stable-diffusion-term
Diffusion 原理
最基础的原理: 扩散. stable diffusion, 也就是稳定的扩散
学习, 转化, 去噪的过程
眼睛一睁一闭之间, 完成了转化和去噪
市面上的图像生成模型, 基本都是在使用类似的原理来生成图像. 2023-04

图生图就是参考图的扩散和去噪, 文生图就是从模型训练的图片里找到符合 prompt 的进行扩散和去噪. 其实本质都是图生图
有点像看到一个曼妙的背影, 你会想起无数过往的女人. 但是最终扩散形成的可以是任意一个, 但是只能是一个
SD 会经由随机种子生成一张随机噪声图,然后利用训练好的”噪声预测器“(U-Net),结合输入的提示词等条件(Conditioning),进行“条件去噪”,在这张噪声图上不断添加一些形象,使之成为一张生成的新图片。
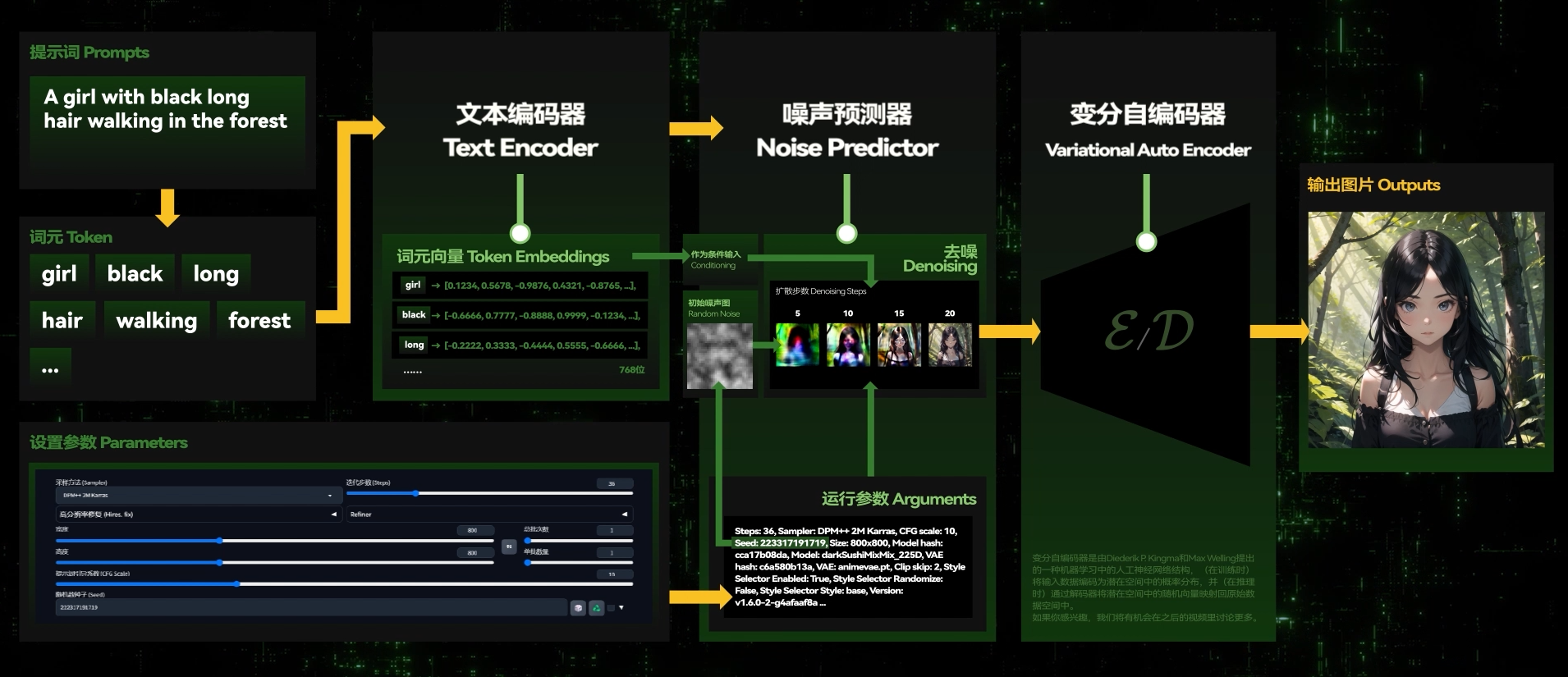
在生成图像的过程中,SD 会先在潜变量空间中生成完全随机的噪声。随后,噪声预测器会估计图像中的预测噪声,然后从图像中减去将预测出的噪声。
重复这个过程最终即可获得越来越清晰的图像。去噪的整个过程,被称为采样。
采样过程属于 SD 模型的一部分,其中采样过程中采用的方法,就叫做 sampler,采样器**。**
U-Net
lora 和 controlNet 都是在对 U-Net 做操作
tensorRT 也是
准备素材
在后期处理里面, 有很多为了准备素材而添加的快捷操作, 可以使用
B站第一套系统的AI绘画模型训练课程!零基础入门“炼丹”,制作属于你的SD模型!模型微调(Dreambooth、LoRA、Embedding)原理分析教学_哔哩哔哩_bilibili
大模型
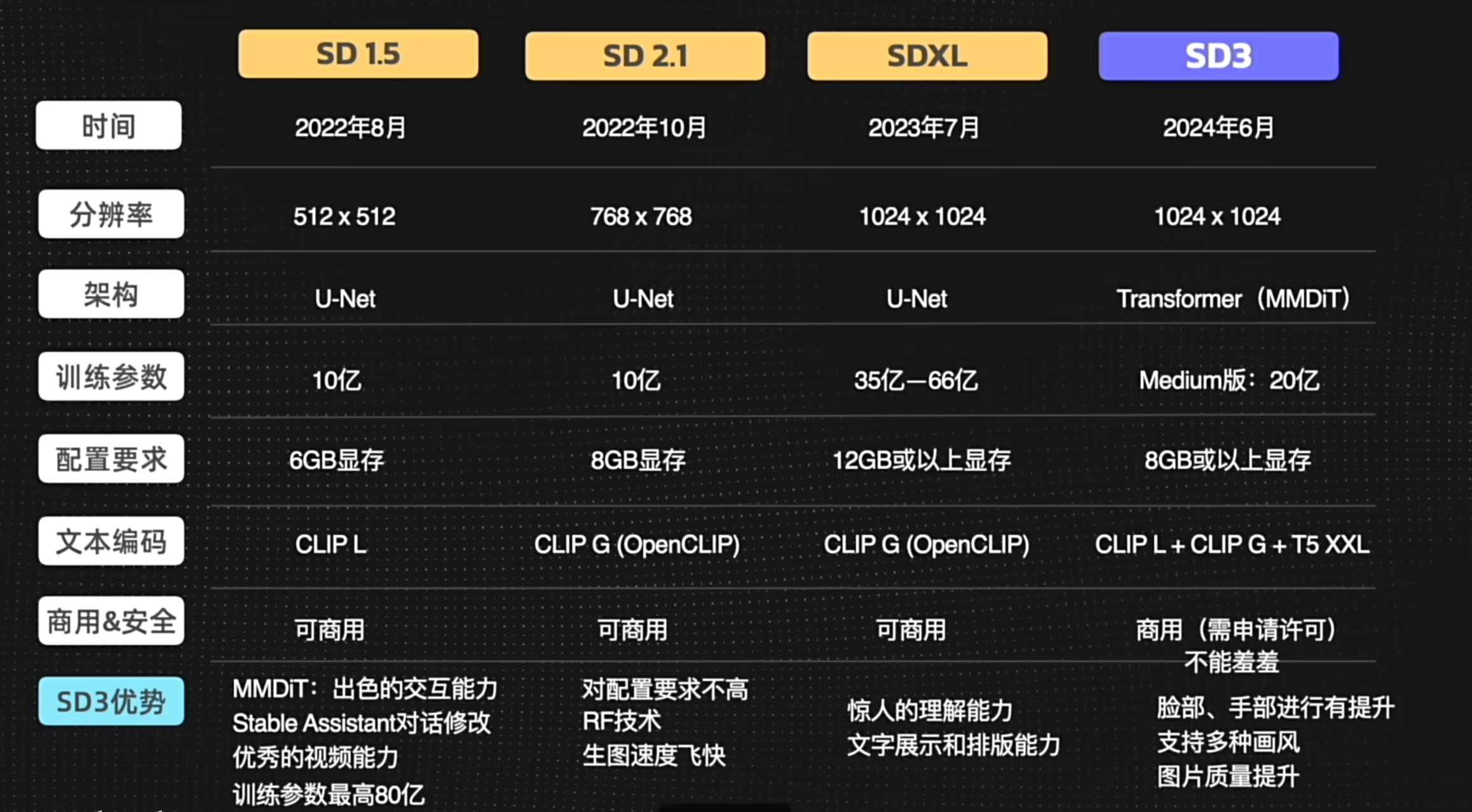
sd 的大模型分为了三代, v1, v2, sdxl.
sdxl 对标 midjourney 的全能大模型, 但是细节还是差很多
模型的作用
存储了大量的学习信息, 把图片给模型学习的过程叫做喂图.
如果喂给模型的图片都是二次元的, 那么无论是让模型画人物还是画风景都会是二次元的
这也代表着, 画风不是光靠 prompt 可以决定的
模型的存放位置
D:\stable diffusion\sd-webui-aki-v4.7\models\Stable-diffusion
这类模型又被称作 check point. 一个大的模型, 训练起来是很消耗算力的, 运算到关键位置的时候, 就会在一个关键点创建一个 checkPoint 保存已经运算的部分
正是基于这种 checkpoint 的特性, 大部分的模型都拥有不断的往下迭代和更新的能力
常规的后缀名: .ckpt, .safetensors
.safetensors 较小是因为剪枝, 量化处理过, 不允许运行脚本, 更安全
Sdxl
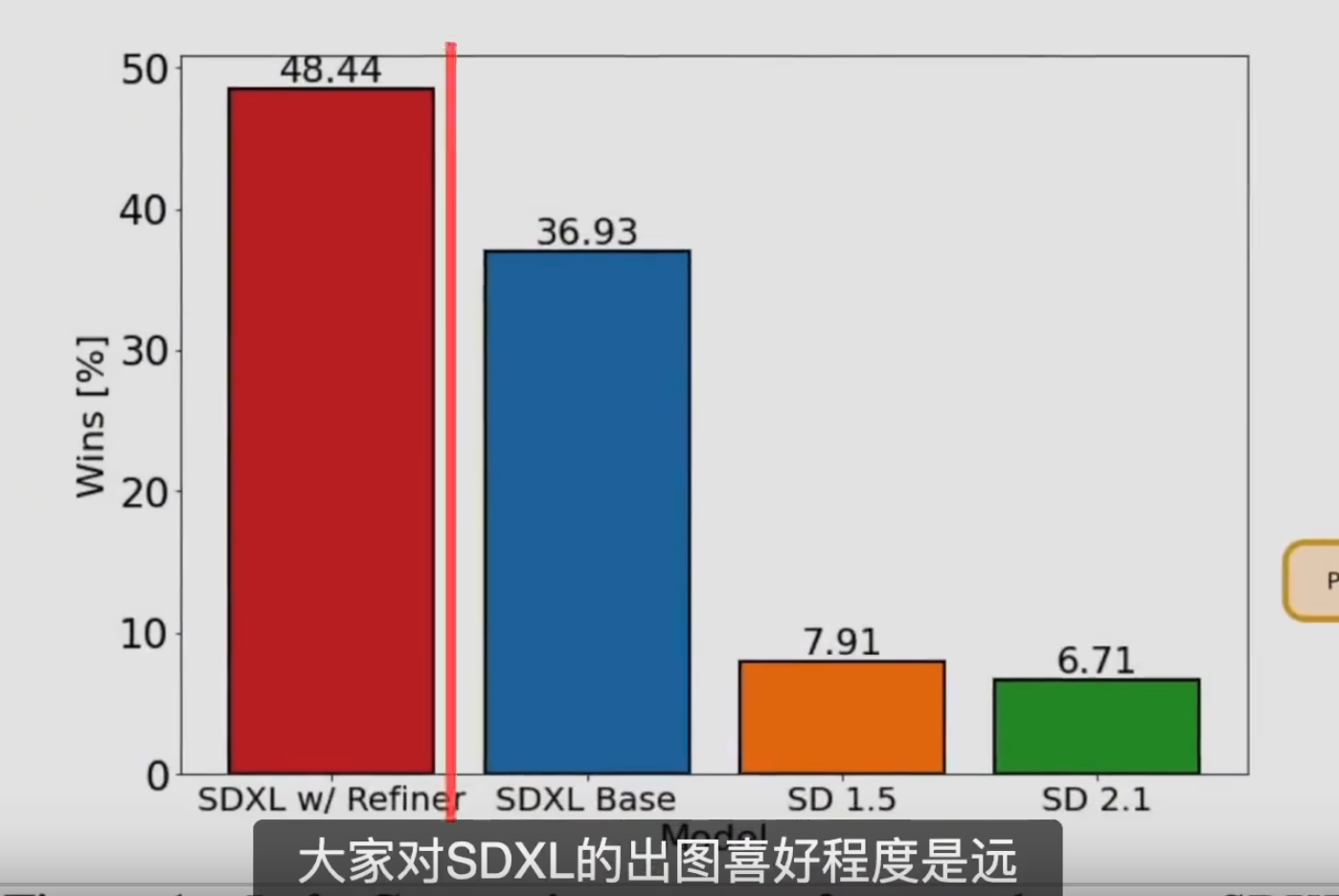

特点
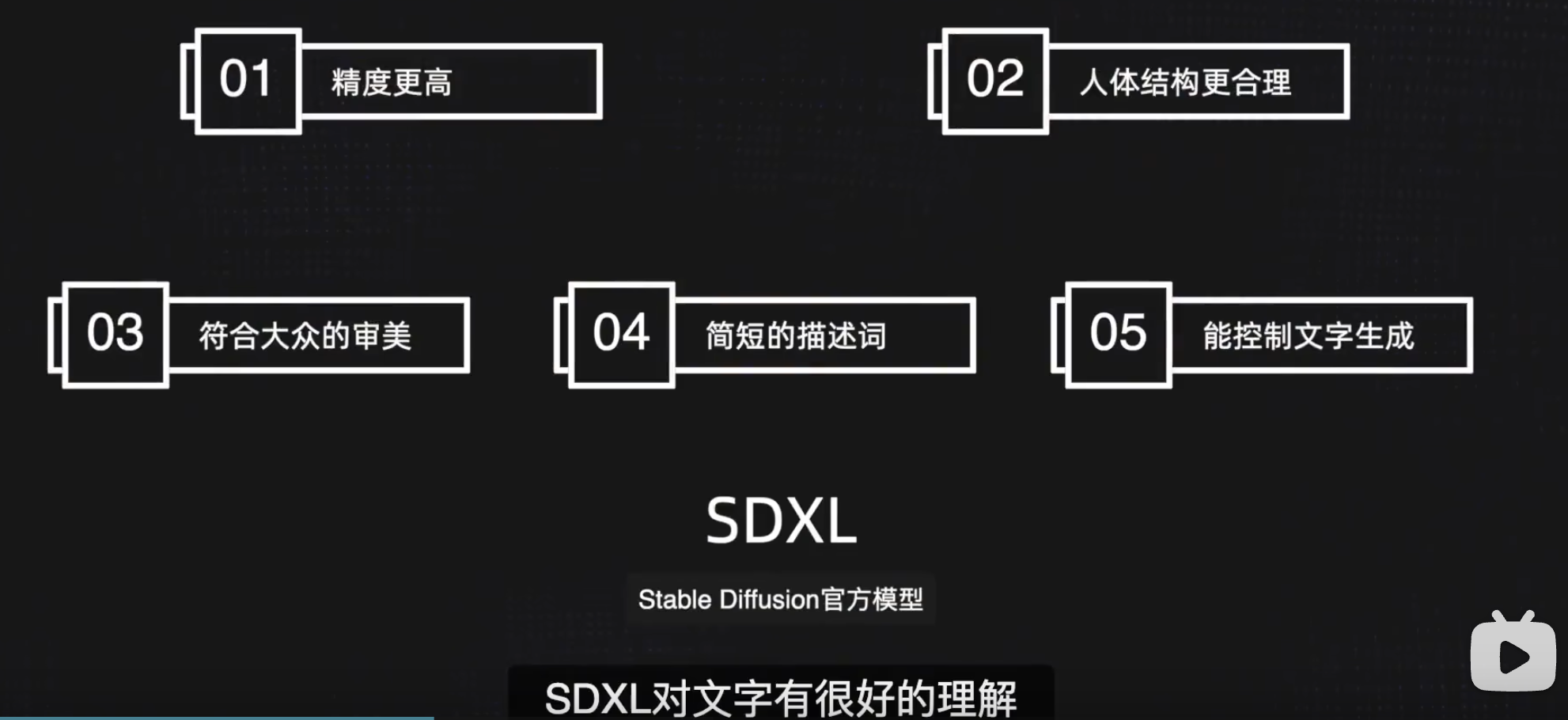
更好的识别自然语言, 更短的 prompt
使用了更大的分辨率的图片做训练, 基础训练 1024 像素
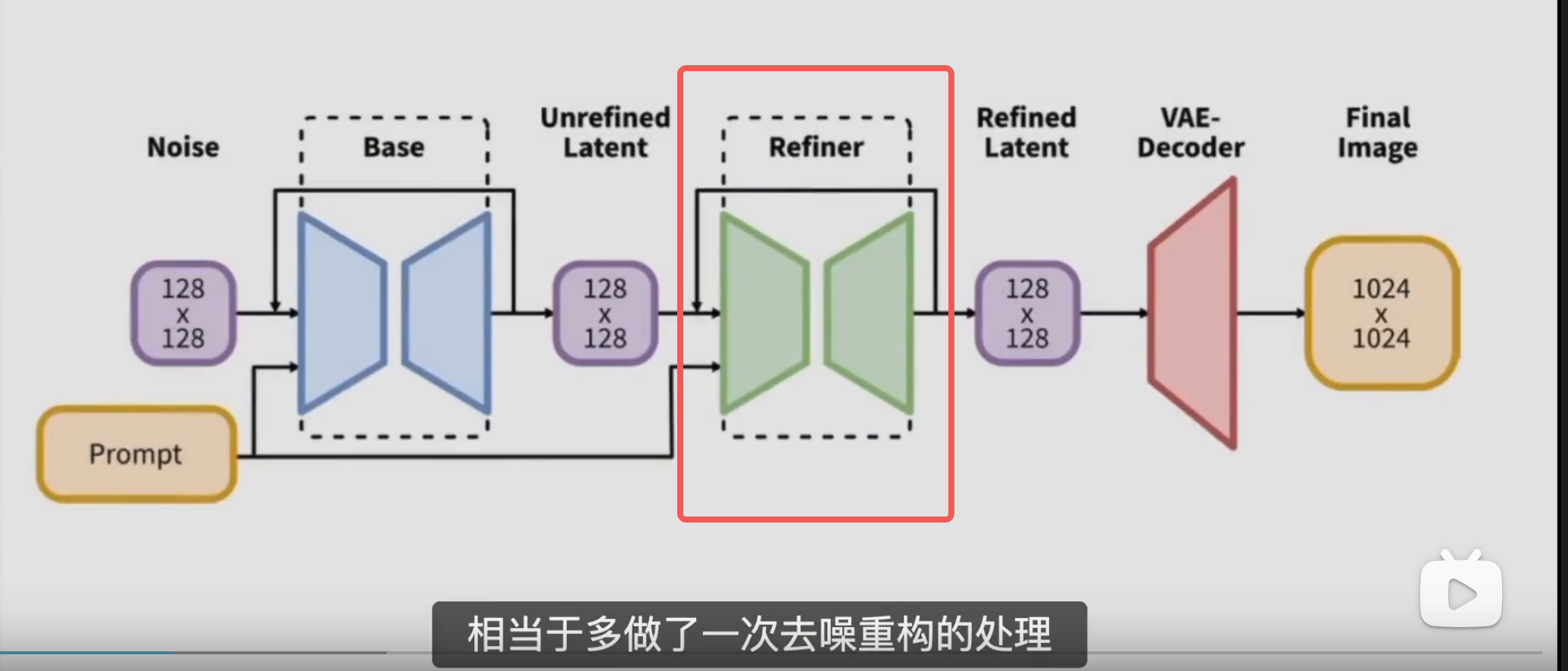
有更多的细节. refiner 优化器
生成文字更加准确
通过提示词切换不同的风格的, 不用搭配 lora
意义更大与作用本身
底模的更新, 会让已经学习的一些更简单, 效果更好, 而不是让学习白费. 因为 controlNet 所解决的问题确实是提示词无法精确控制的
降低显存压力
AI绘画的“显存杀手”?5块全新40系显卡怒测“最强开源大模型”——Stable Diffusion XL效率测试&使用技巧,SDXL低显存Web UI优化指南_哔哩哔哩_bilibili
家用机显卡的水平还是不够. 现阶段云显卡或许才是最经济的方案. 因为以后的显卡一定会在 ai 算力方面继续加强.
风格选择扩展 + 自动 Refiner 扩展
需要搭配 refiner 使用. 需要先使用 sdxl 出图, 然后到图生图使用 refiner 再出图, 重绘幅度 0.5
refiner 有点类似于高清修复, 会识别出需要细节处理的部分. 额外进行加噪去噪, 来获取更高清的结果
还需要等等 controlNet
style selector, 切换内置的画风, 减少 lora 的使用
如何升级到 Sdxl
与旧 Lora 不通用.
webUI 版本和插件版本直接在秋月启动器一键更新即可
Sdxl Turbo 模型
已开源. 1 步采样, 但是最佳分辨率是 512 512
SD3
【Zho】sd3_medium 分别使用不同文本编码器的对比:
1)+ t5xxl
2)+ clip_l + clip_g
3)+ clip_l + clip_g + t5xxl
在属性匹配和文字上,T5XXL 还是非常关键的,在语义理解上三种其实差不太多(当然加了 t5xxl 还是会好一些),这和论文的结论基本一致
日常使用建议:由于 t5xxl 比较大,所以对属性匹配和文字无要求的情况可以不使用 t5xxl,建议找到一个算力和效果的平衡点
采样器
进行图像生成的时候, 使用的某种特定的算法
只有少数采样器值得使用.
第4节:stable diffusion采样器教程详细介绍_哔哩哔哩_bilibili
采样器的演进
老派采样器
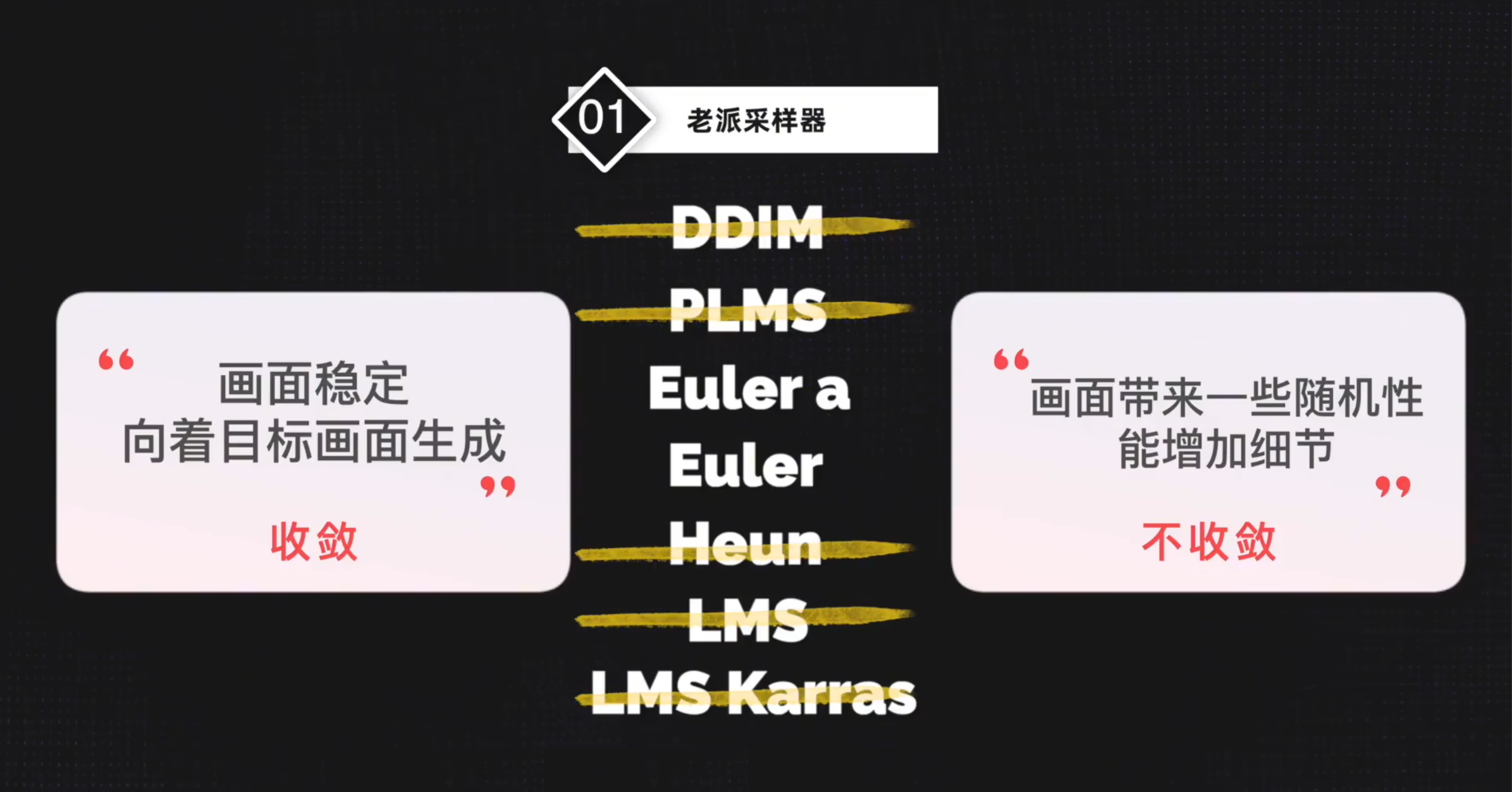
A 标识的含义
a 代表祖先采样器, ancestor, 不收 敛
2022 年发布的 DPM 算法
DPM2
画面有提升, 但是时间翻倍. 可以用一代算法加上更多的 step 来代替
Karras
改进. 在第 8 步之后躁点更少
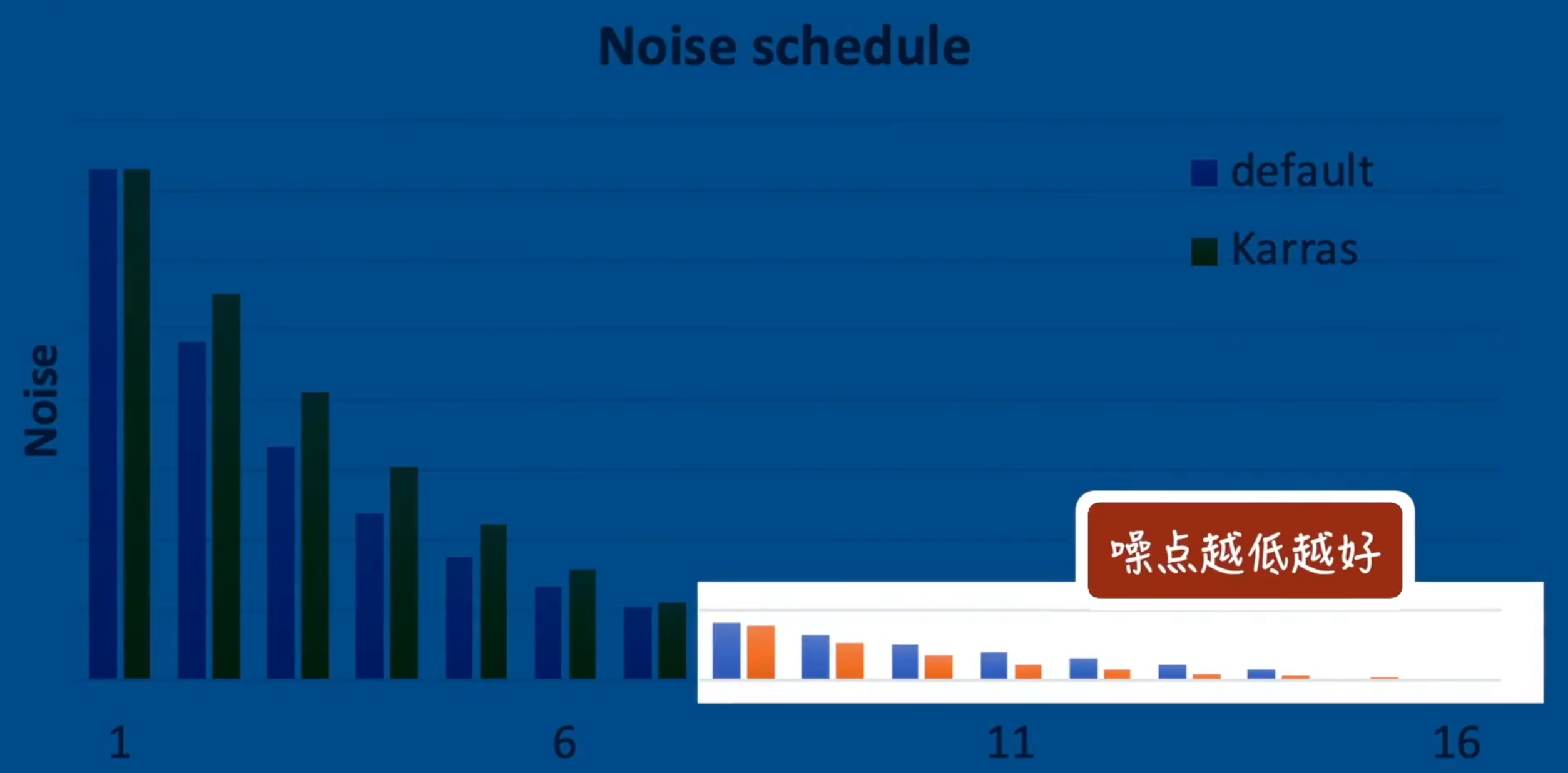
2S / 2M
S 代表单步算法
M 代表多步算法, M 是 S 的升级版本
推荐的采样算法

DPM++SDE Karras 可以很好的生成高逼真度的图像. 一般在渲染真实系图片, 追求画质的时候会用这个
Exponential 1.6 版本新增的算法
3M 也是 1.6 版本新增的, 需要更多的采样采样部署, 适当调低一点点 CFG 会有更好的效果

2023 年新推出的采样器


LCM
【AI绘画】LCM 教程: 超级加速、1秒出图!小显卡的福音 LCM LoRA、采样器 安装使用教程_哔哩哔哩_bilibili
23 年底, 有个大佬提出了 lcm 的大模型和 lcm 采样器. 以及相应的 lcm lora. 但是现在基本只用 lcm 采样器和 lcm lora 了
生成速度非常快, 可以用很少的步数就完成采样去噪, 2-8 步.
lcm lora 可以适配任意的模型来做加速
TCD
LCM 适用于 1.5 模型. TCD 适用于 SDXL 模型. 有需要的时候再学习吧
Sampler 和 Scheduler
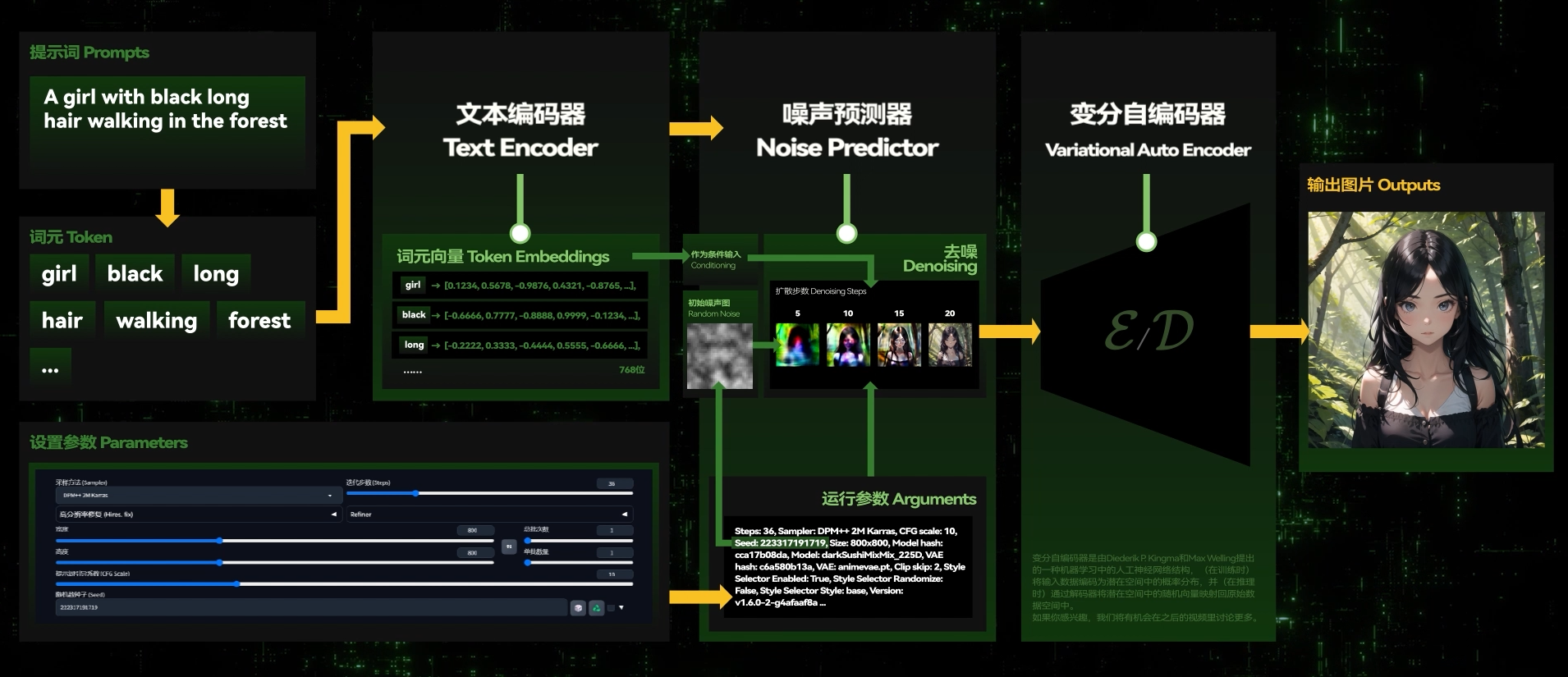
而广义的采样方法(Sampler),即代表在控制这个“去噪”过程的一种算法。简单地去理解,不同的算法会给你带来不同的采样结果,而不同算法对于采样步数的要求也可能会有些许差异。
VAE
VAE 即变分自编码器 (Variational Auto Encoder), 可以将一张图片转换为潜空间变量 (或逆向转换), 是像素空间与潜空间的桥梁。在 Stable Diffusion 中, 我们的所有生成操作都是在潜空间内完成的, 因而需要 VAE 将运算的潜空间数据转换为我们肉眼可以辨析的 " 图片 "。
负责将加噪后的潜空间数据转化为正常的图像.
可以把它理解为一种调色滤镜, 因为它最直观地影响的东西就是画面的色彩质感.
目前很多较新的模型, 都已经把 VAE 整合进大模型里了
潜空间占用的就是现显存把?
存放位置
D:\stable diffusion\sd-webui-aki-v4.7\models\VAE
自动切换 VAE
将 VAE 改成和 checkpoint 一样的名字, 然后在 webUI 里 vae 选择自动, 就可以做到自动切换了
Embeddings
D:\stable diffusion\sd-webui-aki-v4.7\embeddings
在 c 站中搜索时叫做 text 倒置
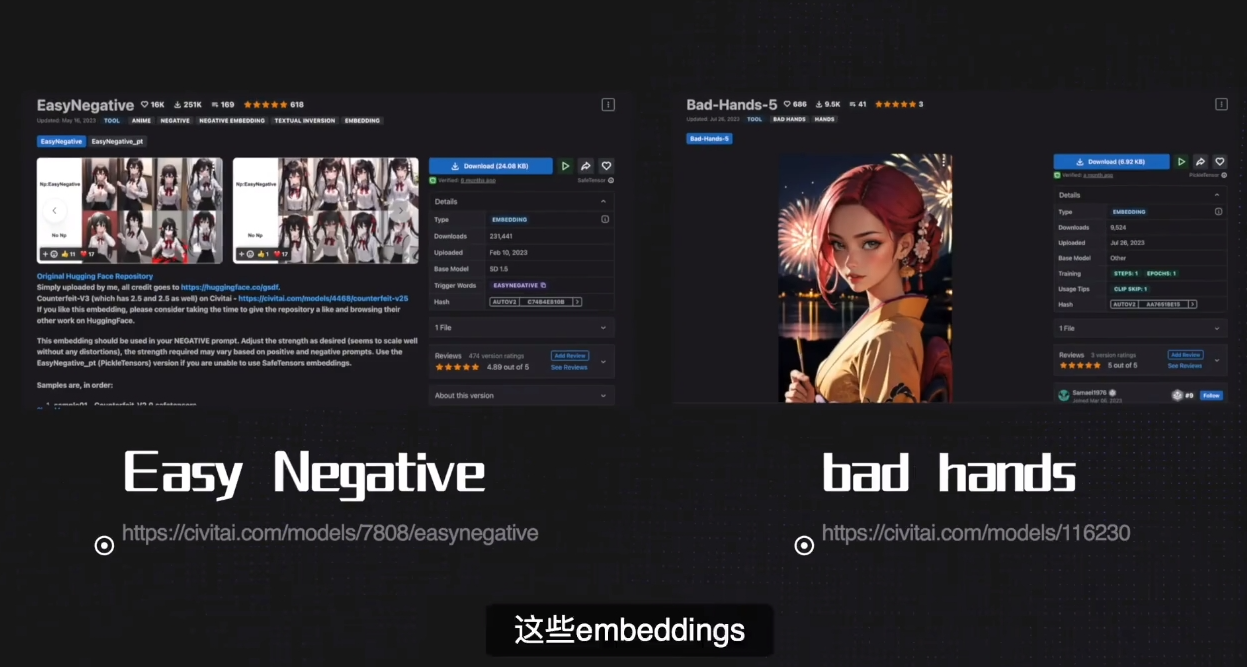
就在整合包的 embeddings 目录.
作用类似于 prompt 集合, 用个别词语代替一大堆提示词.
嵌入式向量, 但是在这里的作用就是提示词索引. 比如猫又, 大模型的字典里面没有这个词. 但是大模型知道猫, 知道怪物, 知道两条尾巴等词的含义. Embeddings 的作用就是在字典中把这几个词与猫又关联起来, 让大模型可以知道猫又对应那些词.
指向特定的形象
D.VA 的嵌入式向量. 通过提示词 corne_dva
但是针对角色创作, 其实我们更习惯通过 lora 去创作
使用特定形象的嵌入式向量更像是 coser. 而不是角色本身
三视图
通过 charTurner embeddings
解决不会画手的问题
因为是通过扩散的形式生成的, 所以其实模型对于人的正常身体结构是没有一个正确的认知的
embeddings 解决这个问题的做法是, 把模型画错的部分都标记起来, 整合成了嵌入式向量来避免这个问题.
easyNegative
取代之前加入的一系列负面提示词. 主要针对二次元模型
Age Slider 和 Gender Slider



Wildcards 通配符
[图文对照]stable diffusion人物发型提示词大全 | 草凡博客
Stable Diffusion男性发型百科全书,让你再也无需为头发烦恼_哔哩哔哩_bilibili
Lora 模型
D:\stable diffusion\sd-webui-aki-v4.7\models\Lora
二次元模型是 sd 的强项, 因为训练二次元 lora 的人多
Low-Rank Adaptation Models
低秩适应模型.
作用在于帮助你向 AI 传递, 描述某一个特征准确, 主体清晰的形象. 比起 embeddings 只是做了一些 prompt 的集合, Lora 除了对主体有描述, 也添加了一些参考图
主要场景是同人图, 这是因为一些热门的 ai 角色有足够多的同人图用来训练 lora 模型. 其实 lora 做的就是参考图, 可以是参考任何东西, 大模型参考之后都能更好的出图
关键确实是在打标和处理素材,一些练角色 LoRA 的会故意把背景遮挡,然后把 1girl 一类的通用提示词替换成这个角色的名字,就会建立起一种自然关联。同时,好的角色 LoRA 还会要求拿多种不同画风的素材来训练(同人图 + 插画 +Cos 照),这些措施说出来,其实你大概应该能理解它怎么帮助你引导到一个具体的角色形象身上了
如何让甘雨穿上不同的衣服? 总感觉用了甘雨的 lora, 她就只有一套衣服了...
原理及作用
是一种个性化文本到图像扩散模型的新方法. 可以根据用户的需求将扩散模型特殊化. 给定一个主题的几张图片作为输入, 就可以微调一个预训练的文本到图像模型里, 这样它就学会了将唯一标识符 (某些特定词语) 与特定的主题绑定在一起
在 lora 出现之前, sd 只能通过由 dreambooth 方法训练的大模型. 但是大模型的训练成本很高, 消耗大, 速度慢.

和大模型一样, 文件同样是 ckpt 后缀或者 safetensor 后缀. 需要与大模型配合使用, 做微调
出图技巧
受到 lora 训练所喂的图图源的影响, 会导出出图效果不贴合 prompt. 降低 lora 权重即可
使用方式
Prompt Lora 引用
配合 trigger work 很好. 可以直接抄作业
Additional Network 扩展
可以在额外的表单里添加 lora
和 webUI 默认的地址不太一样. 需要在 设置里设置 lora 目录, 统一 lora 目录
无法抄作业
蒙版
可以让 lora 作用于特定的蒙版, 可以生成多个特定的人物在同一幅画中
对模型的依赖
没有那么强. 现在兼容性都很好了. 效果实在不行, 再一个个尝试就可以了
人物角色 / 赛博 Coser
还有一些通用的 lora. 比如 fashion gril. 可以让生成的人物更好看一点. 作为调料即可, 权重 0.2 ~ 0.3
画风
吉卜力 lora. Studio Ghibli Style LoRA - offset | Stable Diffusion LoRA | Civitai
多个 lora 叠加使用, 一个负责实现人物的描绘, 一个负责画风.
画风类的 lora 对人物的影响较大, 因此配合使用的时候权重可以弄低一点 0.4, 而人物 lora 则依然维持再 0.7
具体的权重, 可以自己多多摸索, 尝试
胶片风和拍立得 lora, 实现摄影效果的画风: tianfeng_filmgirls 胶片质地女孩 - v3.0 | Stable Diffusion LoRA | Civitai
AI再进化,这次竟然学会摄影了!一秒生成胶片风、拍立得,还能智能“修脸”!Stable Diffusion AI绘画真实系人像模型+LoRA推荐_哔哩哔哩_bilibili
Detail Tweaker Lora
泛用性很强的 lora
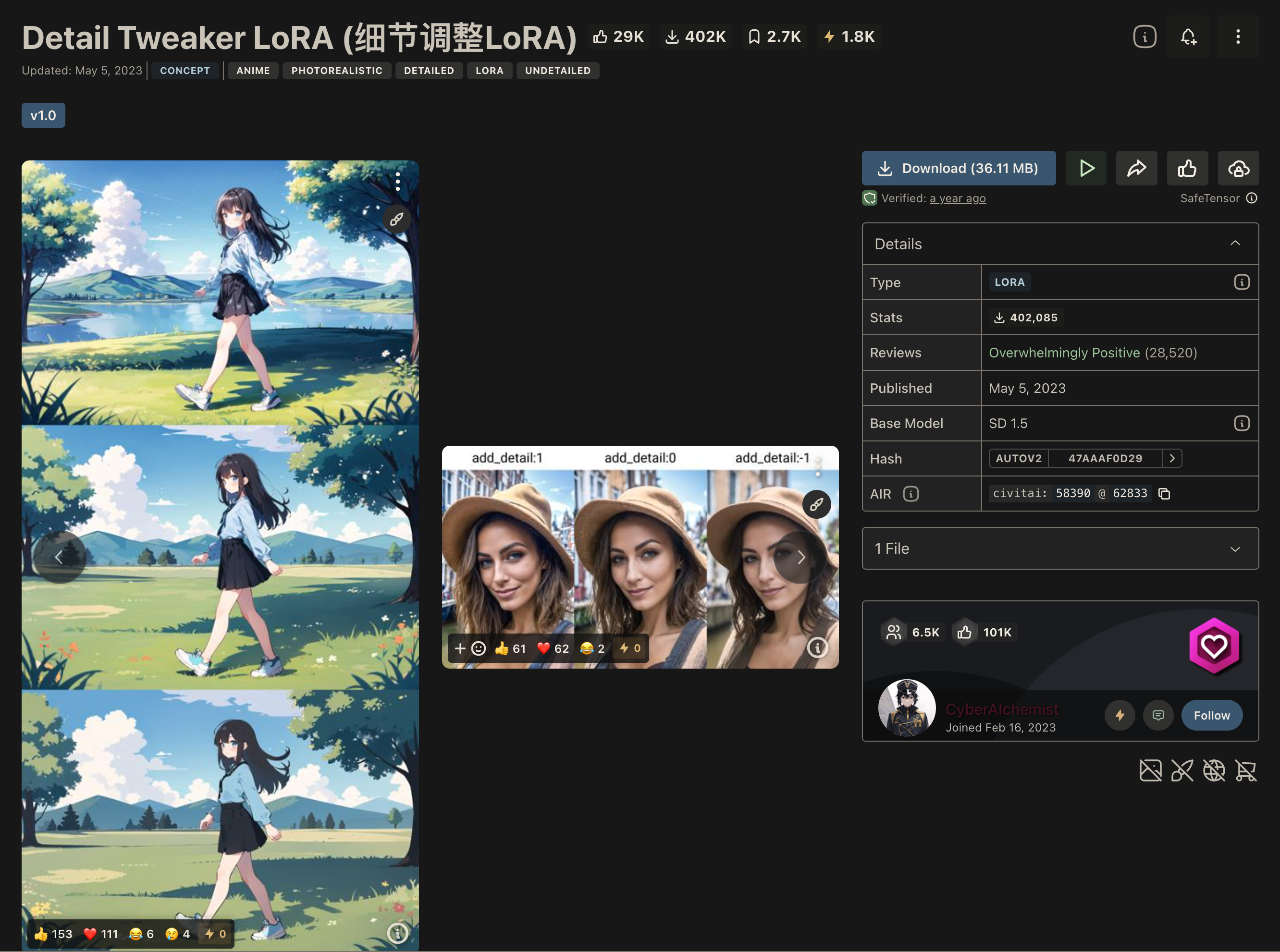
概念 Concept
Gacha Lora
生成抽卡的立绘的 lora
Gacha splash LORA - v4.0 | Stable Diffusion LoRA | Civitai
如果想要强化一个概念, 可以尝试使用该 concept 下的多个 lora 叠加使用
服饰 Cloth/Costume
服饰算是概念的一种延展, 是概念具体到衣服, 裤子, 鞋子, 袜子层面的实现.
Mecha lora, 机甲少女
A-Mecha Musume A素体机娘 - SSS | Stable Diffusion LoRA | Civitai
服饰 lora 在训练的时候, 经常会只保留衣服, 因此如果权重过高, 经常会出现一些没头没脚的情况
物件, 挂件 Objects
卡宾枪, 美食.
使用局部重绘将物件引入到画面中
Hypernetwork
虽然原理有所差异. 但是超网络最后能实现的效果, 其实是和 lora 差不多的. 也可以经由它让 ai 去学习一些在原本的字典里不存在的东西.
但是超网络一般用于改善生成图像的整体风格, 作用于画风. 不是二次元和真实系的那种差别, 而是不同的作者之前的小差别, 就比如梵高和莫奈的画风差异
设置 - 附加网络 - 添加超网络. 也可以用 prompt 直接激活
缺点
一些大佬对超网络的评价不怎么, 整体使用率不如嵌入式向量和 lora.
而且超网络的一些功能也能被 lora 部分替代, 已经出现了一个控制画风用的 lora. 比如线稿 lora
但是超网络在画风方面的作用是更加直接的
模型推荐
Sdxl 模型推荐
第7节:最新版高清分辨率stablediffusion weibui 1.6版本功能介绍_哔哩哔哩_bilibili


二次元模型
一流模型!10个高手都在用的二次元插画绘画风大模型推荐,内附模型下载渠道与出图参数提示词关键词模版 | AI绘画 · StableDiffusion_哔哩哔哩_bilibili
真实系模型
扩展
图库浏览器
Infinite Zoom
视频扩展, 用于生成视频, 但是形式与 anime diff 不一样. 是套娃不断放大或不断缩小形式的
有点过时了可能...
tensorRT
显卡速度翻3倍,AI绘画进入“秒速时代”?Stable Diffusion究极加速插件,NVIDIA TensorRT扩展安装与使用全方位教程_哔哩哔哩_bilibili
加速画图过程
英伟达官方出品的加速扩展. 针对每一款模型都需要去操作. 并且便上前不能和一些常用的扩展一起使用

自定义预设可以进一步加速引擎
进一步提升出图效率
EasyPhoto
8张照片训练个人LoRA,一分钱不花打造“AI写真”?Stable Diffusion EasyPhoto扩展插件教程,轻松训练AI绘画人脸模型_哔哩哔哩_bilibili
添加一些写真照片
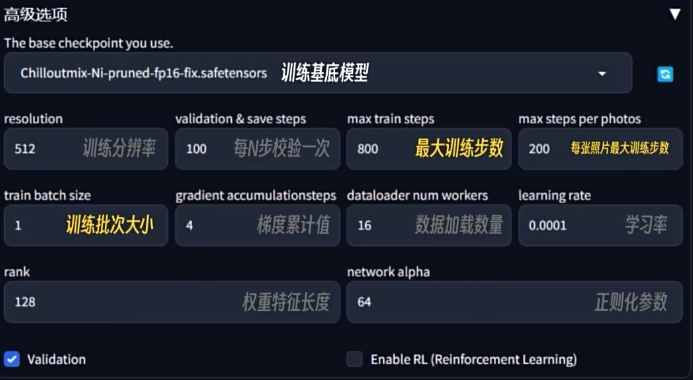
训练
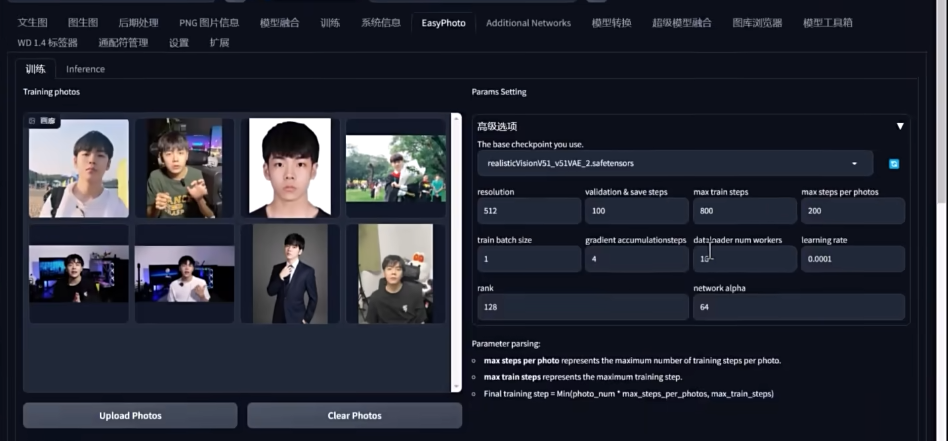
调节训练步数, 可以
同一批次训练更多. 看看 github 上有没有更多的提示
数量多少并不绝对影响训练成果, 样本质量才是最重要的

面部重绘的关键词, 可以适当补充. 在效果不好的时候再用做永华就行
做推理
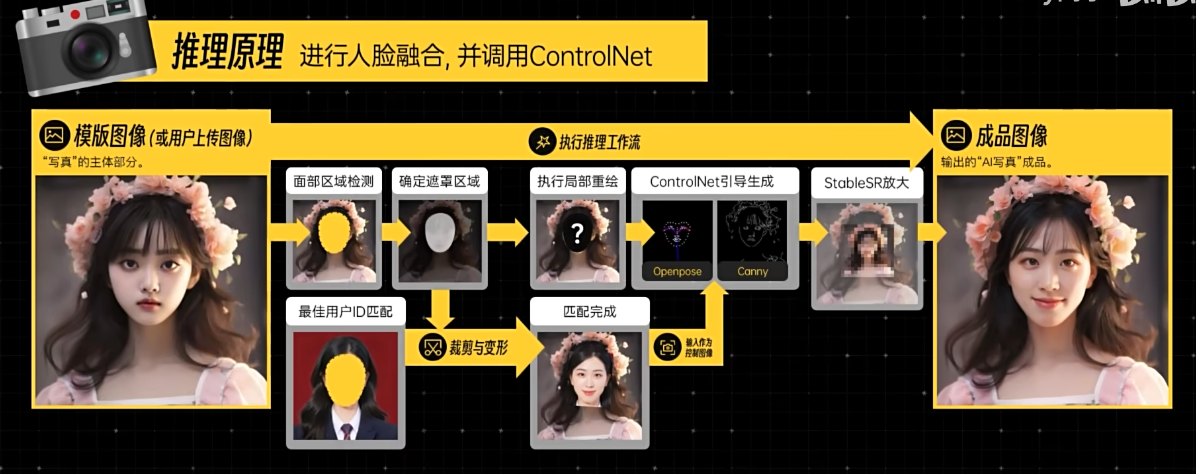
优势
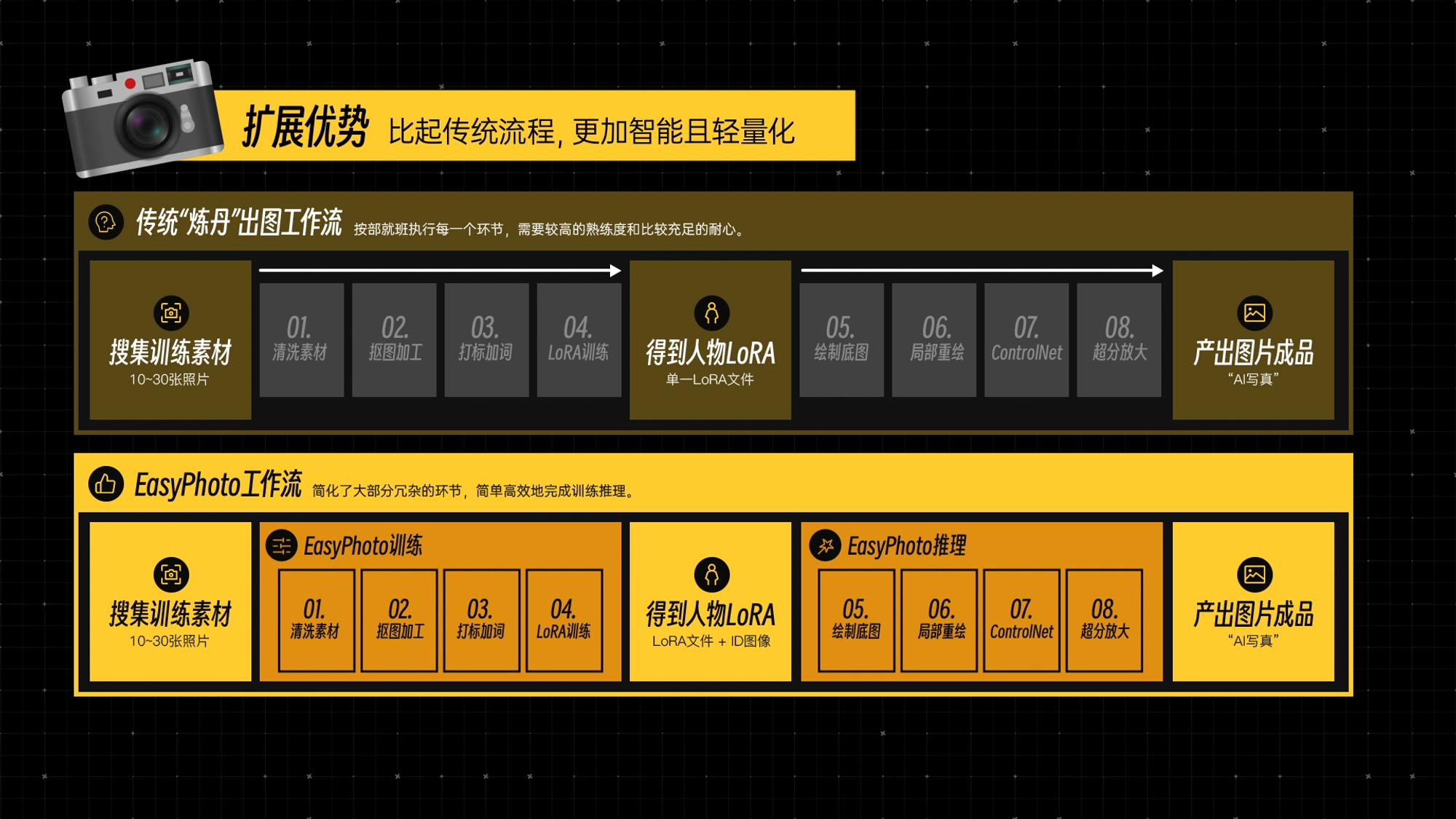
提示词
o
Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.
masterpiece,1boy, 1man, male focus,(handsome: 1.5) close-up,portrait,detailed face, delicate face, true skin texture,
diamond face, high cheekbones,
hair style
very long hair
long hair
medium hair
short hair
straight hair
curly/wavy hair
messy hair
(half) updo
bangs
diagonal bangs
hair over eyes
ponytail
twintails
french braid
hair bun
sidecut
过腰长发
长发
中发
短发
直发
卷发
凌乱的头发
(半)高髻
刘海
斜刘海
头发遮住眼睛
马尾辫
双马尾
法式编织辫子
丸子头
侧切
插件
Latent Couple
我用文生图的时候想要生成一男一女,可结果不是动作反了就是服装反了,更有甚者男的长出胸部来了,请问这种问题 up 是怎么解决的啊
有个插件叫 latent couple,也可以用更高级的 comfyui 自己解决
ADTailer
第5节:ADetailer脸部修复插件的使用方法说明_哔哩哔哩_bilibili
选完模型就可以了. 默认的参数效果也 ok.
其他参数决定了如何从图片里识别出脸部区域, 并且进行后续的绘制操作
有独立的为脸部服务的提示词窗口
detail face, close-up, portrait
以近照的标准来局部重绘.
其实就是帮我们简化了局部重绘修复面部和手部的操作, 确实是脚本操作
Auto Photoshop Stable Diffusion Plugin
轻量级的方式将 sd 的核心功能整合到了 ps 中
分享一个我不算技巧的小方法吧,我会在绘制出一个大致满意的图后用图生图反复调整出各种不同的图,或丰富或简约,然后放到 ps 里叠起来,上面不喜欢的涂掉漏出下面的,效率还是蛮高的。
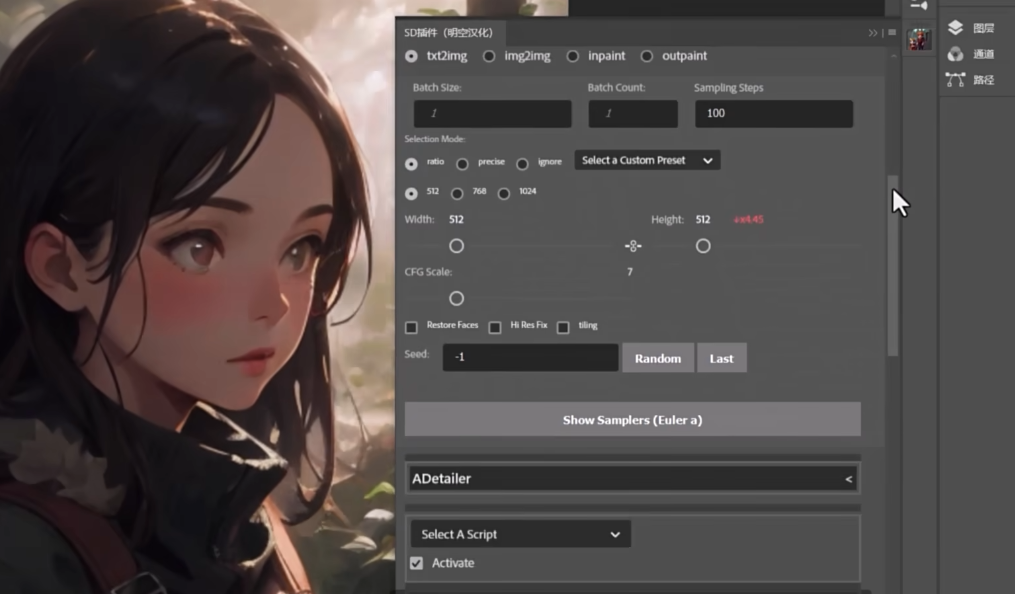
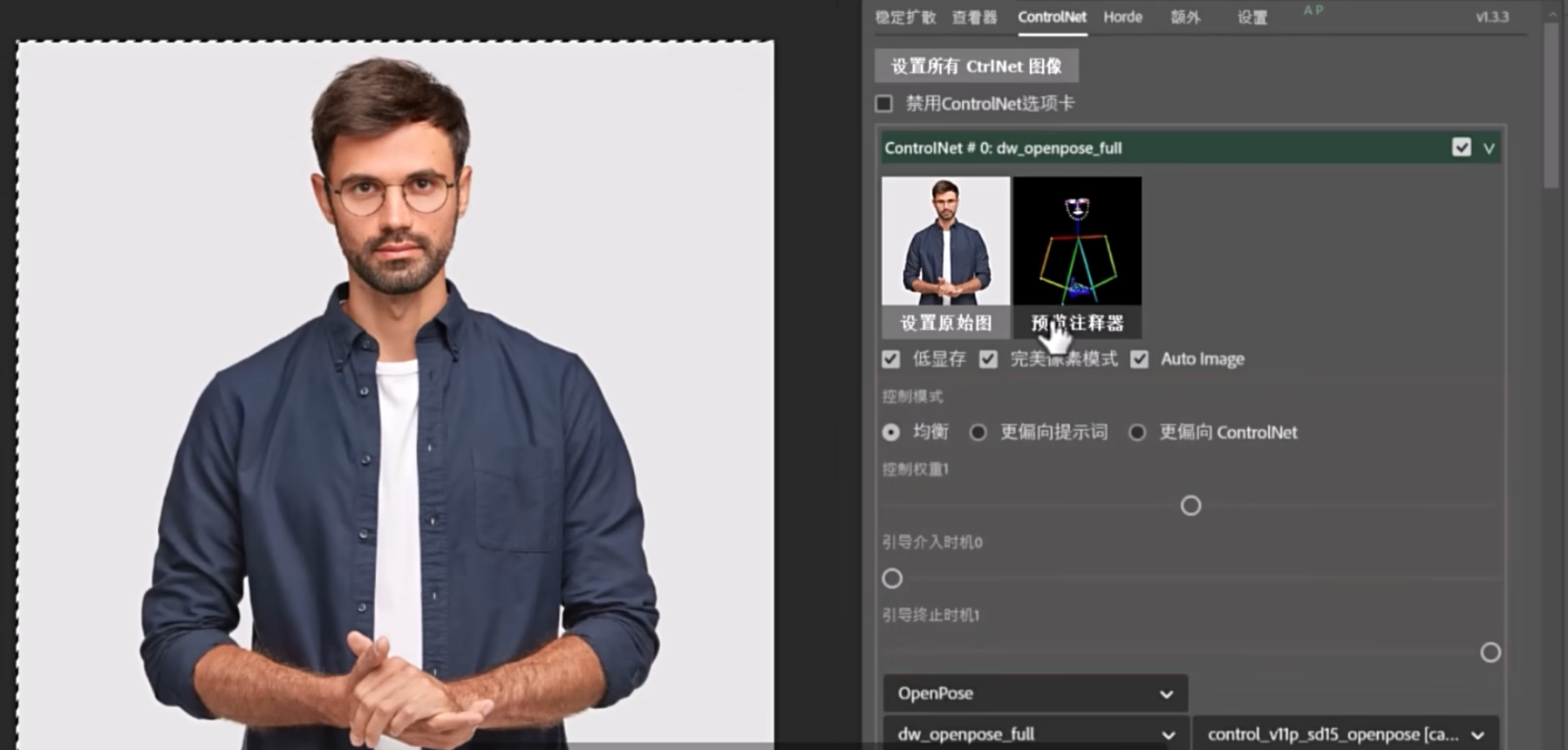
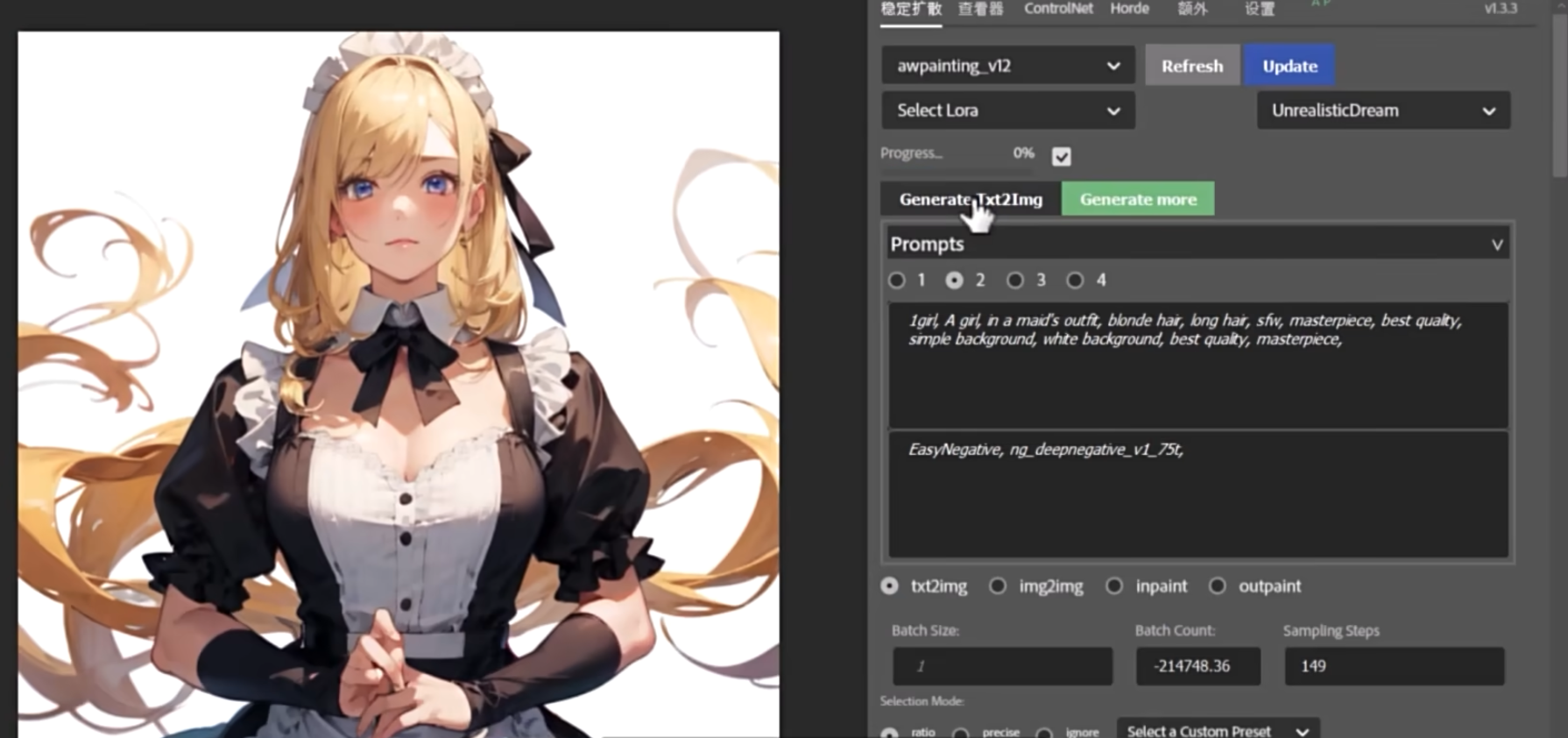
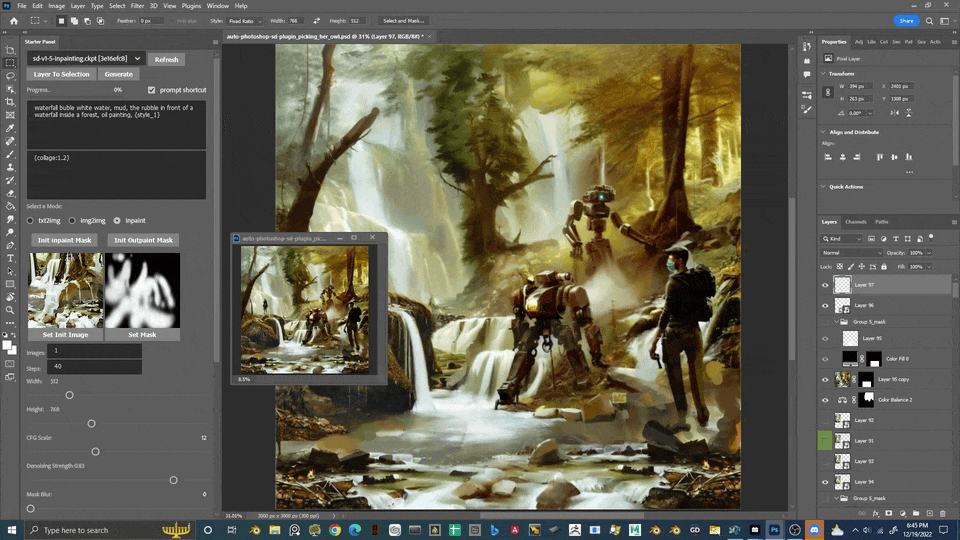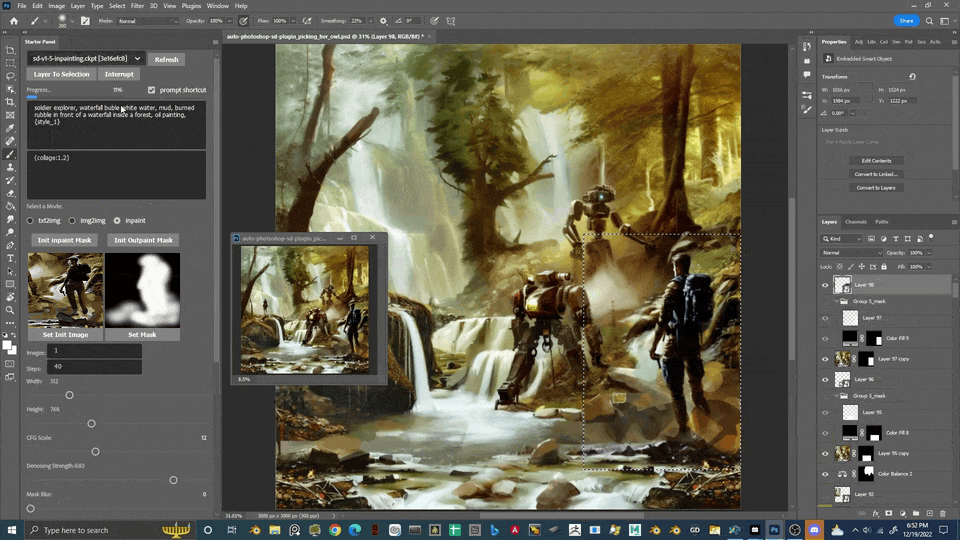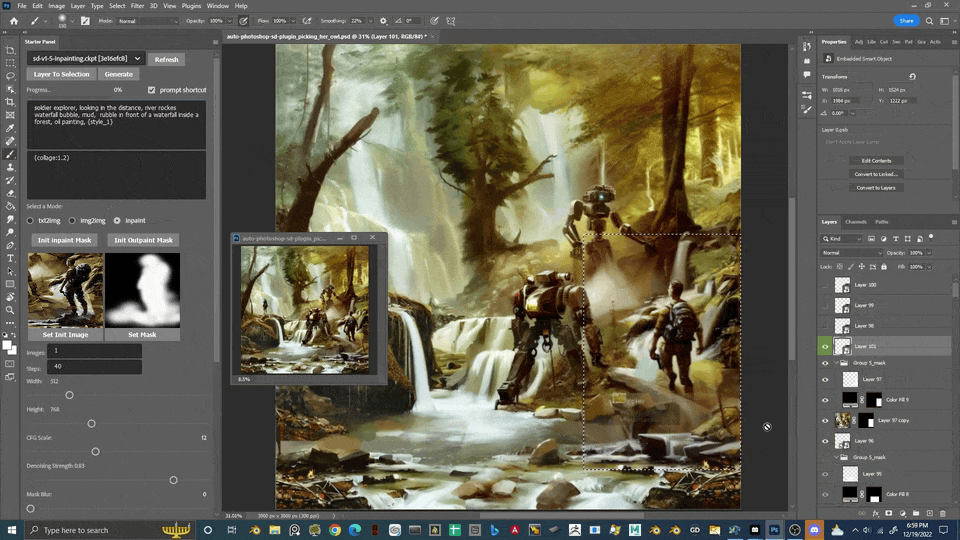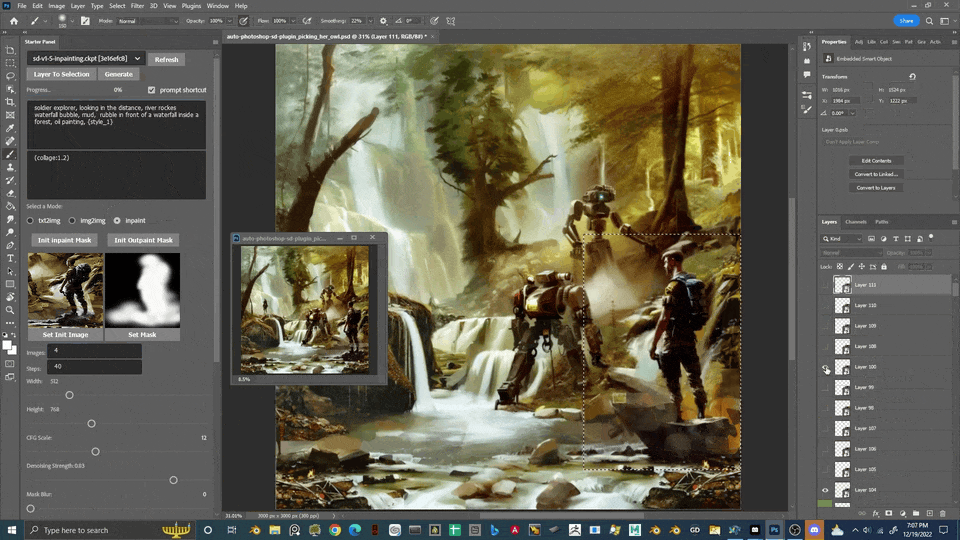
局部重绘与外绘扩图
蒙版选区更方便
扩图
极大加强了编辑功能
选区, 图层
避免反复导入导出
结合 controlNet Seg
成为了生产力
PhotoPea
SD 里面只要有一个功能就是直接发送到 PS 图层
Cutoff
动态 CFG 插件
暂时不知道有什么用
脚本
一些本身并不包含, 但是却非常实用的功能.
ultimate up scale
Xyz 图表
做图表
Cut Off
避免提示词之前互相干预. 比如颜色
生态梳理
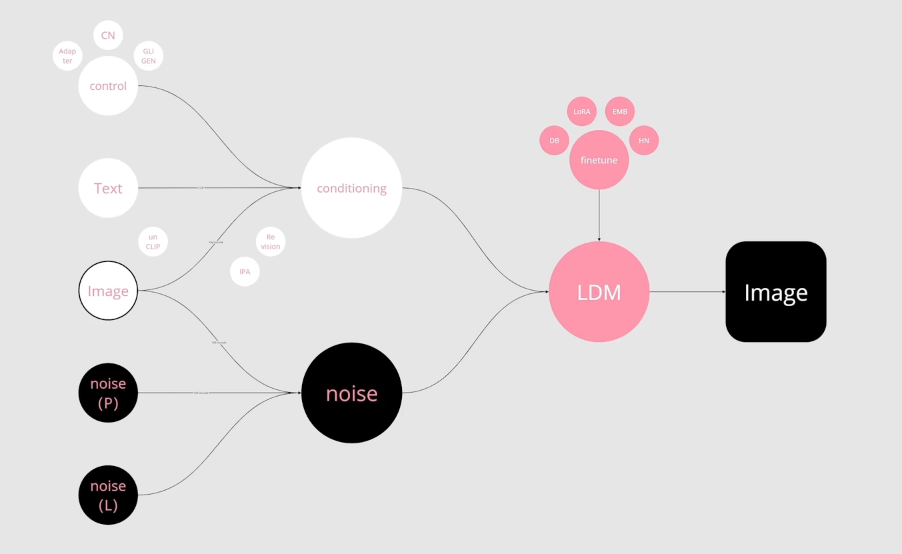
模型基础
clip 模型, 文字和图像之间的桥梁. 文字匹配图像模型
DALLE2 (unCLIP) 也是一种 diffusion model. unClip 指的是反转 CLIP 编码器