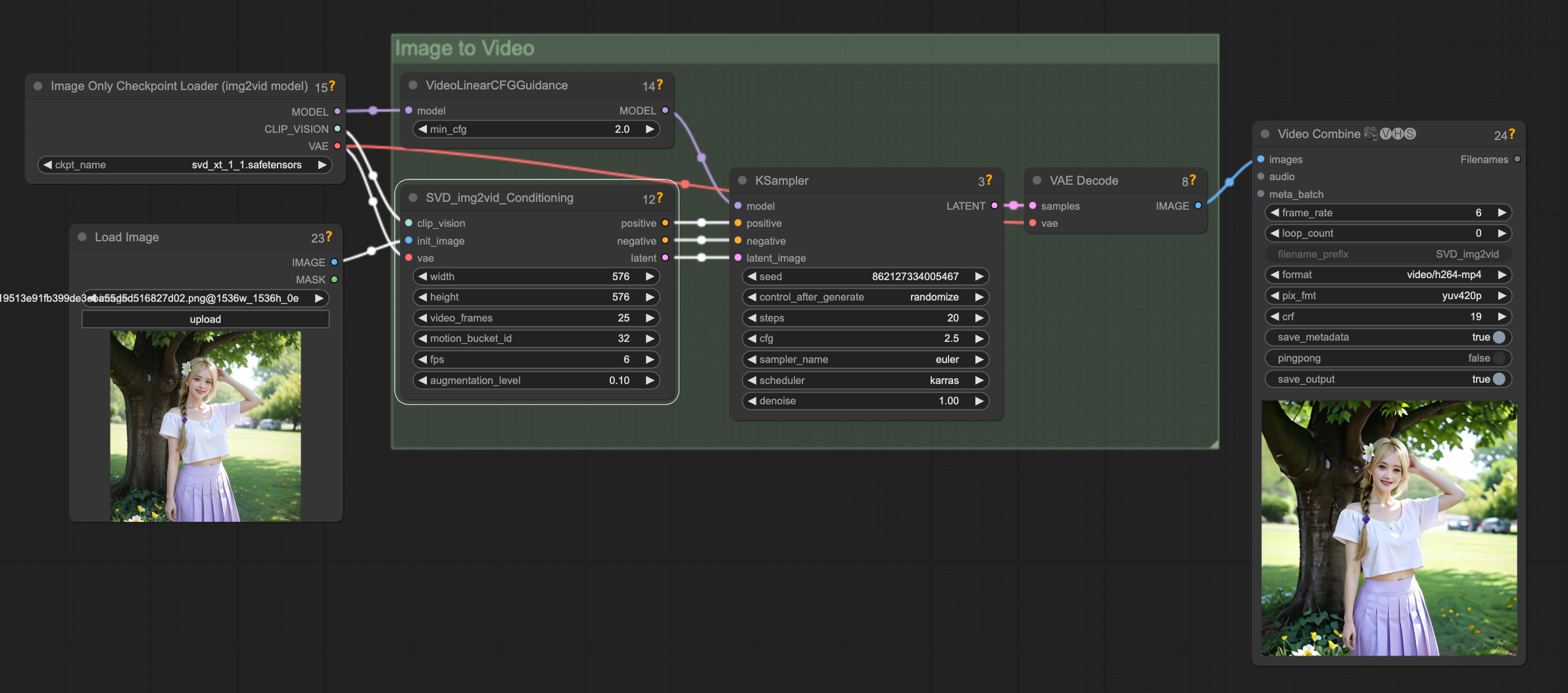
SVD
重视视角的重要性,才能生成效果炸裂的svd视频。The importance of perspective for SVD 1.1 - YouTube
显存要求太高啦. 基本上需要 16 GB. 本地跑不动. 只能用 esheep 白嫖一些了. 不然就只能等以后云部署熟练了再尝试了
Stable Video | Generate Videos with AI svd 官网每天白嫖
不可控
--- start-multi-column: ID_47r7
Number of Columns: 2
Largest Column: standard

--- column-break ---
--- end-multi-column
配置要求
绘制 14 帧的视频显存需求在 12 GB 左右. 想要生成 25 帧的视频, 显存要求就更高了
基本上本地玩需要 16 GB 显卡
原理
给 ai 大量投喂视频片段, 让 ai 学习这些视频在不同时间节点上的静态帧的差异, 让动态在 ai 眼里有迹可循. 让 ai 有能力去预测这张静态的图片在接下来的时间里会发生的运动
图生视频
是 SVD 最基本的操作. 让图片动起来
初始图片的尺寸比例最好和最后生成的视频的比例保持一致
视频尺寸默认的 1024 * 576 是 SVD 训练素材的尺寸
视频参数
motion_bucket_id
最直观的控制视频运动幅度的参数, 默认 127. 取值从 1 到 255.
如果运动幅度过大导致画面变形了, 可以考虑降低运动桶 id 的值
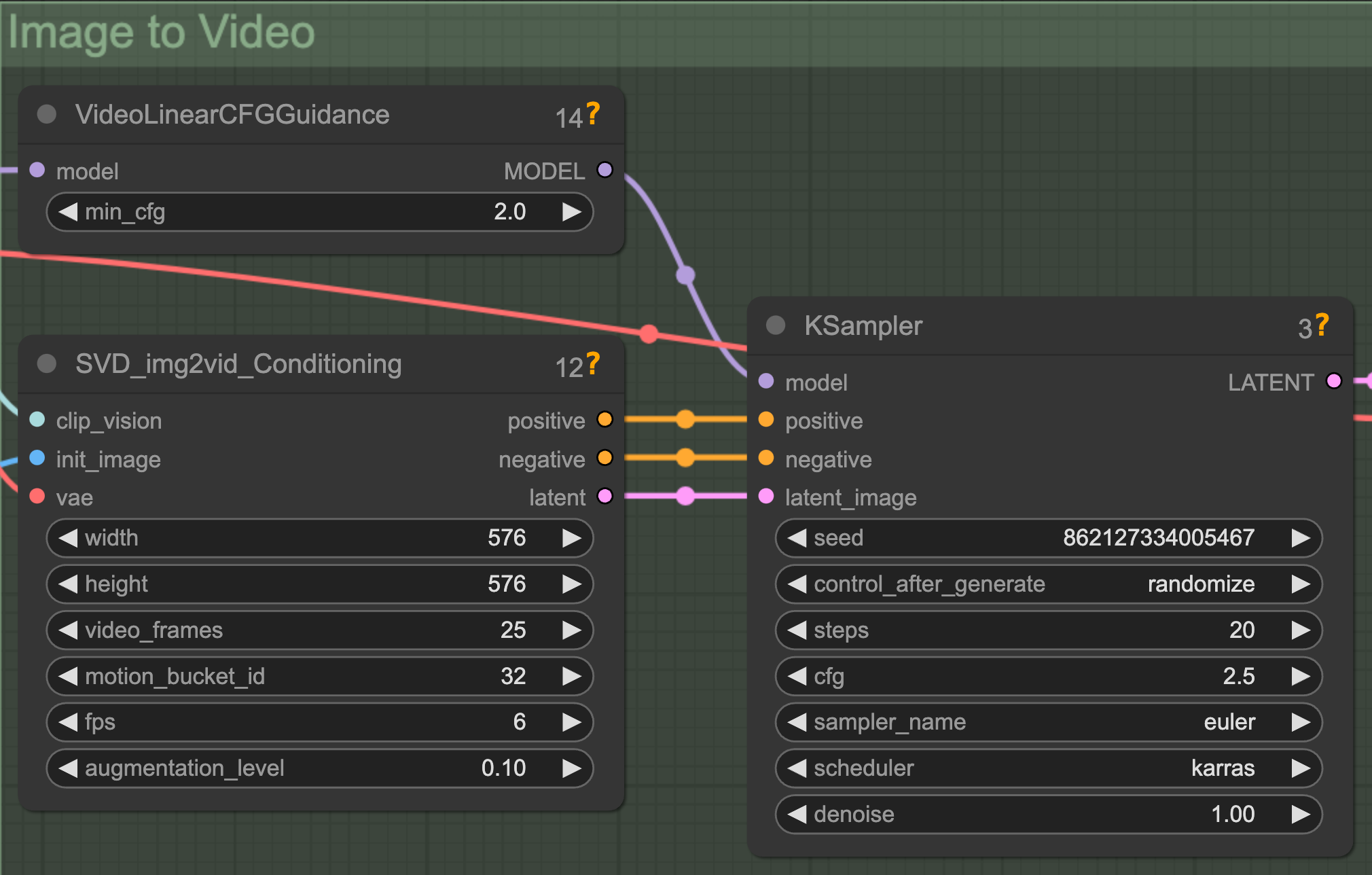
Cfg
classifier free guidance
和运动幅度间接相关的一个参数.
有一个 min_cfg 和一个在 KSampler 里的 cfg, 是因为 SVD 采用了随帧数动态控制 CFG 的思路.
在绘制第一帧的时候应用最小值, 然后逐渐增大, 到最后一帧时变成最终的 cfg 数值
官方解释作用是保持原始图像的忠实程度, 低了画面会更自由, 高了画面会更稳定.
nenly 实践发现 CFG 不会影响运动的构成, 但是会影响细节. 如果发现画面糊成一团, 可以适当增大 cfg 的数值. min_cfg 和 最终 cfg 都可以增大试试, 抽抽卡
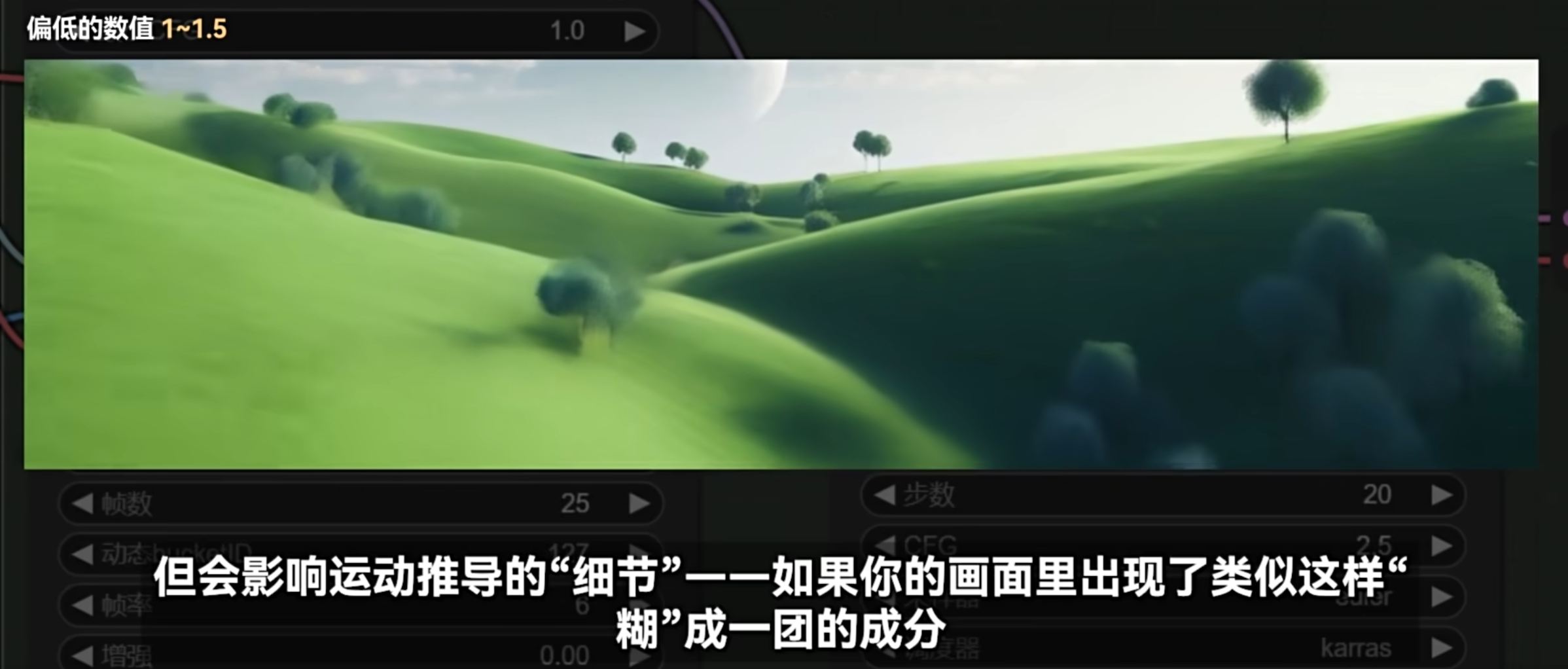
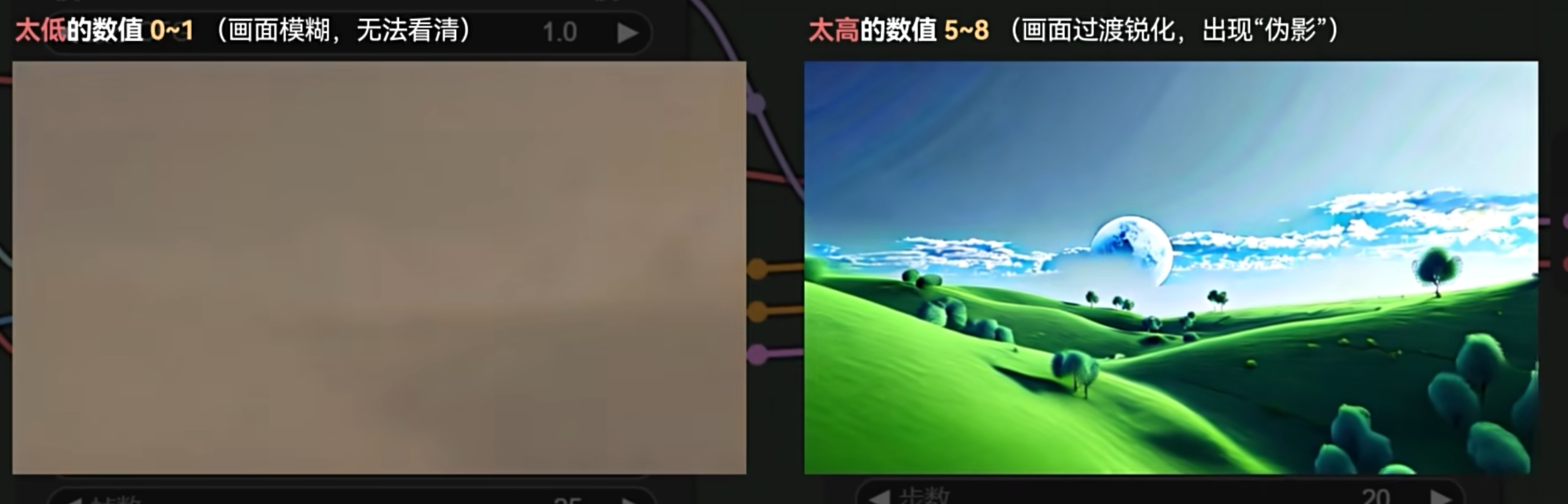
数值相比静态图片的 CFG 7 要低很多. 算是一种实践吧, 太高了生成视频会有很多伪影
尽量还是维持在正常的区间. 比如默认值的区间
augmentation_level
噪声增强水平, 添加到图片中的噪声量, 它越高, 视频与初始帧的差异就越大, 可以通过增加该值来获得更多的运动.
该参数对数值的调整很敏感, unit 0.01. 一般不会超过 1.
但是当生成的视频尺寸与标准训练尺寸不同的时候, 可以尝试增大到 0.2 ~ 0.3 来避免视频错乱
文生图生视频 = 文生视频
结合蒙版指定运动区域
运动笔刷, 动态笔刷
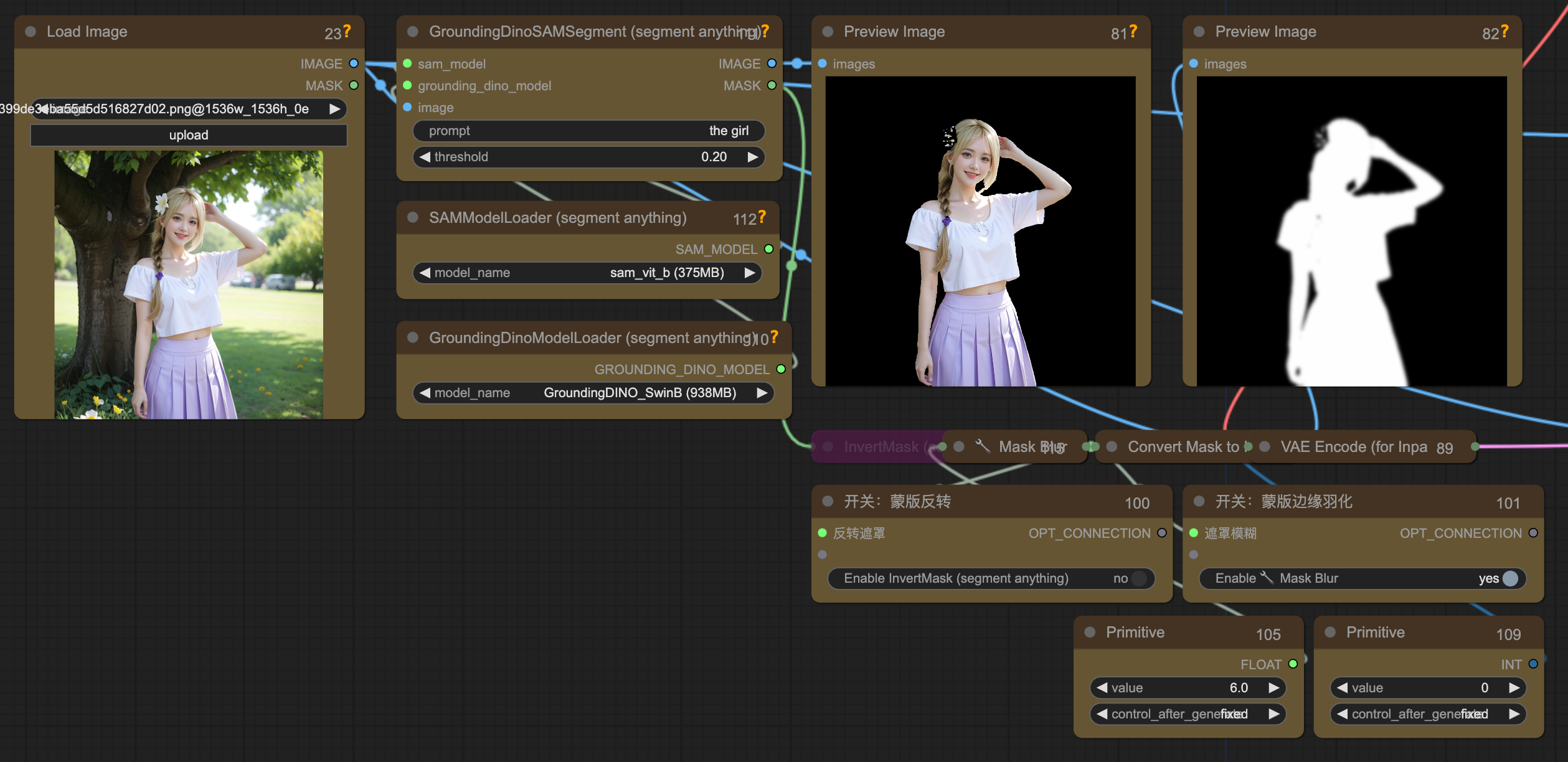
利用 prompt 智能选区物体创建蒙版, 然后对蒙版区域进行运动指令. 如果扣取的区域太小, 是不会有动态效果的. 而如果扣取的是人像, 则因为区域限得太死, 导致一些奇怪的运动. 需要降低几个运动参数的幅度再反复抽卡试试
缺点
可控性太差 - 结合蒙版
现阶段无法控制 SVD 生成的视频是如何运动
生成的视频帧率和分辨率都一般. 帧率默认只有 6, 最佳尺寸只有 1024 * 576 - 结合补帧放大工作流
纯靠抽卡, 比较适合一些物件的运镜视频, 或者变化幅度不大的人像
抽卡技巧
当我们的画面里有比较突出的人物主体, 比较显著的动态元素乃至比较有空间层次感的场景时, 产出自然流畅的运动的概率就会高很多.
生成一些静物, 远景, 出好卡的概率更高.
细致的动作就不太行
FAQ
SVD 和 animeDiff 哪个好?
几乎是同一时间出现的. 支持的能力也有差异. 与其分个高低, 不如都试试, 探索合适的场景, 甚至是互相搭配使用, 取长补短
时尚潮流的新品
toonCrafter
muse pose 自动提取 open pose 视频动作帧: AI视频动画S2:Comfyui-MusePose Comfy工作流 动作驱动图片视频 Animateanyone升级开源_哔哩哔哩_bilibili