control-net
sd 迈向工业化的第一步
是一个扩展. 在 controlnet 出现之前, 模型最大的问题就在于难以控制. 顶多用于自娱自乐.
用于帮助我们施加一些用语言不太好描绘的精确内容
在 1.1 版本, 可以实现 14 种不同的控制, 这还不包括不同预处理器和多重控制网 Multi-ControlNet 能产生的复合控制效果.
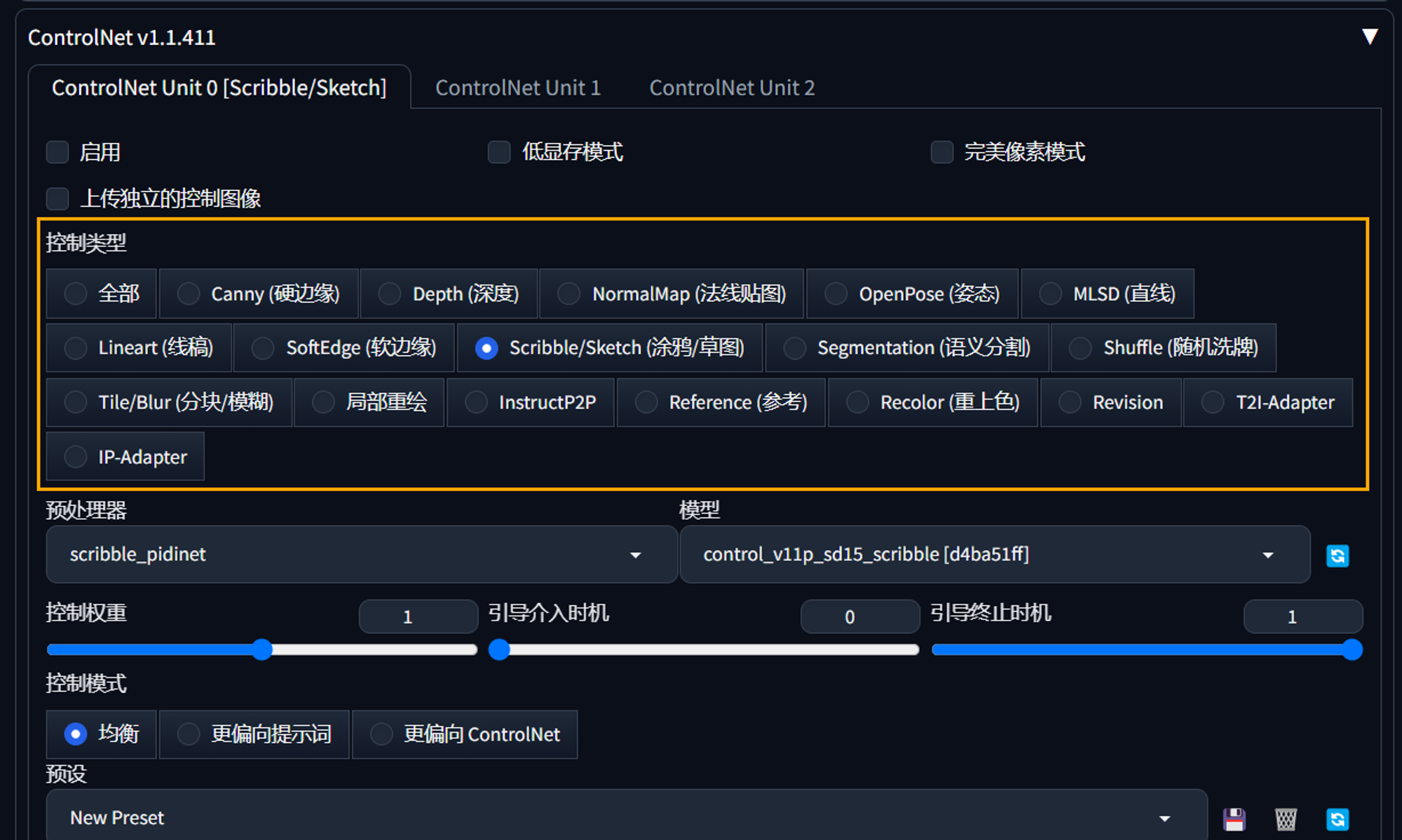
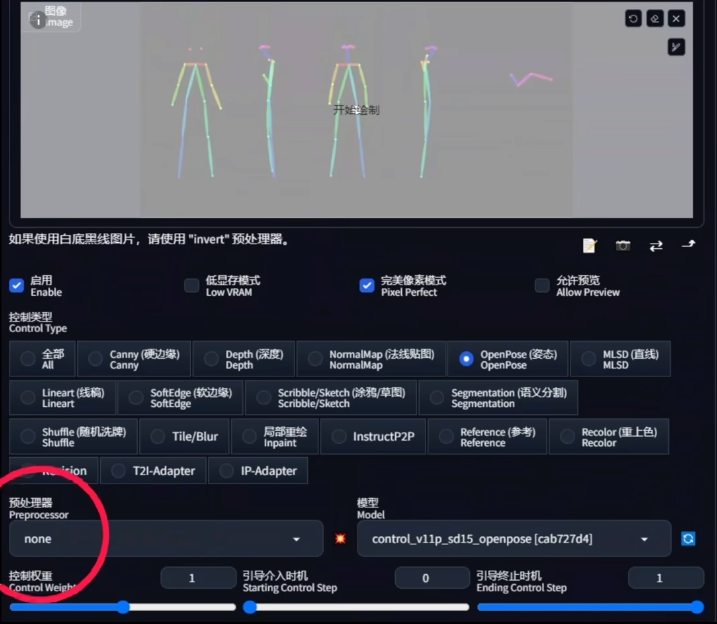
ControlNet 更新至 1.12 版本以后,上方多了一排可以用于快速选择对应的预处理器和模型的功能按钮,非常方便。选中其中的一个会自动匹配到对应的预处理器和模型上(如果你安装了)
基本原理
在原理上, controlnet 和 lora 有很多相似之处. 定位都是对大扩散模型做微调的额外网络. 根据一些额外信息控制扩散生成的走向.
举个例子: 姿势, 如果只是通过提示词输入一个跳舞, 人物可能会有无数的舞蹈姿势. 通过 controlNet 传入一张特殊的图片, 不同的点线颜色代表着不同的含义, 来让模型明白需要怎么样的姿势.
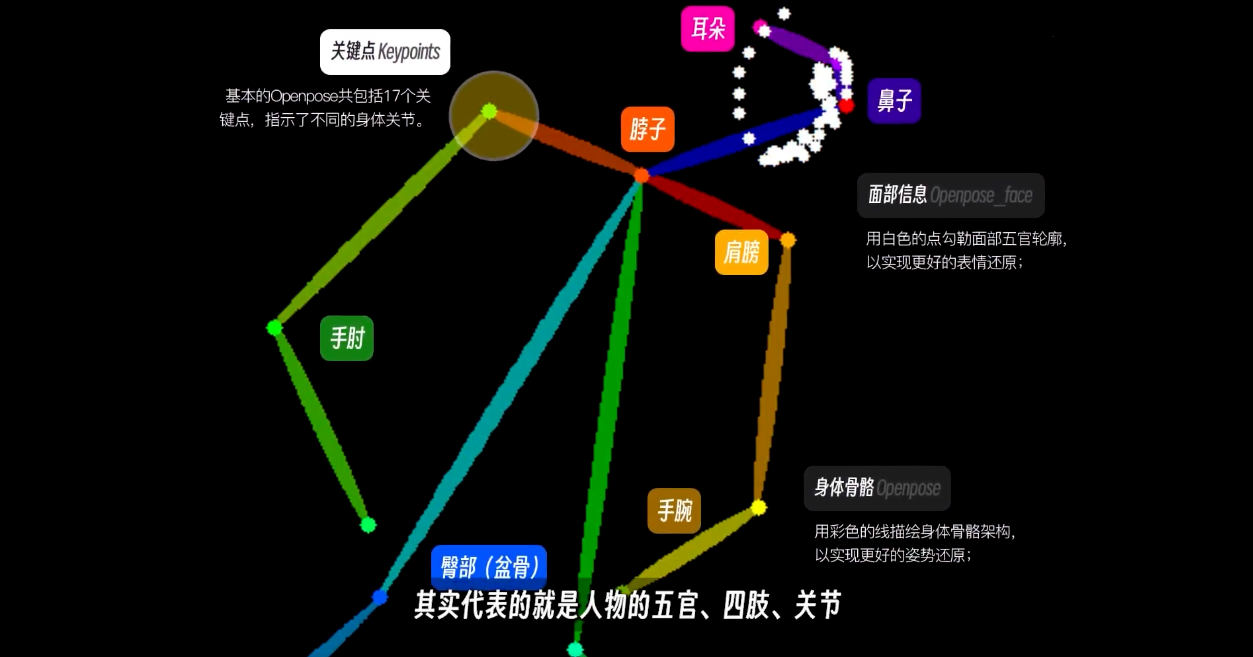
和图生图有点类似, 因为本质上来说, 都是通过一些方式给 AI 提供额外的信息, 但是 controlNet 记录的信息比图片更加纯粹, 排除了图片本身元素..
基本参数
推荐开启完美像素模式
主要影响的就是控制效果的强弱.
通过预处理器 Annotator 生成 Controlnet 需要的数据
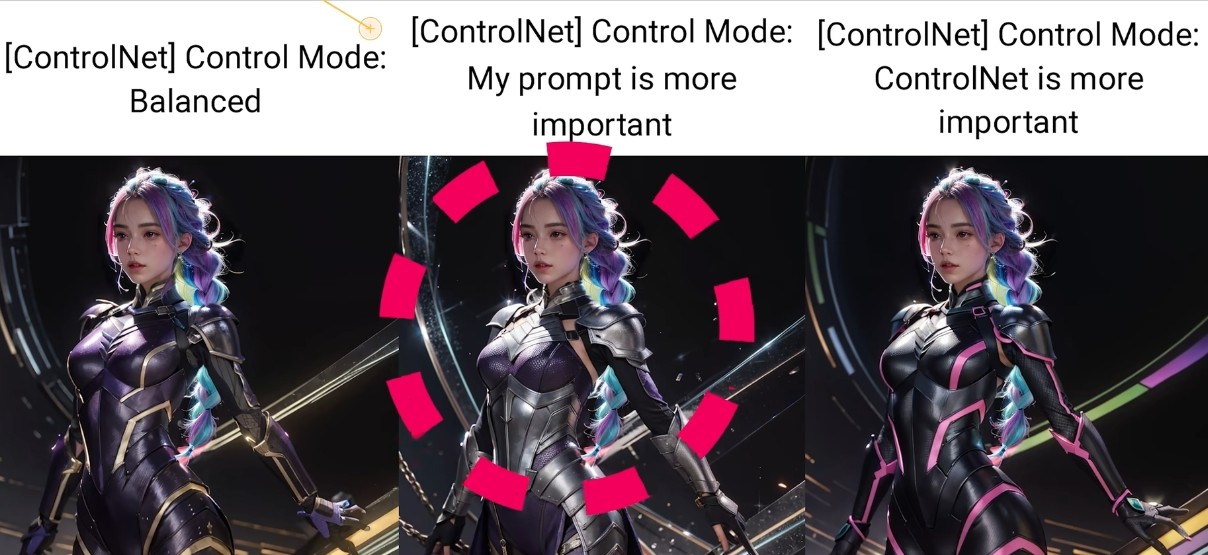
控制模式
不光是内容上的偏向, 还有风格上的偏向
内容偏向
线稿里面有, 但是提示词里没有.
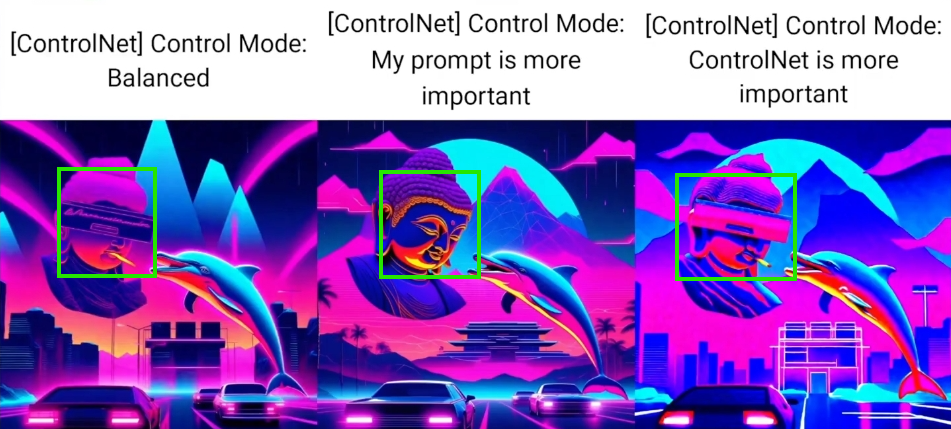
弹窗和烟头都是 pormpt 里没有的.
在均衡模式下, 烟没有了.
在偏向提示词的时候, 弹窗和烟都没有了
而偏向 controlNet 时, 两者都得到了保留
画风偏向

balance 和 controlNet mode 生成了真人, 但是头发的线条依然是二次元的.
只有偏向 prompt, 才能生成真人发质的头像

这里的内容指的是比较微小的差异
这个时候控制模式是无能为了的. 需要依靠引导时机来解决, 以及分辨率
引导时机
默认的 0 - 1 就是全程生效. 可以把时机乘上 step, 就能得到开始介入的步数和终止介入的步数.
引导介入的时机
前期的引导特别影响构图, 已经确立了构图之后, 即使提前终止了也不会对构图有太大的影响.
前期确定构图, 后期确定细节.
使用 controlNet 进行微调的一个实例:
- 对生成的月亮的亮度不太满意
- 固定随机种子
- 将月亮设置为黑白图, 手动调高月亮的亮度, 然后应用亮度模型
- 线稿 CN 提前介入, 把构图固定下来, 然后亮度模型后期才介入, 把月亮的亮度细节确定下来
预处理图分辨率
完美像素模式
勾选之后, 预处理图的分辨率就会和目标图像保持一致. 通常之下都这样选是没问题的
线稿相关模型可以设置预处理图的分辨率
canny 模型, 阈值越高, 线稿就越简洁, 可以用于去除掉主体之外的一些我们不想要的物件.
再把预处理图的分辨率调高, 调整到背景的线条不那么明显, 只保留主体. 再配合 prompt 提示词, 就可以做到在参考图与 prompt 背景内容不一致的情况下换掉背景
缩放模式
仅调整大小就是调整宽高比让参考图的像素适应目标像素. 会压扁或者拉长
裁剪后缩放就是截肢, 截掉多余的部分来满足目标像素.
扩充就可以实现 outpaint 了
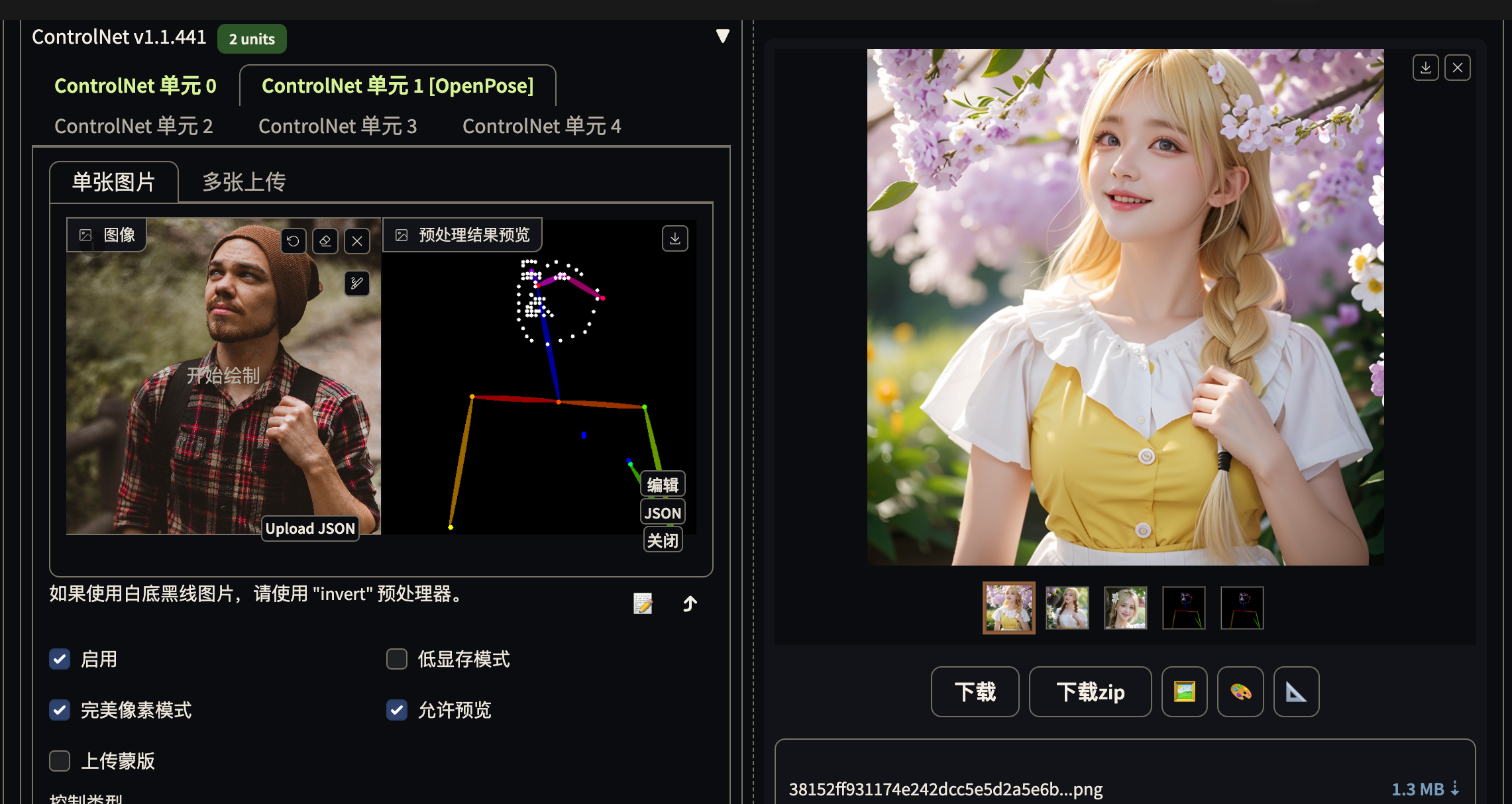
Openpose 骨骼图

通过 face, hand, 强调重点
openpose editor. 编辑骨骼图
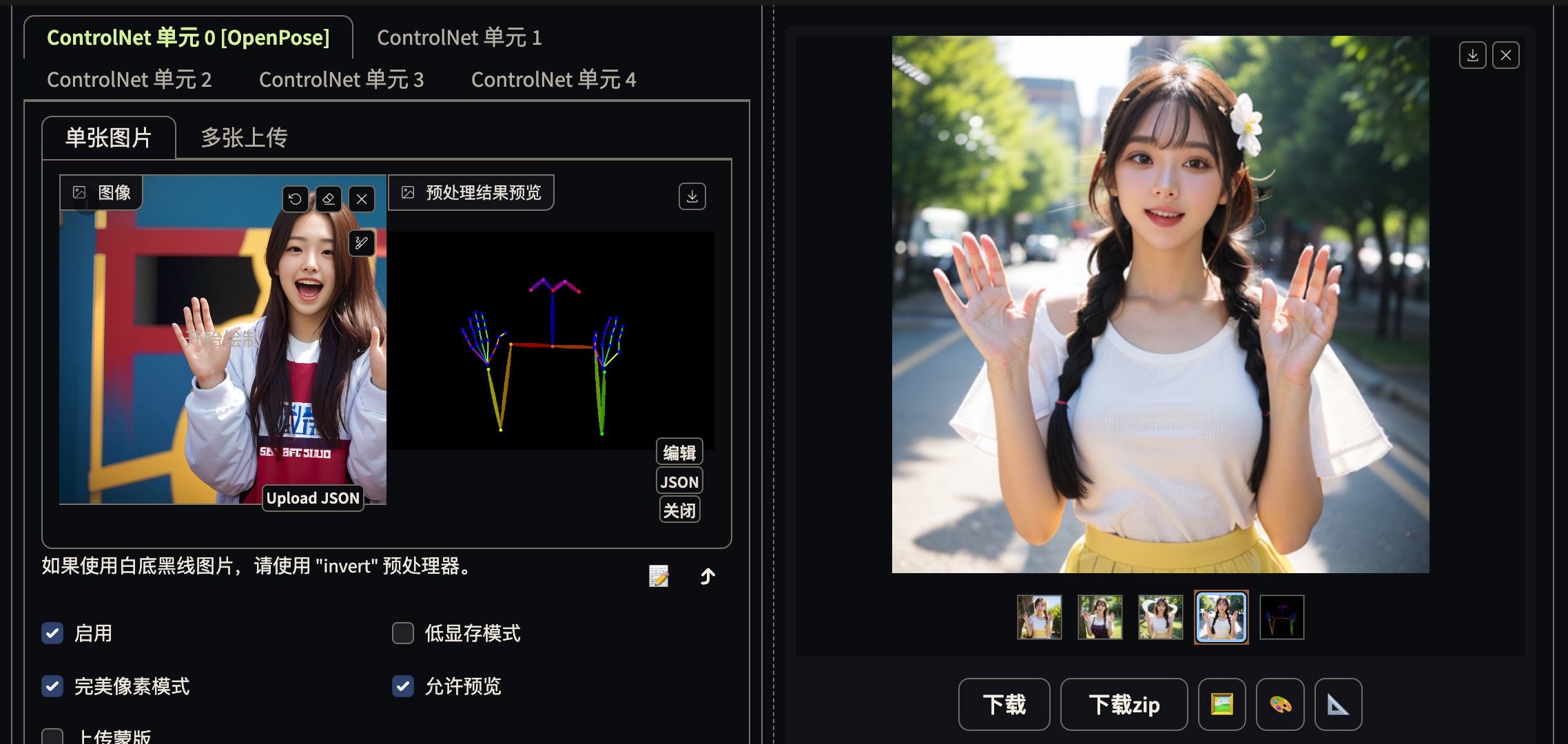
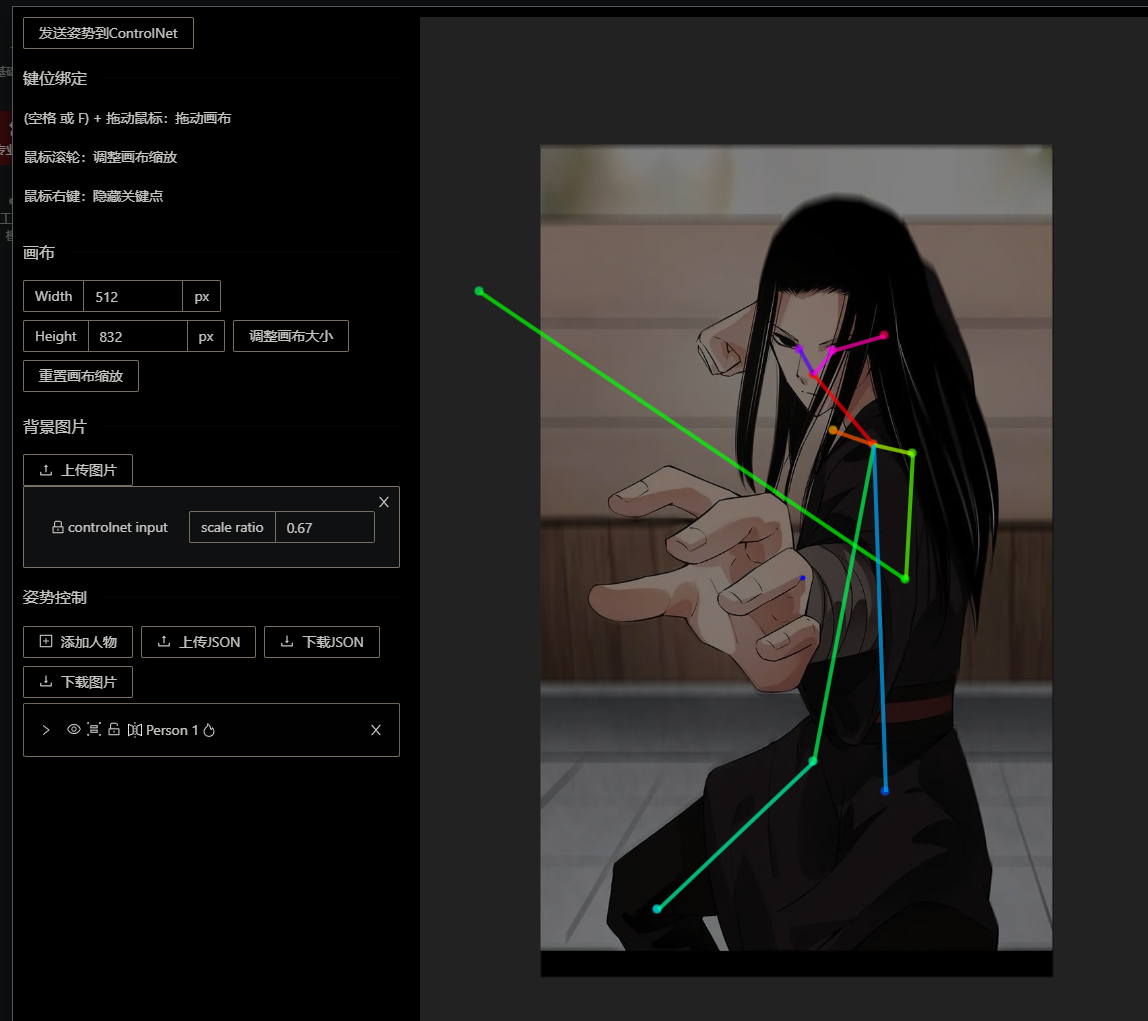
实际场景
二阶蒸馏效果是最好的. 但是太慢了. 使用 openpose 修复手指问题, 只是权宜之计? 那更好的方法是什么呢?
结合局部重绘改变人物动作
角色设计图
单人物, 多角度的设计图. 只需要由三视图的 openpose 骨架图就好了
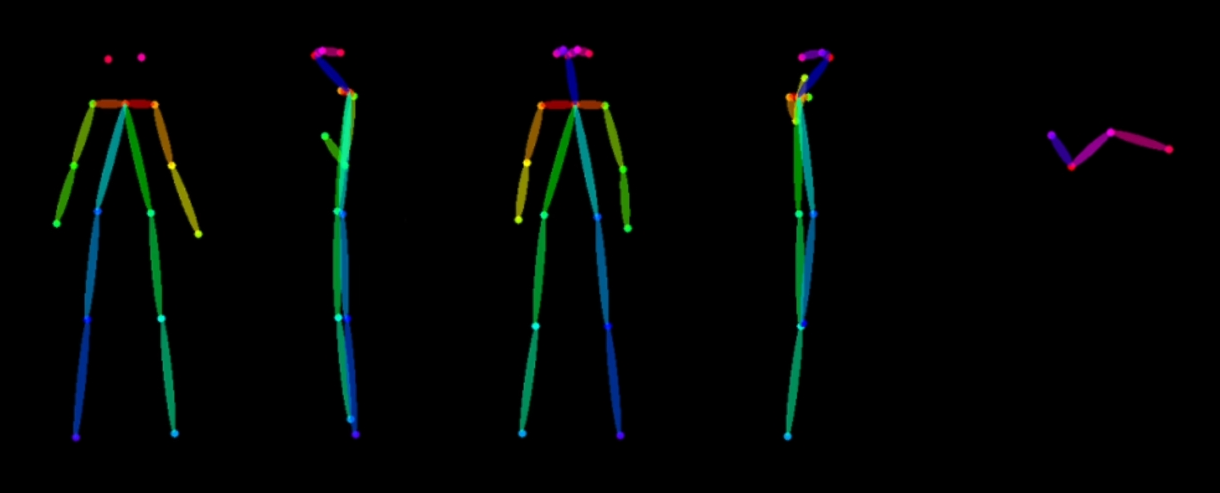
挂载一个 embeddings
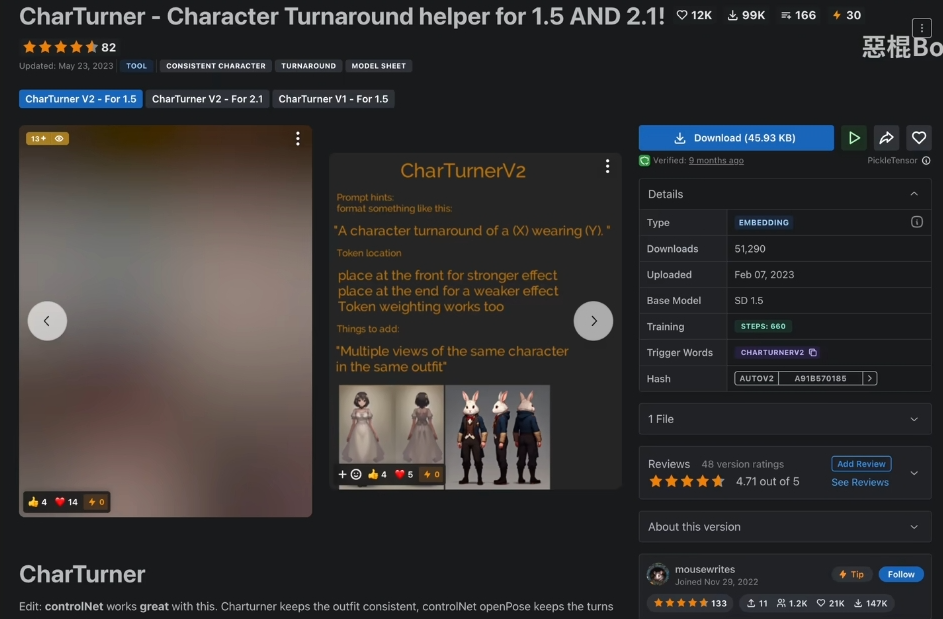
prompt: multiple views of the same charater in the same outfit
构图相关模型
Depth 深度图
对场景还原
对于富有空间感的多层次场景, 还原的很好
涉及人体透视. 因为 openpose 无法识别出手臂的前后关系.
因此这种时候使用 Depth 可以识别出来

Hed / Soft Edge
柔和边缘.
在建立边缘信息时, 会比 canny 更模糊, 让 ai 有更多的发挥空间.
柔和边缘可以让图片过度更加自然
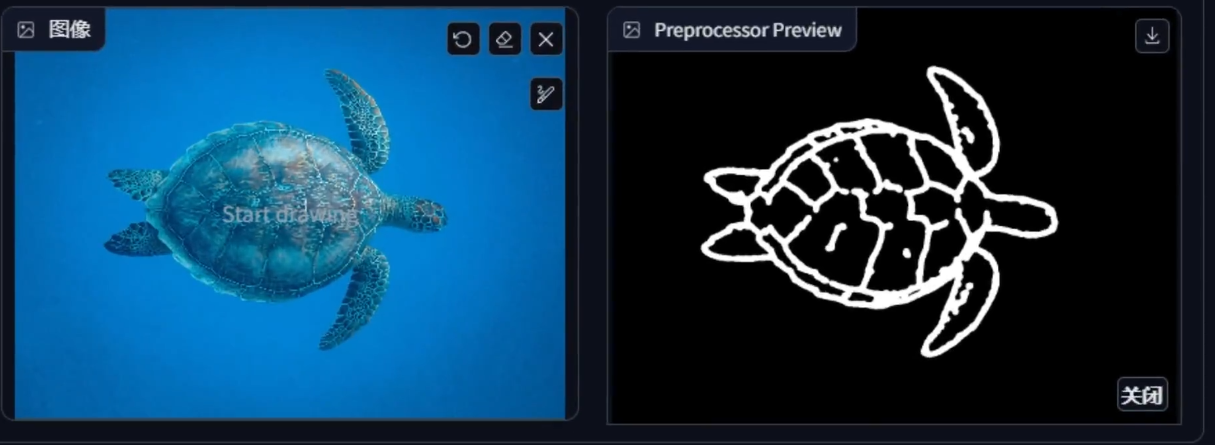
Canny
提取边缘, 草稿, 黑笔白线
controlNet 的作者认为在还原这个领域, Canny 是最重要的模型. 因为识别出来了完整的外形


参数

直接用 hed 就完事了
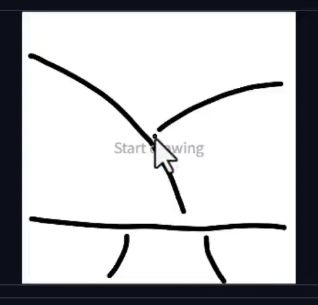
Scribble
基本使用
比 HED 更加自由和奔放的描摹. 有时候可以激发一些奇妙的化学反应
灵魂画手操作案例. 用几笔简化, 就勾勒出一个场景, 让 ai 去帮你丰富

涂鸦最大的场景还是和 ps 结合使用
参数
hed, pidi, xdog
hed 和 pidi 都是比较粗略的涂鸦, 可以通过控制 resolution 分辨率选项来调节画面的精细程度. 但是我们一般都会开启完美像素模式, 开启了之后就无法调节了
xdog 自带可调节的阈值
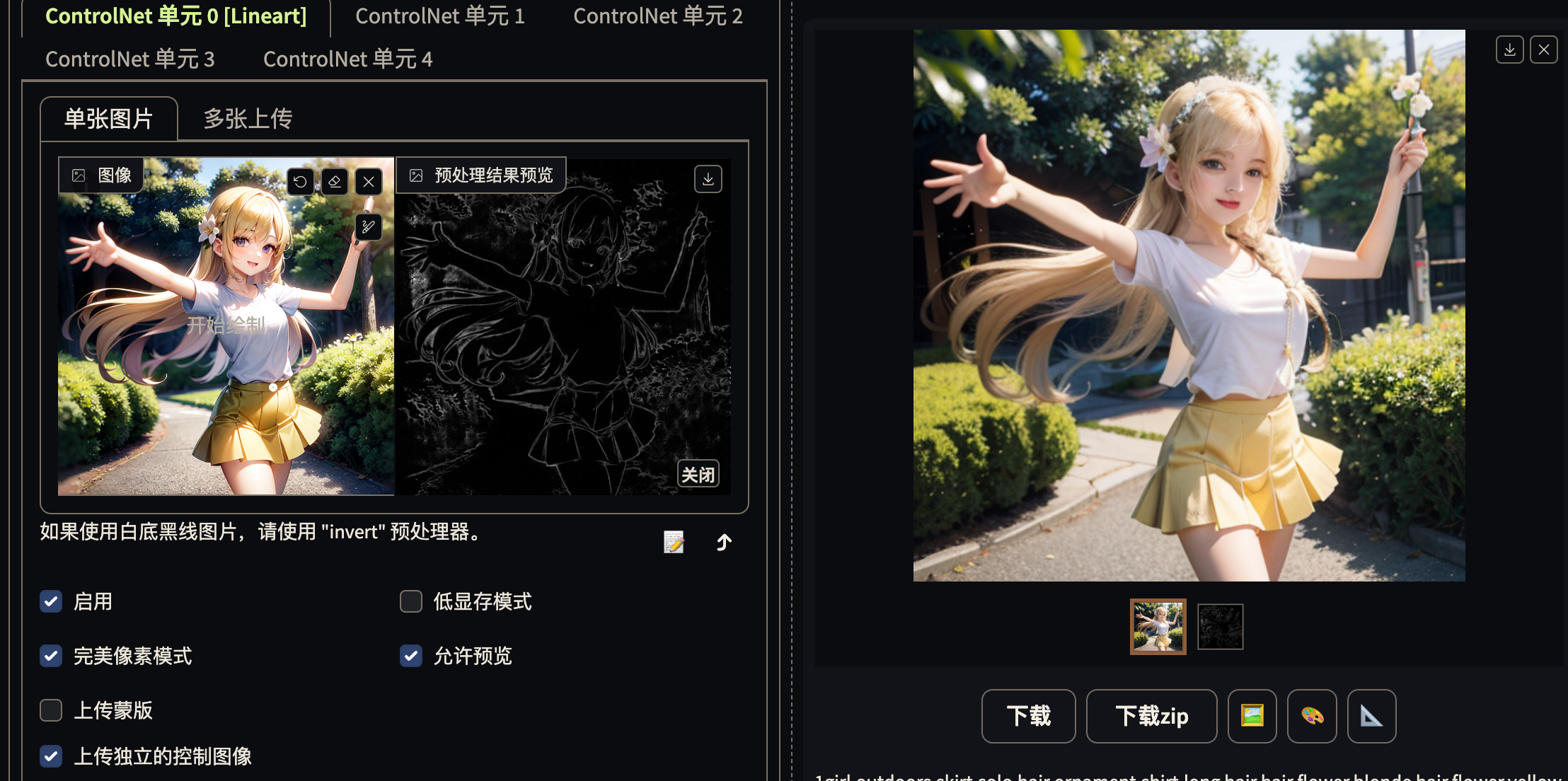
lineArt
线稿上色, 形体固定
基于线稿图生图, 使用不同的风格的大模型即可实现真人化或者动画化
预处理器和模型的搭配
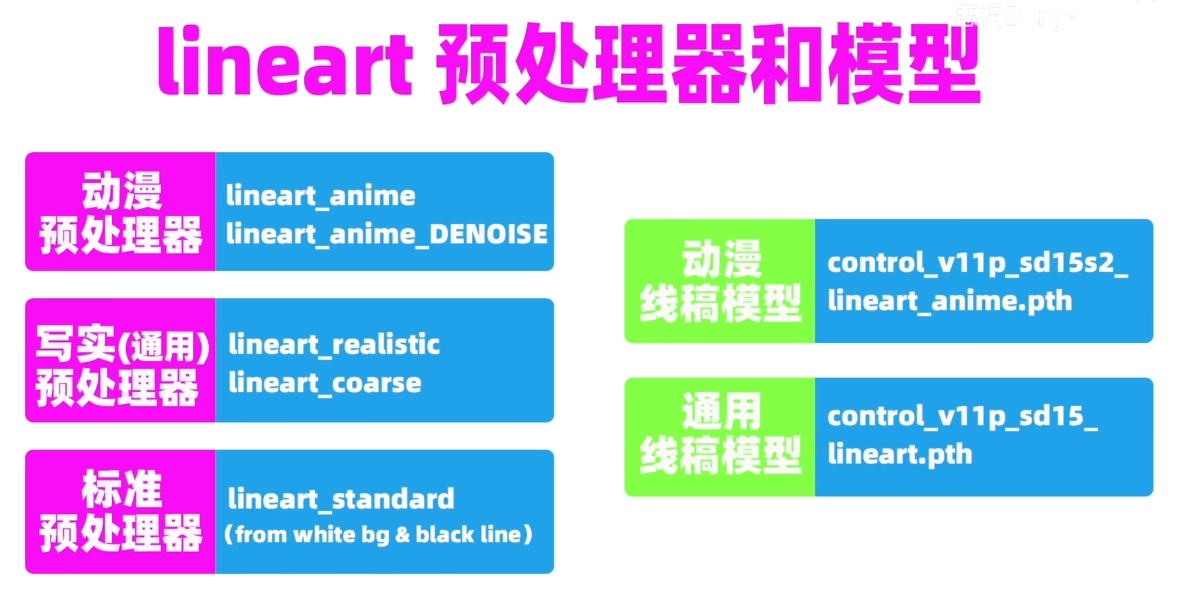
动漫预处理器只能由动漫线稿模型搭配. 因为动漫预处理保留的内容, 只有动漫先搞模型可以理解并且正确处理. 比如动漫漫画里常见的网点
动漫线稿模型只有使用偏向提示词才有好的效果. 因为线稿模型没有猜测模式, 所以只能选择偏向提示词模型并且加上详细的引导, 因此使用动漫线稿模型的时候 controlNet 的控制效果会被严重削弱, 需要一个比较详细的提示词
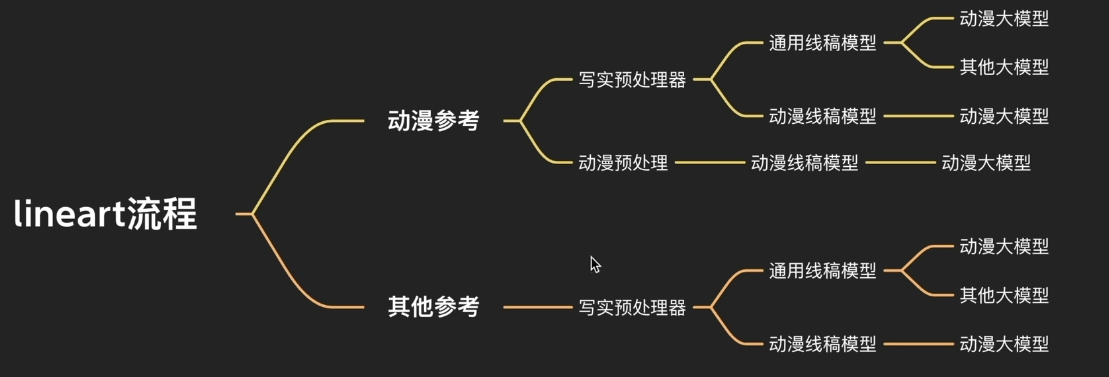
逆向运用
其他参考 + 动漫预处理器 + 动漫模型 + 其他大模型
可以实现构图整体由参考提供, 但是具体的样式取决于 prompt. 因为动漫处理器和动漫模型无法对非动漫参考产生主要影响, 只能定下来构图
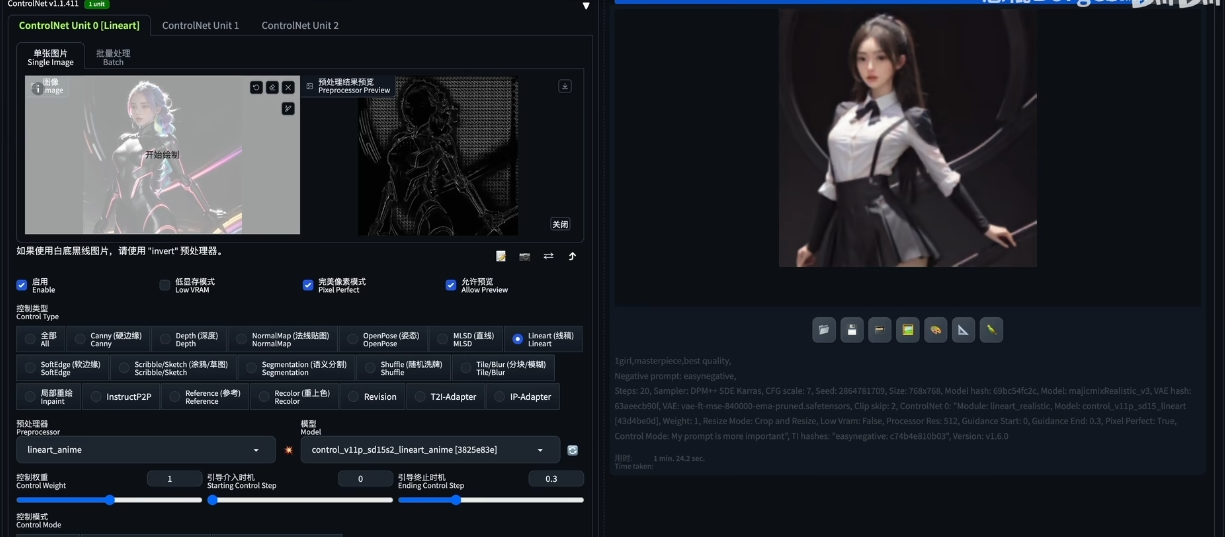
重绘修复相关模型
inPaint
实现创新型局部重绘
加强重绘区域内外的关联, 让过渡更加自然
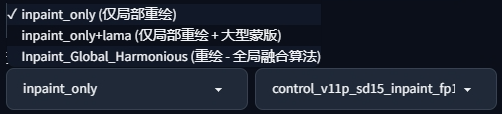
inpaint_only 除了重绘的部分, 其他不改变.
inpaint_only + lama 大模板, 选择选择扩展后填充空白, 可以用于扩图
第三个: 全局融合算法, 会影响蒙版以外的地方. 非蒙版的区域为了协调整体, 也可能会发生局部的改变
Tile
号称是 controlNet 的最强模型
在放大工作流种增加细节.
除了用作 upscale, 还有很多其他作用.
Tile 的本质是一次细节重绘, 既然是重绘
用作图片修复
可以配合 ipadapter , 拾取柴犬的图, 辅助一下就 ok 了
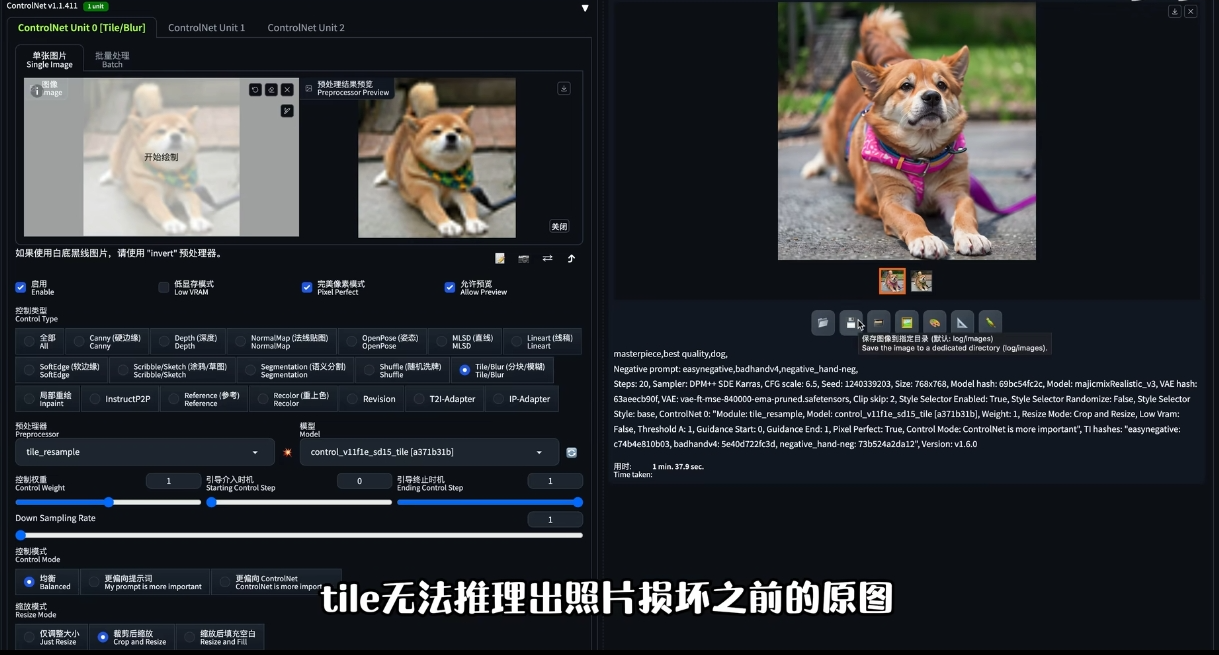
用作风格转换
如果仅仅使用大模型进行风格切换, 我们的提示词需要非常精准, 不然结果可能和原图差异比较大
在上者的基础上挂上一个 tile 模型. 并且使用更偏向 controlNet 模型, 就可以直接使用大模型完成风格切换了
头发颜色不一致, 只需要补充一下提示词就好了


风格统一




偏向提示词模型, 还可以做到自动合理化空间透视和光照效果


替换内容和修改细节
盔甲变旗袍
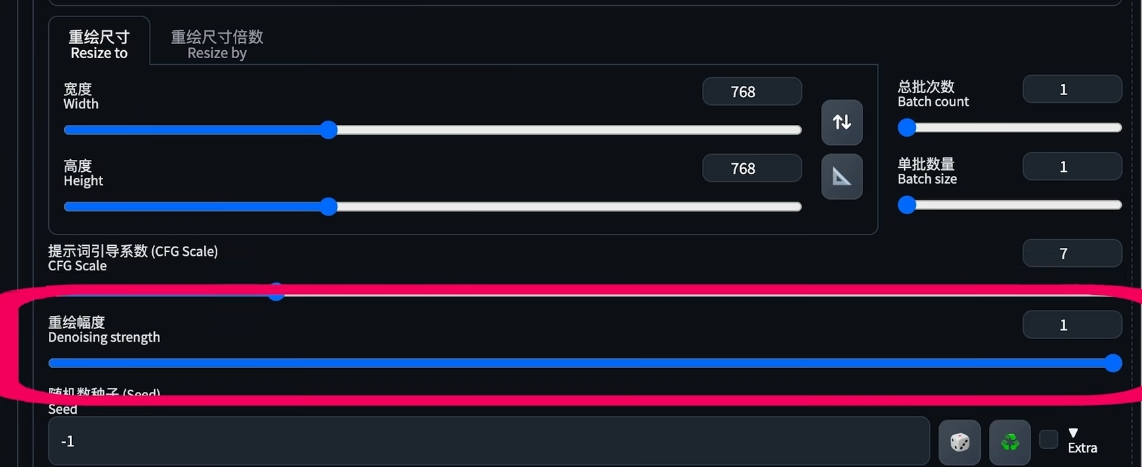
不同程度的 down sample rate 会有不同程度的细节重绘. 参考图的缩小倍数, 缩的越小, 重绘之后的细节变化就会越大.
降低参考图的细节, 让模型有更多的空间去重绘新图像的细节

down sample rate = 4, 就可以做到通过提示词修改服装, 并且整体保持一致
结合局部重绘, 保证脸部不发生改变

InstructP2P
文生图 + controlNet 独立控制 + make it xxx 使用效果应用到图片上
prompt 只需要 make it 的部分就好了? 独立控制图像会和 prompt 互相影响, 选择不同的控制模式来避免这个问题
感觉作用成谜...
但是具体的作用也是基于一张已有的图片, 去做精修. 精细的控制. 希望能在原图的基础上, 做一些改变. 或者补充一些细节
图像提示相关模型
时间线: reference only => faceid => instantid => pulid
有测评表示 instantid 的效果是最好的...
Reference Only
出现得最早的用于人物一致性的尝试. 效果不好才有了后续的 ip-adapter 和 instand_id.
现在比较鸡肋了
用于固定特征, 也可以用于保持人物一致性, 但是泛用性更强一点. 类似于很多个长得很像的人, 穿搭也是一个调调, 但是仔细看就能发现每次脸都不一样? 但是在小说推文场景, 可以用作角色的创建工作, 作为人物管理的基础. 还是够用的
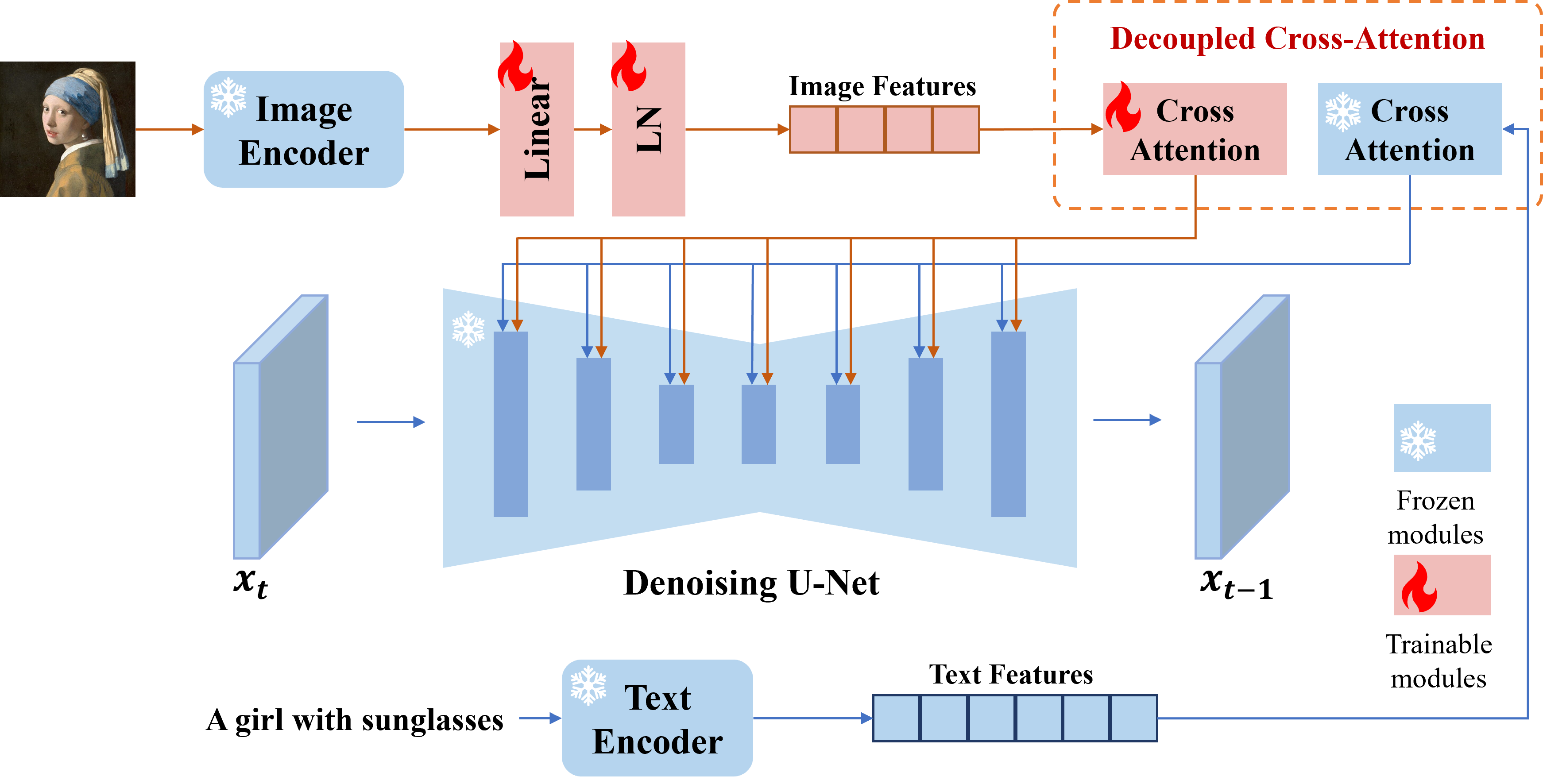
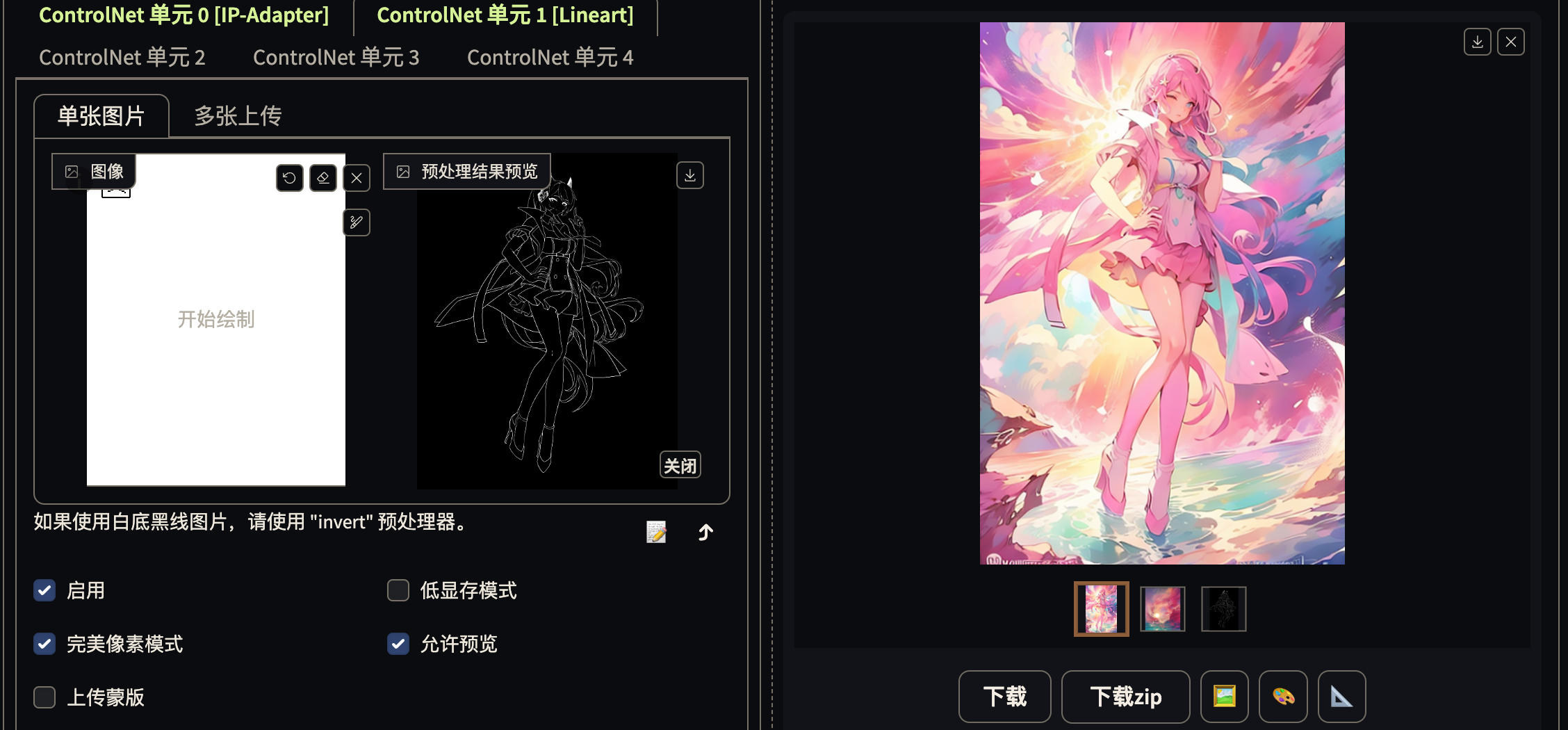
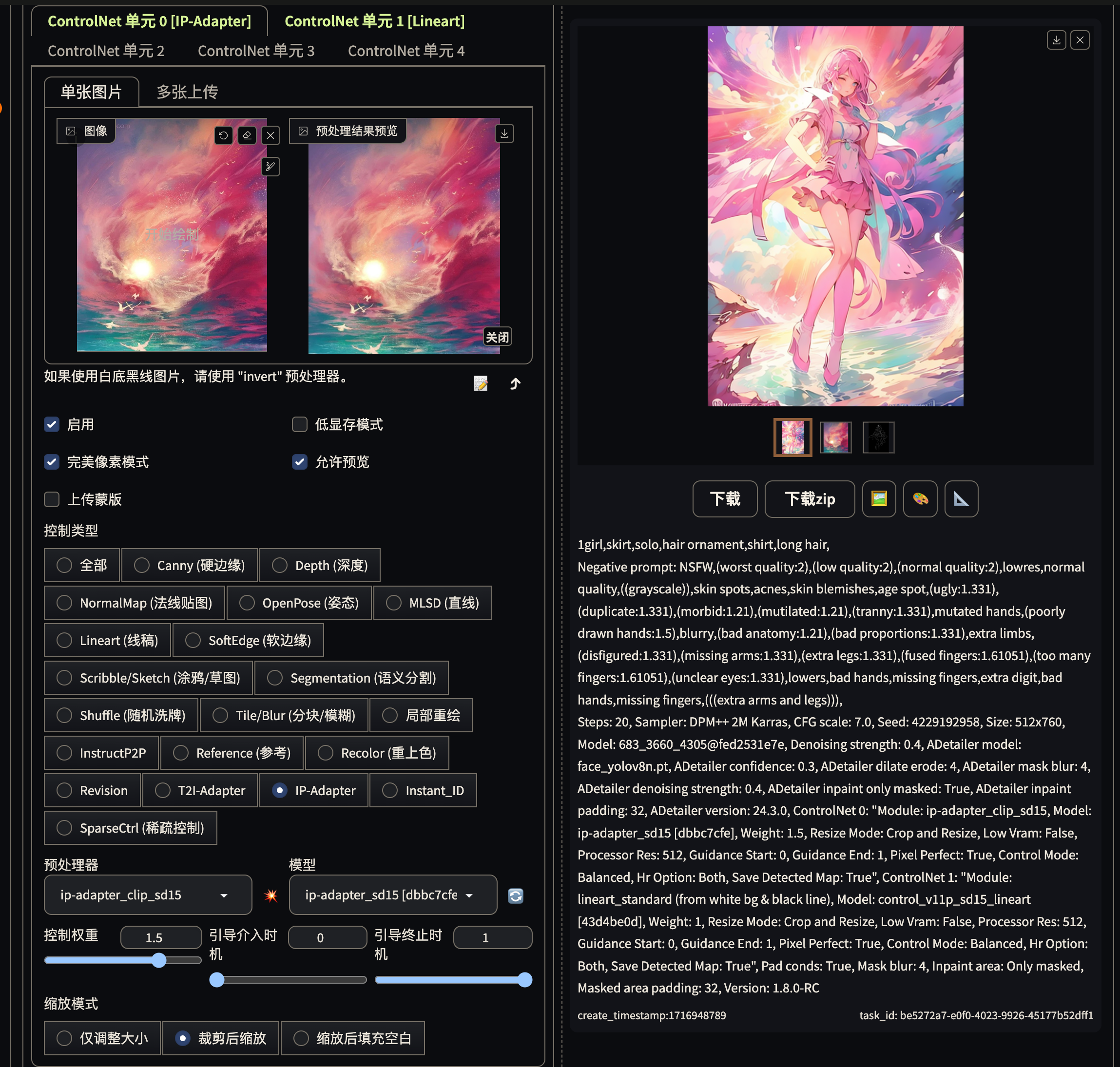
IP-Adapter
实现 mj 的垫图效果, 可以参考图片的风格, 构图, 人物特征. 配合 prompt 实现局部的修改

图生图并非一种真正的提示, 只是塑造一种色彩上的相似性.
IP-Adapter 会去真正的理解你输入的图片的含义, 并利用他学习到到的东西去微调输出的结果.
从色彩, 形象, 内容, 已经, 都会更像参考图.
不同的 IP-Adapter 模型, 迁移的内容不同, 注意甄别
参数
参考面部
ip-adapter face 和 ip-adpater plus face. 效果都不如 face id 的. 我直接删掉了. 需要参考面部的就专门看 face id 章节就行
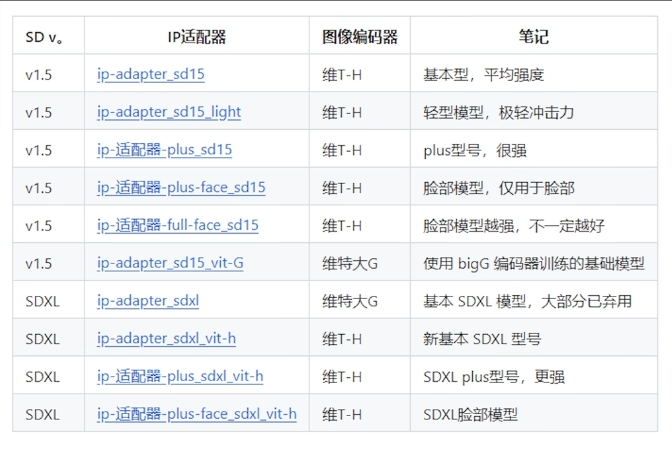
参考整体
ip-adapter_sd15, ip-adapter_sd15_lingt, ip-adapter-plus_sd15
三个 VIT-H 14 图型编码器, 全图嵌入, 全局嵌入, 捕捉的是整体的特征.
内容的忠诚度: plus > sd1.5 > light.
- plus 适合偏向参考图的要求, 生成的图像更接近原始参考, 但通常无法复刻图片细节, 例如面部特征.
- light 更适合偏向提示词的.
- sd1.5 适合在偏向提示词的基础上, 配合 prompt 做一些小修改. 能大致遵循参考图像的内容, 能够捕捉图像整体的宏观特征. 包括颜色特征, 纹理特征和形状特征, 整体亮度, 对比度等


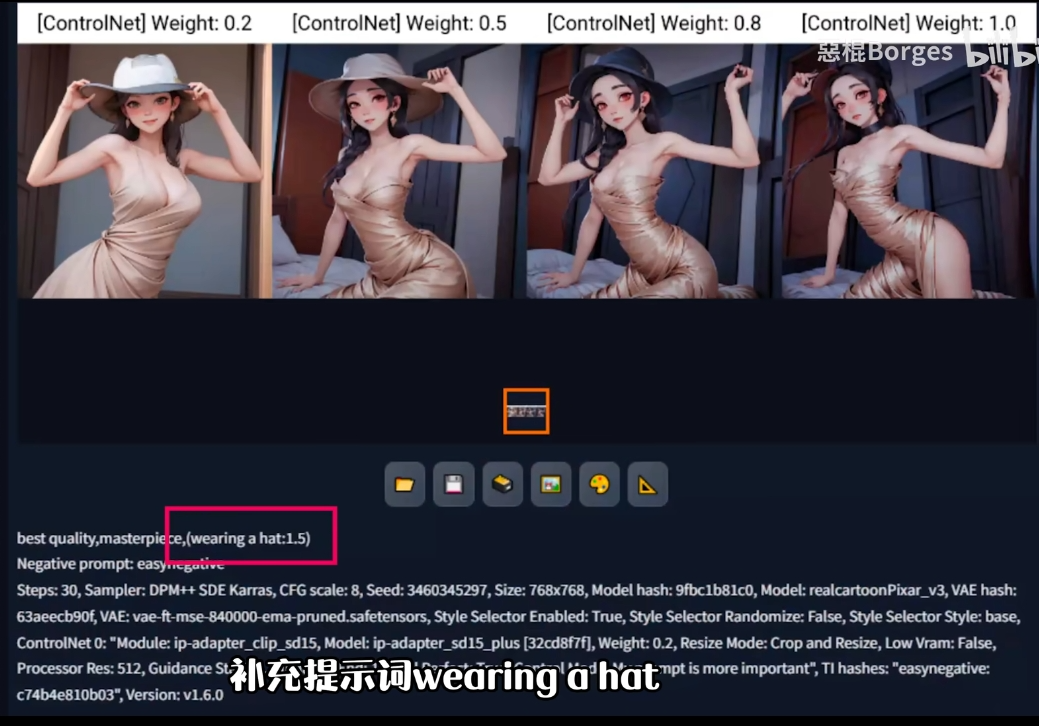
权重的影响
没有 prompt 的时候, 可以直接使用 1, 权重越大肯定是越倾向于参考图的.
想要提示词发挥作用, 0.5-0.8 是比较理想的. 权重与参考图和 prompt 期望的动作也有关系
实现风格迁移
实现换肤, 风格迁移
Ip-adapter Face Id
【AI绘画】Stable Diffusion轻松生成一致性角色!一键设定人物长相!强到离谱!(附安装包,插件)_哔哩哔哩_bilibili
模型选择
人脸识别识别模型中的 insightface id 嵌入, 并且可以搭配使用 lora 模型来提高脸部一致性. 权重 0.5-1.0 都可以
ip-adapter-faceid 效果其实是可以的. 但是只有脸, 没有面部的结构支撑. 我都没能下载下来, 可能是官方自己都是已经不推荐了
ip-adapter faceid-plus, 还使用了 clip 图像嵌入用于人脸结构
ip-adapter faceid-plusv2, 还允许调整脸部结构的权重, 但是只能在 comfy ui 上使用

ip-adapter faceid-portrait, 肖像专用模型, 整体作用与 faceid 基础版是相同的, 不需要使用 lora , 可以接受多张参考图, 来提升图片的相似性.
基本使用
很不错. 配合 openpose 使用, 就可以摆 pose 了. 很舒服. 比 reference only 效率高, 泛用性强
--- start-multi-column: ID_iv2g
Number of Columns: 2
Largest Column: standard

--- column-break ---

--- end-multi-column
--- start-multi-column: ID_d6i7
Number of Columns: 2
Largest Column: standard

--- column-break ---

--- end-multi-column
InstantId
保持人物一致性
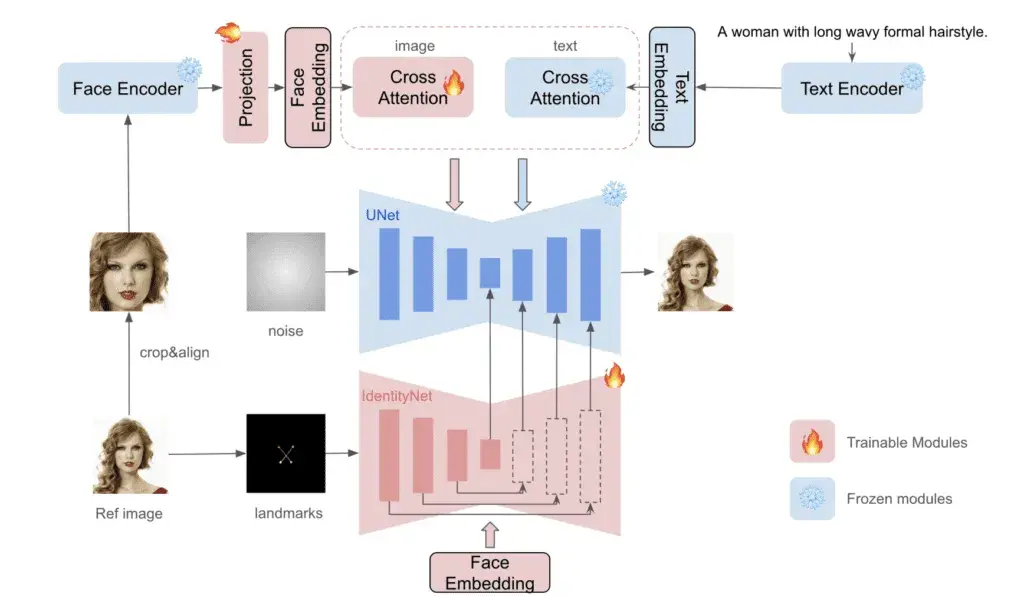
InstantID 使用 InsightFace 从参考人脸中检测、裁剪和提取人脸 embedding 。然后 embedding 与 IP-Adapter 一起使用来控制图像生成。这部分与 IP-Adapter Face ID 非常相似。不过,它还使用 ControlNet 检测并修复多个面部标志(眼睛、鼻子和嘴巴)
结合使用 IP-Adapter Face ID 和 ControlNet,可以高保真度地复制我们提供的参考图像,从而最终实现人物角色的一致性。
注意:InstantID 需要使用 SDXL 大模型,目前还没有 Stable Diffusion 1.5 对应的版本。
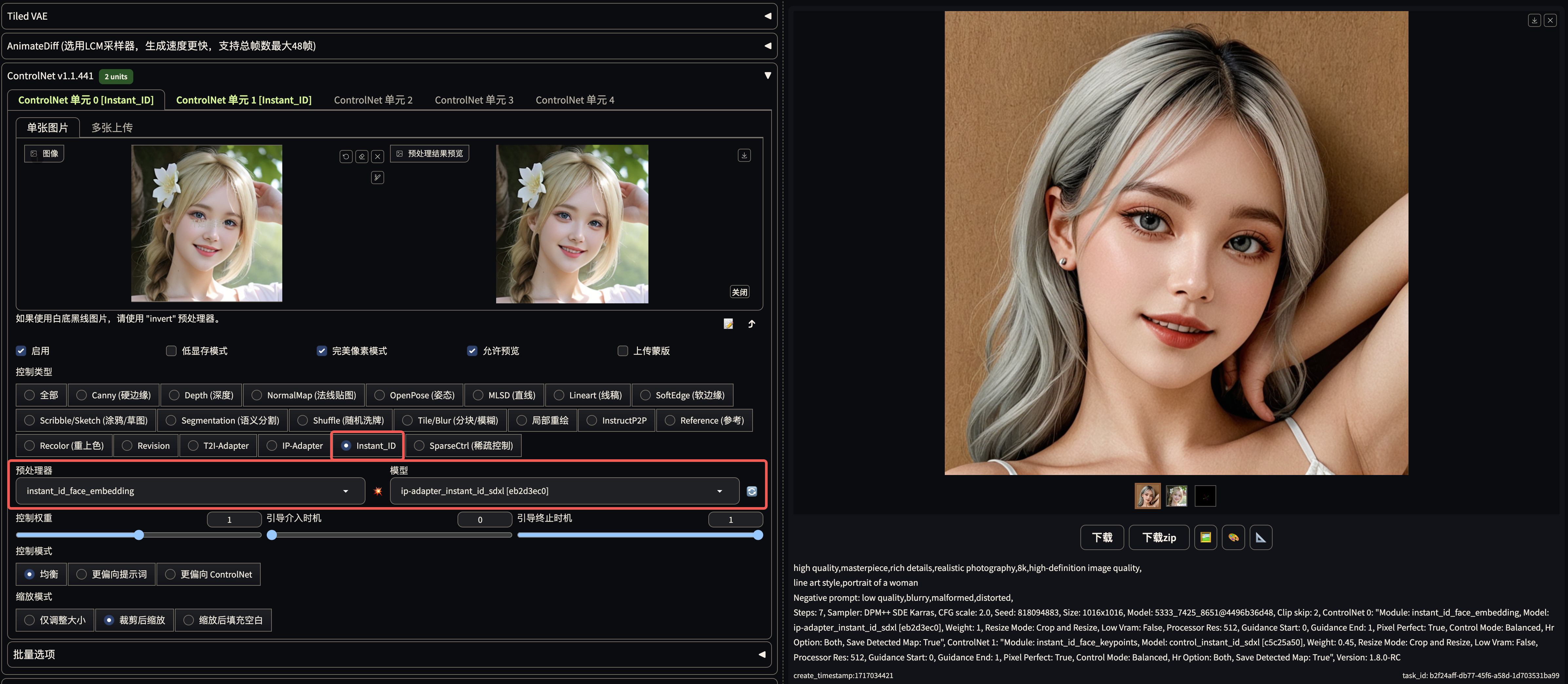
操作实例

controlNet unit 0 使用 embedding 预处理器 + ip-adapter_instant_id_sdxl, 主要负责脸型
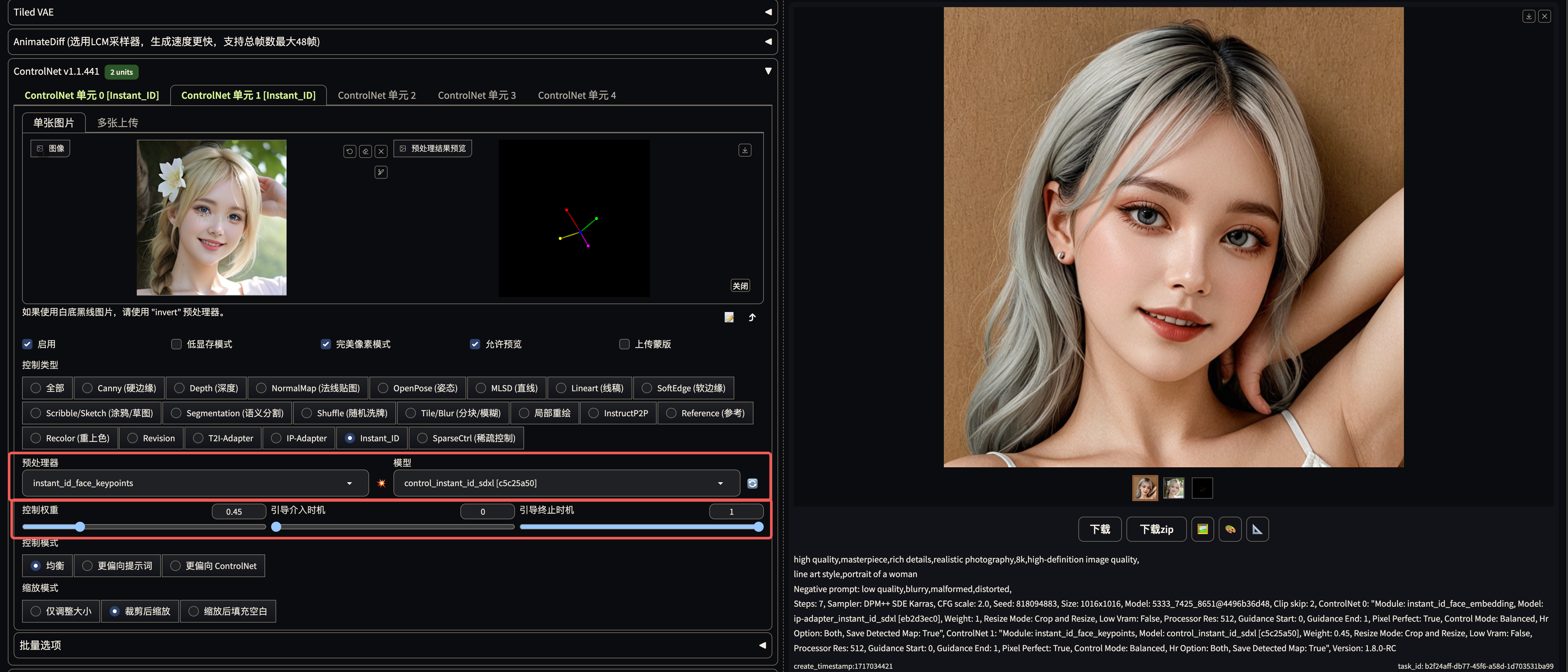
controlNet unit 1 使用 keypoints 预处理器 + control_instantid_sdxl, 主要负责构图?
controlNet unit 0 使用 instant_id_face_keypoints 预处理器 +control_instant_id_sdxl
high quality,masterpiece,rich details,realistic photography,8k,high-definition image quality,
watercolors portrait of a woman,artistry,
--- start-multi-column: ID_hdd8
Number of Columns: 4
Largest Column: standard

--- column-break ---

--- column-break ---

--- column-break ---

--- end-multi-column
切换不同风格, 即可生成同一个人的不同画风的头像
比如 instantid 如果用来做人物头像, 其实是没有问题的, 可以生成同一个人各种各样的人物头像. 或者是半身照, 证件照等等. 但是用作全身像时因为面部采样分配不足, 很难做到继续控制人物一致
第一张图捕捉脸, 第二张图可以控制构图
色彩相关模型
ReColor
Seg
语义分割, semantic Segmenttation Model. 是一种将标签或类别与图片的像素信息关联的一种深度学习算法
seg 绘画应该是未来的趋势, 但是还需要简化. 比起单纯用 prompt 描述画面, 如果未来可以通过 sketch seg + 标注描述画面, 那将绝杀. 需要一个自动取色器, prompt seg search 然后可以自动替换画笔颜色即可
利用语义分割去识别一张图片上的每个部分分别是什么东西
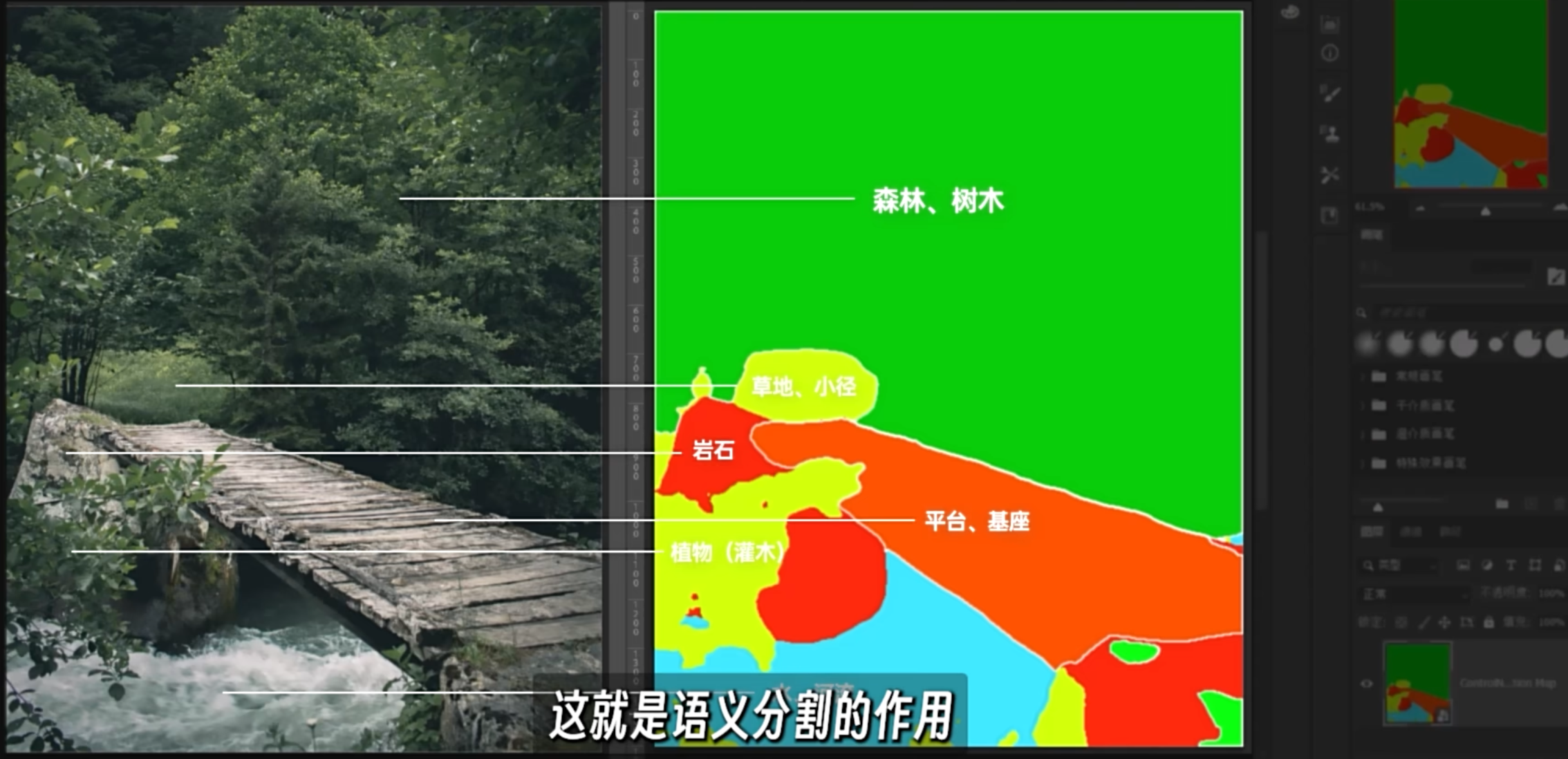
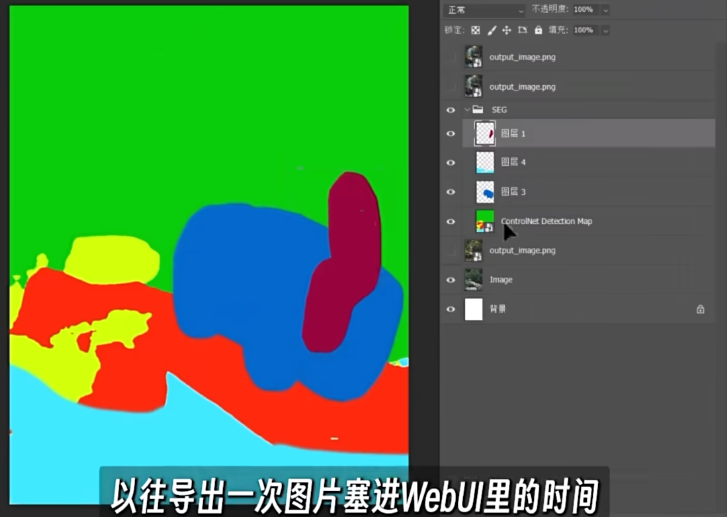
通过 ps 以及 seg, 完成语义分割的画作, 再使用 sd 生成成品
Multi ControlNet
Openpose + Depth
openpose 无法判断手在前还是在后. 而 Depth 可以识别.
权重的调节需要更加谨慎