mysql-basic
安装教程:https://www.jianshu.com/p/b4d64c9a5272
基础
概念
什么是数据库
数据库是持久化数据的一种介质,可以理解成用来存储和管理数据的仓库!
持久化(persistence):把数据保存到可掉电式存储设备中以供之后使用。持久化的大多数时候是将内存中的数据存储在数据库中,当然也可以存储在磁盘文件、XML 数据文件中。
为什么需要数据库
可将数据持久化到硬盘
可存储大量数据
方便检索
保证数据的一致性、完整性
安全,可共享
通过组合分析,可以产生新数据
术语
DB:数据库( database ):存储数据的“仓库”。它保存了一系列有组织的数据。
DBMS:数据库管理系统( Database Management System )。数据库是通过 DBMS 创
建和操作的容器
SQL:结构化查询语言( Structure Query Language ):专门用来与数据库通信的语言。
读音:Sequel
安装与卸载
卸载之前要先停止 mySQL 的服务,然后再卸载。
卸载之后还要删除剩余文件
重新安装即可,如果失败,还需要清楚注册表
常用快捷键
C+ENTER 执行当前行
C+S+ENTER
C+B 格式化
关系数据库
数据模型
数据库按照数据结构来组织、存储和管理数据,实际上,数据库一共有三种模型:
- 层次模型
- 网状模型
- 关系模型
存储数据的特点
将数据放到表中,表再放到库中
一个数据库中可以有多个表,每个表都有一个的名字,用来标识自己。表名具有唯一性。
表具有一些特性,这些特性定义了数据在表中如何存储,类似 java 中 “类”的设计。
表由列组成,我们也称为字段。所有表都是由一个或多个列组成的,每一列类似 java 中的”属性”
表中的数据是按行存储的,每一行类似于 java 中的“对象”
表——类
列,字段——属性
行——对象
基础语法
加号运算符
如果两个操作数都是数值,直接相加
如果其中一个是字符类型,则强制转换为数值,如果无法转换则当作 0
'abc' + 100 #100
如果其中一个是 null,则结果为 null
null + 100 #null
null + null #null
注释
单行注释: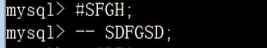
多行注释: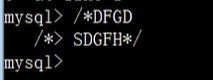
注释不能嵌套
SQL 命令
系统操作
修改字符集,mysql 服务器的默认字符集是 utf8,不支持插入中文数据

导出数据库文件:mysqldump -u 用户名 –p 数据库名 > 导出的文件名;
cmd ,mysql -u root -p 输入密码登陆 root 账号,打开 mysql
退出 MySQL,使用 EXIT 命令退出 MySQL:
mysql> EXIT;
注意 EXIT 仅仅断开了客户端和服务器的连接,MySQL 服务器仍然继续运行。
也可以在 mac 下的系统偏好最下面找到 mysql 进行操作
SQL 语句概述
什么是 SQL
SQL(Structured Query Language)是“结构化查询语言”,它是对关系型数据库的操作语言。它可以应用到所有关系型数据库中,例如:MySQL、Oracle、SQL Server 等。SQL 标准有:
- 1986 年,ANSI X3.135-1986,ISO/IEC 9075:1986,SQL-86
- 1989 年,ANSI X3.135-1989,ISO/IEC 9075:1989,SQL-89
- 1992 年,ANSI X3.135-1992,ISO/IEC 9075:1992,SQL-92(SQL2)
- 1999 年,ISO/IEC 9075:1999,SQL:1999(SQL3)
- 2003 年,ISO/IEC 9075:2003,SQL:2003
- 2008 年,ISO/IEC 9075:2008,SQL:2008
- 2011 年,ISO/IEC 9075:2011,SQL:2011
- 2016 年,ISO/IEC 9075:2016,SQL:2016
这些标准就与 JDK 的版本一样,在新的版本中总要有一些语法的变化。不同时期的数据库对不同标准做了实现。
虽然 SQL 可以用在所有关系型数据库中,但很多数据库还都有标准之后的一些语法,我们可以称之为“方言”。例如 MySQL 中的 LIMIT 语句就是 MySQL 独有的方言,其它数据库都不支持!当然,Oracle 或 SQL Server 都有自己的方言。
语法要求
SQL 语句可以单行或多行书写,以分号结尾;
可以用空格和缩进来来增强语句的可读性;
关键字不区别大小写,建议使用大写;
分类
- DDL(Data Definition Language):数据定义语言,用来定义数据库对象:库、表、列等;
- DML(Data Manipulation Language):数据操作语言,用来定义数据库记录(数据);
- DCL(Data Control Language):数据控制语言,用来定义访问权限和安全级别;
- DQL(Data Query Language):数据查询语言,用来查询记录(数据)。
DDL
DATABASE
在 mysql 中 CREATE DATABASE 和 CREATE SCHEMA 是一样的
CREATE DATABASE IF NO EXISTS sql_store;
DROP DATABASE IF EXISTS sql_store;
SHOW DATABASE; -- 查看所有的数据库
SELECT DATABASE(); -- 查看当前所处的数据库
TABLE
基础
SHOW TABLE; -- 查看所有的数据库
CREATE TABLE order_archived AS
SELECT * FROM orders -- 通过这种方法创建的表,mysql不会记录主键和自增等特性
建表
CREATE DATABASE IF NO EXISTS sql_store;
USE sql_store;
CREATE TABLE IF NO EXISTS customers
(
customer_id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50) NOT NULL,
points INT NOT NULL DEFAULT 0,
emial VARCHAR(255) NOT NULL UNIQUE
);
修改表
ALTER TABLE IF NO EXISTS customers
ADD last_name VARCHAR(50) NOT NULL AFTER first_name,
ADD city VARCHAR(50) NOT NULL ,
MODIFY COLUMN first_name VARCHAR(255) DEFAULT '',
DROP points
;
创建关系
CREATE DATABASE IF NO EXISTS sql_store;
USE sql_store;
-- orders 需要位于 customers 之前,因为 customers 被 orders 的关系绑定了导致无法直接删除
DROP TABLE IF EXISTS orders;
DROP TABLE IF EXISTS customers;
CREATE TABLE IF NO EXISTS customers
(
customer_id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50) NOT NULL,
points INT NOT NULL DEFAULT 0,
emial VARCHAR(255) NOT NULL UNIQUE
);
CREATE TABLE orders (
-- 主键默认非空
order_id INT PRIMARY KEY AUTO_INCREMENT,
customer_id INT NOT NULL,
FOREIGN KEY fk_orders_customers (customer_id)
REFERENCES customers (customer_id)
ON UPDATE CASCADE
ON DELETE NO ACTION
)
更改主键和外键约束
ALTER TABLE IF NO EXISTS customers
ADD last_name VARCHAR(50) NOT NULL AFTER first_name,
ADD city VARCHAR(50) NOT NULL ,
MODIFY COLUMN first_name VARCHAR(255) DEFAULT '',
DROP points
;
ALTER TABLE IF NO EXISTS orders
DROP PRIMARY KEY,
ADD PRIMARY KEY (order_id),
DROP FOREIGN KEY fk_orders_customers,
ADD FOREIGN KEY fk_orders_custoemrs (customer_id)
REFERENCES customers (customer_id)
ON UPDATE CASCADE
ON DELETE NO ACTION;
字符集和排序规则
基础
SHOW CHARSET;
CREATE DATABASE db_name
CHARACTER SET utf-8;
ALTER DATABASE db_name
CHARACTER SET utf-8;
CREATE TABLE tb_name
(
)
CHARACTER SET utf-8;
ALTER TABLE tb_name
CHARACTER SET utf-8;
存储引擎
SHOW ENGINES
DQL
概念
DQL 就是数据查询语言,数据库执行 DQL 语句不会对数据进行改变,而是让数据库发送结果集给客户端。
语句执行顺序一览
SELECT
selection_list /*要查询的列名称*/
FROM
table_list /*要查询的表名称*/
WHERE
condition /*行条件*/
GROUP BY
grouping_columns /*对结果分组*/
HAVING
condition /*分组后的行条件*/
ORDER
BYsorting_columns /*对结果分组*/
LIMIT
offset_start, row_count /*结果限定*/
基础查询
基础查询语句
SELECT selection_list FROM table_list
特点
- 结果集是一个虚拟表
- 查询列表可以有多个,中间用逗号隔开
- 执行循序,先查看表是否存在,再筛选列
- from 子句
- select 子句
- 查询列表可以是字段、表达式、常量、函数等
- 使用
SELECT * FROM <表名> WHERE <条件>可以选出表中的若干条记录。我们注意到返回的二维表结构和原表是相同的,即结果集的所有列与原表的所有列都一一对应。 - 如果我们只希望返回某些列的数据,而不是所有列的数据,我们可以用
SELECT 列1, 列2, 列3 FROM ...,让结果集仅包含指定列。这种操作称为投影查询。
查询常量
select 100;
相当于打印,用的不多
查询表达式
select 100*3;
查询单个字段
select first_name from employees;
查询多个字段
SELECT first_name , last_name , employee_id FROM employees;
结果的顺序是查询的顺序,与表的结构本身的顺序无关
查询所有字段
SELECT *
查询函数
相当于是调用函数,获取返回值
SELECT database();
SELECT version();
SELECT user();
查询表的结构
使用 DESC 关键字
DESC employees;
使用 SHOW COLUMNS FROM
SHOW COLUMNS FROM employees;
跨数据库查询
可以查询其他 database 的表,只需要在表名前加上 database 的名字前缀即可
USE sql_store;
SELECT *
FROM sql_others.xxx
基础结果操作
运算
SELECT point + 10 FROM customers
返回的 point 值会全部加上 10,列名从 point 变成 point + 10
支持 加法、减法、乘法、除法、模除
别名
通过 as 关键字
SELECT user() AS 用户名;
SELECT user() AS "用户名";
SELECT user() AS '用户名';
当别名包含空格的时候必须使用引号
使用空格书写别名
SELECT user() 用户名;
SELECT user() "用户名";
SELECT user() '用户名';
如果其中一个为 null,最终的结果也是 null
条件子句
WHERE 关键字
核心语法:
SELECT 查询列表
FROM 表
WHERE 筛选条件
仅保留使得 WHERE 子句为 true 的结果
执行顺序:
- FROM 子句
- WHERE 子句
特点
- 按照关系表达式筛选,包括: < > <= >= = != <>(不等于)
- 按照逻辑表达式筛选,包括:&& || ! and or not
- 如果不加括号,条件运算按照
NOT、AND、OR的优先级进行,即NOT优先级最高,其次是AND,最后是OR。加上括号可以改变优先级。
示例
-
查找年龄不是在 50 到 100 之间的
# 方式一 SELECT FROM WHERE age < 50 OR age > 100 # 方式二 SELECT FROM WHERE NOT(age >= 50 AND age <= 100)
LIKE 关键字
- 功能:一般与通配符搭配查询,对字符型数据进行部分匹配查询
_:任意单个字符%:任意多个字符,0- 多个字符都可以- 还存在
not like,这个not like可以避免not加在WHERE之后,增强语义
示例
# 查询姓名中包含字母`a`的员工信息
SELECT *
FROM employees
WHERE last_name LIKE '%a%'
# 查询第一个
...
WHERE last_name LIKE 'a%'
#查询第三个
...
WHERE last_name LIKE '__a%'
#查询_本身
...
WHERE last_name LIKE '_\_%'
#ESCAPE关键字,自定义转义字符
...
WHERE last_name LIKE '_$_%' ESCAPE '$'
IN 关键字
查询某字段的值是否属于指定的列表之内
示例
# 查询部门编号是30/50/90的员工名,部门编号
...
WHERE department_id IN(30,50,90)
# 相当于
...
WHERE department_id = 30
OR department_id = 50
OR department_id = 90
NOT IN 示例
SELECT *
FROM products
WHERE product_id NOT IN (
SELECT DISTINCT product_id
FROM order_items
)
BETWEEN AND 关键字
查询某字段的值是否属于指定区间内,
区间的大小不能颠倒
# 部门编号 30-90之间
...
WHERE department_id BETWEEN 30 AND 90
# 等价于
WHERE department_id >=30 AND department_id <=90
ALL 关键字
要求 WHERE 子句,符合每一个
SELECT *
FROM invoices
WHERE invoice_total > (
SELECT MAX(invoice_total)
FROM invoices
WHERE client_id = 3
)
通过 ALL 关键字 重写 MAX 聚合函数
SELECT *
FROM invoices
WHERE invoice_total > ALL (
SELECT invoice_total
FROM invoices
WHERE client_id = 3
)
ANY 关键字
要求 WHERE 子句,符合任意一个
SELECT *
FROM clients
WHERE client_id IN (
SELECT client_id
FROM invoices
GROUP BY client_Id
HAVING COUNT(*) > 2
)
通过 ANY 重写 IN
SELECT *
FROM clients
WHERE client_id = ANY (
SELECT client_id
FROM invoices
GROUP BY client_Id
HAVING COUNT(*) > 2
)
IS NULL/ IS NOT NULL
\= 无法判断 null 值,只能通过 is null 关键字进行判断
<=>
既能判断 null 值,又能判断基本类型
但是因为意义不明,语义太差
其他子句
排序子句
语法:
SELECT 查询列表
FROM 表名
WHERE 筛选条件
ORDER BY 排序列表 ASC(DESC)
执行顺序:
- FROM 子句
- WHERE 子句
- SELECT 子句
- ORDER BY 子句
排序列表可以是单个字段、多个字段、别名、表达式、函数、列数,以及以上的组合
默认是升序,通过 ASC 关键字定义。降序,通过 DESC 关键字定义
示例
多个字段进行排序,权重分先后
# 按工资升序,按照部门id降序
...
ORDER BY salary ASC,department_id DESC;
按照列数排列
# 加入工资是第二列,直接写2即可
...
ORDER BY 2 ASC
分页子句
这个查询可以通过 LIMIT <M> OFFSET <N> 子句实现
select * from employees
LIMIT 10 OFFSET 0;
其中 M 是每一页的数量,N 用于指定页数,页数从 0 开始
OFFSET 超过了查询的最大数量并不会报错,而是得到一个空的结果集。
注意
OFFSET是可选的,如果只写LIMIT 15,那么相当于LIMIT 15 OFFSET 0。- 在 MySQL 中,
LIMIT 15 OFFSET 30还可以简写成LIMIT 30, 15。 - 使用
LIMIT OFFSET分页时,随着N越来越大,查询效率也会越来越低。 - LIMIT 要放在最后
多表查询
SELECT 查询不但可以从一张表查询数据,还可以从多张表同时查询数据。查询多张表的语法是:SELECT * FROM <表1> <表2>。
例如,同时从 students 表和 classes 表查询数据,可以这么写:
SELECT * FROM students, classes;
这种一次查询两个表的数据,查询的结果也是一个二维表,它是 students 表和 classes 表的“乘积”,即 students 表的每一行与 classes 表的每一行都两两拼在一起返回。结果集的列数是 students 表和 classes 表的列数之和,行数是 students 表和 classes 表的行数之积。
这种多表查询又称笛卡尔查询,使用笛卡尔查询时要非常小心,由于结果集是目标表的行数乘积,对两个各自有 100 行记录的表进行笛卡尔查询将返回 1 万条记录,对两个各自有 1 万行记录的表进行笛卡尔查询将返回 1 亿条记录。
多表查询的同名字段可以通过别名来处理
SELECT
students.id sid,
students.name,
students.gender,
students.score,
classes.id cid,
classes.name cname
FROM students, classes;
注意,多表查询时,要使用 表名.列名 这样的方式来引用列和设置别名,这样就避免了结果集的列名重复问题。但是,用 表名.列名 这种方式列举两个表的所有列实在是很麻烦,所以 SQL 还允许给表设置一个别名,让我们在投影查询中引用起来稍微简洁一点:
SELECT
s.id sid,
s.name,
s.gender,
s.score,
c.id cid,
c.name cname
FROM students s, classes c;
内连接查询
连接查询是另一种类型的多表查询。连接查询对多个表进行 JOIN 运算,简单地说,就是先确定一个主表作为结果集,然后,把其他表的行有选择性地“连接”在主表结果集上。
内链接
例如,我们想要选出 students 表的所有学生信息,可以用一条简单的 SELECT 语句完成:
但是,假设我们希望结果集同时包含所在班级的名称,上面的结果集只有 class_id 列,缺少对应班级的 name 列。
现在问题来了,存放班级名称的 name 列存储在 classes 表中,只有根据 students 表的 class_id,找到 classes 表对应的行,再取出 name 列,就可以获得班级名称。
这时,连接查询就派上了用场。我们先使用最常用的一种内连接——INNER JOIN 来实现:
SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.score
FROM students s
INNER JOIN classes c
ON s.class_id = c.id;
可以在表名后面跟上别名,缩写可以用于其他语句,例如 students 表,别名为 s,本质上是省略了 as
| id | name | class_id | class_name | gender | score |
|---|---|---|---|---|---|
| 1 | 小明 | 1 | 一班 | M | 90 |
| 2 | 小红 | 1 | 一班 | F | 95 |
| 3 | 小军 | 1 | 一班 | M | 88 |
| 4 | 小米 | 1 | 一班 | F | 73 |
| 5 | 小白 | 2 | 二班 | F | 81 |
| 6 | 小兵 | 2 | 二班 | M | 55 |
| 7 | 小林 | 2 | 二班 | M | 85 |
| 8 | 小新 | 3 | 三班 | F | 91 |
| 9 | 小王 | 3 | 三班 | M | 89 |
| 10 | 小丽 | 3 | 三班 | F | 88 |
注意 INNER JOIN 查询的写法是:
- 先确定主表,仍然使用
FROM <表1>的语法; - 再确定需要连接的表,使用
INNER JOIN <表2>的语法; - 然后确定连接条件,使用
ON <条件...>,这里的条件是s.class_id = c.id,表示students表的class_id列与classes表的id列相同的行需要连接; - 可选:加上
WHERE子句、ORDER BY等子句。
注意
- 当表中含有相同的列,需要加上表名.column 去做 SELECT
自连接
本质上是一种特殊的内连接
一张表的一个字段指向表中的另一个实体
最典型的就是 empolyee 表,有员工的汇报关系,然后上司也是公司的员工
SELECT
e.employee_id,
e.first_name,
m.first_name as manager
FROM sql_hr.employees e
JOIN sql_hr.employees m
ON e.reports_to = m.employee_id
多表连接
SELECT
o.order_id,
o.order_date,
c.first_name,
c.last_name,
os.name AS order_status
FROM orders o
JOIN customers c ON o.customer_id = c.customer_id
INNER JOIN order_statuses os ON o.status = os.order_status_id
复合连接 Compound Join Syntax
SELECT *
FROM order_items oi
JOIN order_item_notes oin
ON oi.order_id = oin.order_id
AND oi.product_id = oin.product_id
隐式连接 Implpicit Join Syntax
SELECT *
FROM orders o
JOIN customers c
ON o.customer_id = c.customer_id
SELECT *
FROM orders o, customers c
WHERE o.customer_id = c.customer_id
外连接查询
外连接
SELECT s.id, s.name, s.class_id, c.name class_name, s.gender, s.score
FROM students s
RIGHT OUTER JOIN classes c
ON s.class_id = c.id;
| id | name | class_id | class_name | gender | score |
|---|---|---|---|---|---|
| 1 | 小明 | 1 | 一班 | M | 90 |
| 2 | 小红 | 1 | 一班 | F | 95 |
| 3 | 小军 | 1 | 一班 | M | 88 |
| 4 | 小米 | 1 | 一班 | F | 73 |
| 5 | 小白 | 2 | 二班 | F | 81 |
| 6 | 小兵 | 2 | 二班 | M | 55 |
| 7 | 小林 | 2 | 二班 | M | 85 |
| 8 | 小新 | 3 | 三班 | F | 91 |
| 9 | 小王 | 3 | 三班 | M | 89 |
| 10 | 小丽 | 3 | 三班 | F | 88 |
| NULL | NULL | NULL | 四班 | NULL | NULL |
执行上述 RIGHT OUTER JOIN 可以看到,和 INNER JOIN 相比,RIGHT OUTER JOIN 多了一行,多出来的一行是“四班”,但是,学生相关的列如 name、gender、score 都为 NULL。
这也容易理解,因为根据 ON 条件 s.class_id = c.id,classes 表的 id=4 的行正是“四班”,但是,students 表中并不存在 class_id=4 的行。
使用了 RIGHT OUTER JOIN 会保证所有的 副表列被返回
OUTER 可省略
自外连接
多表外连接
SELECT
c.customer_id,
c.first_name,
o.order_id,
s.name as shipper
FROM customers c
LEFT JOIN orders o
ON c.customer_id = o.customer_id
LEFT JOIN shippers s
ON o.shipper_Id = s.shipper_id
ORDER BY c.customer_i
区别
有 RIGHT OUTER JOIN,就有 LEFT OUTER JOIN,以及 FULL OUTER JOIN。它们的区别是:
-
INNER JOIN 只返回同时存在于两张表的行数据,由于
students表的class_id包含 1,2,3,classes表的id包含 1,2,3,4,所以,INNER JOIN 根据条件s.class_id = c.id返回的结果集仅包含 1,2,3。 -
RIGHT OUTER JOIN 返回右表都存在的行。如果某一行仅在右表存在,那么结果集就会以
NULL填充剩下的字段。 -
LEFT OUTER JOIN 则返回左表都存在的行。如果我们给 students 表增加一行,并添加 class_id=5,由于 classes 表并不存在 id=5 的行,所以,LEFT OUTER JOIN 的结果会增加一行,对应的
class_name是NULL -
最后,我们使用 FULL OUTER JOIN,它会把两张表的所有记录全部选择出来,并且,自动把对方不存在的列填充为 NULL
USING 子句
SELECT *
FROM orders o
JOIN customers c
USING (customers_id)
通过 USING 某个 字段来 JOIN,相当于
SELECT *
FROM orders o
JOIN customers c
ON o.customers_id = c.customers_id
通过 USING 简化复合查询
SELECT *
FROM order_items oi
JOIN order_item_notes oin
USING (order_id, product_id)
SELECT *
FROM order_items oi
JOIN order_item_notes oin
ON oi.order_id = oin.order_id
AND oi.product_id = oin.product_id
* 自然连接
SELECT *
FROM orders o
NATURAL JOIN customers c
数据库自己判断如何连接两张表,连接的结果不可预测,因此不推荐使用
* 交叉连接
SELECT *
FROM orders o
CROSS JOIN customers c
返回 orders 中每条记录与 customers 中每条记录做组合,也就是返回排列组合的结果,笛卡尔积
UNION 子句
联合查询结果
SELECT *
FROM orders
WHERE order_date >= '2019-01-01'
UNION
SELECT *
FROM orders
WHERE order_date < '2019-01-01'
第一段查询决定了列名
两段查询返回的列数必须是一致的,否则无法 UNION,会报错
分组
如果我们要统计一班的学生数量,我们知道,可以用 SELECT COUNT(*) num FROM students WHERE class_id = 1;。如果要继续统计二班、三班的学生数量,难道必须不断修改 WHERE 条件来执行 SELECT 语句吗?
对于聚合查询,SQL 还提供了“分组聚合”的功能。我们观察下面的聚合查询:
SELECT COUNT(*) num FROM students GROUP BY class_id;
执行这个查询,COUNT() 的结果不再是一个,而是 3 个,这是因为,GROUP BY 子句指定了按 class_id 分组,因此,执行该 SELECT 语句时,会把 class_id 相同的列先分组,再分别计算,因此,得到了 3 行结果。
但是这 3 行结果分别是哪三个班级的,不好看出来,所以我们可以把 class_id 列也放入结果集中:
SELECT class_id, COUNT(*) num FROM students GROUP BY class_id;
注意
-
聚合查询的列中,只能放入分组的列。
SELECT name class_id, COUNT(*) num FROM students GROUP BY class_id; -
上面的例子想要插入 name 属性,但是根据
class_id分组后,每个分组只有 class_id 是相同的,SQL 引擎不能把多个name的值放入一行记录中
多列分组
也可以使用多个列进行分组。例如,我们想统计各班的男生和女生人数:
SELECT class_id, gender, COUNT(*) num FROM students GROUP BY class_id, gender;
HAVING 分组子条件
SELECT
client_id,
SUM(invoice_total) AS total_sales
FROM invoices
-- WHERE 此处无法使用where查询分组后聚合的数据,因为此时还没有分组完成,所以 total_sales 还不存在
GROUP BY client_id
HAVING total_sale >= 500
与 WHERE 的区别
使用 WHERE 可以做到在分组之前进行筛选,且 WHERE 只能筛选表中原本就存在的列
HAVING 只能选择在 SELECT 语句中出现的列
WITH ROLLUP 运算符
仅 mysql 下可以使用
SELECT
client_id,
SUM(invoice_total) AS total_sales
FROM invoices
-- WHERE 此处无法使用where查询分组后聚合的数据,因为此时还没有分组完成,所以 total_sales 还不存在
GROUP BY client_id WITH ROLLUP
HAVING total_sales >= 500
ROLLUP 会 SUM 聚合列的值
SELECT
state,
city,
SUM(invoice_total) AS total_sales
FROM invoices
JOIN clients USING (client_id)
-- WHERE 此处无法使用where查询分组后聚合的数据,因为此时还没有分组完成,所以 total_sales 还不存在
GROUP BY state, city WITH ROLLUP
HAVING total_sales >= 500
当我们使用多列进行分组时 ,rollup 会为每个列都分别 SUM,最终再计算所有列的 SUM
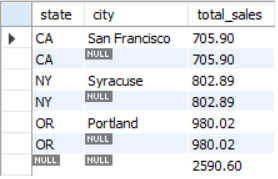
聚合函数 Aggregate Function
对于统计总数、平均数这类计算,SQL 提供了专门的聚合函数,使用聚合函数进行查询
COUNT() 函数
查询表一共有多少条记录
SELECT COUNT(*) FROM students;
COUNT(*) 表示查询所有列的行数,要注意聚合的计算结果虽然是一个数字,但查询的结果仍然是一个二维表,只是这个二维表只有一行一列,并且列名是 COUNT(*)。
通常,使用聚合查询时,我们应该给列名设置一个别名,便于处理结果:
SELECT COUNT(*) num FROM students;
COUNT(*) 和 COUNT(id) 实际上是一样的效果。另外注意,聚合查询同样可以使用 WHERE 条件,因此我们可以方便地统计出有多少男生、多少女生、多少 80 分以上的学生等。
COUNT 只会计算非 NULL 值,如果对于可为 NULL 的列做 COUNT,要注意
DISTINCT 关键字
SELECT
COUNT(DISTINCT customer_id) AS total
FROM invoices
通过 DISTINCT 关键字对 customer_id 去重,返回真正的客户数量
Number 聚合函数
| 函数 | 说明 |
|---|---|
| SUM | 计算某一列的合计值,该列必须为数值类型 |
| AVG | 计算某一列的平均值,该列必须为数值类型 |
| MAX | 计算某一列的最大值 |
| MIN | 计算某一列的最小值 |
注意,MAX() 和 MIN() 函数并不限于数值类型。如果是字符类型,MAX() 和 MIN() 会返回排序最后和排序最前的字符。
SELECT
SUM(invoice_total * 1.1 ) AS total
FROM invoices
**特别注意:**如果聚合查询的 WHERE 条件没有匹配到任何行,COUNT() 会返回 0,而 SUM()、AVG()、MAX() 和 MIN() 会返回 NULL。
String 聚合函数
GROUP_CONCAT(expr)
SELECT performance, GROUP_CONCAT(employee_name) AS employees
FROM employees
GROUP BY performance;
SELECT GROUP_CONCAT(DISTINCT home_town ORDER BY home_town DESC SEPARATOR '!') AS '领导关怀地区'
FROM employees;
复杂查询
子查询
基础子查询 Subquery
SELECT *
FROM products
WHERE unit_price > (
SELECT unit_price
FROM products
WHERE product_id = 3
)
子查询 可以通过一个小括号括起来,会先执行子查询获取子查询得结果,在执行外部的查询
此处就是先获取了 id 为 3 的产品的价格,再查询所有加个比 3 号大的产品
子查询也可以卸载 FROM 子句 或者 SELECT 子句等其他子句之后,本质上是一个运算结果及返回值的问题,有点类似于函数
子查询与连接
子查询和连接往往是实现同一份查询的两种可行方式
SELECT *
FROM clients
WHERE client_id NOT IN (
SELECT DISTINCT client_id
FROM invoices
);
通过连接重写
SELECT *
FROM clients
LEFT JOIN invoices USING (client_id)
WHERE invoice_id IS NULL
在实践中使用哪种方式取决于性能和可读性
相关子查询
基础示例
SELECT *
FROM employees e
WHERE salary > (
SELECT AVG(salary)
FROM empolyees
WHERE office_id = e.office_id
)
在子查询中引用了外部的 e.office_id ,相当于每 SELECT 一个数据,就得执行一次子查询,因为 e.office_id 一直在改变
EXISTS 关键字
SELECT *
FROM clients c
WHERE EXISTS (
SELECT client_id
FROM invoices
WHERE client_id = c.client_id
)
查看是否有符合条件的行
因为相关子查询的特性,每 SELECT 一个客户,就会对该客户的数据进行检查,是否符合条件
SELECT *
FROM clients
WHERE client_id IN (
SELECT DISTINCT client_id
FROM invoices
)
当子查询返回的结果过大时,会影响 IN 的查询效率
使用 EXISTS 对此做优化时,子查询并没有返回一个查询结果给外部查询。而是相当于做了一个其他表的条件判断,当符合条件时返回 true,此时外部判断也直接为 true
相同点:都是在查询 client_id 是否存在于一个表中,即需要对表做遍历
区别:
- IN 关键字,多生成了一个表
- EXSISTS 关键字,相当于直接在另一个表中做查询 (JOIN)
NOT EXSITS
NOT + EXSITS 关键字,组合起来理解稍微有点不同,本质上是给 EXSITS 的返回值取反
SELECT *
FROM clients c
WHERE NOT EXISTS (
SELECT client_id
FROM invoices
WHERE client_id = c.client_id
)
获取外部引用的 c.client_id,如果 client_id 存在,则返回 true,然后被 NOT 关键字 取反,最终 WHERE false
SELECT 语句 子查询
SELECT
invoice_id,
invoice_total,
(
SELECT AVG(invoice_total)
FROM invoices
) AS invoice_average,
invoice_total - (SELECT invoice_average)
FROM invoices
仅使用 AVG,此时返回的结果只有一行,但是使用子查询每次 SELECT 都会执行,最后返回的结果是多行
SELECT
AVG(invoice_total)
FROM invoices
FROM 语句 子查询
本质还是子查询返回了一张表,那自然可以在 FROM 语句之后对这张虚拟的表进行 SELECT
SELECT *
FROM (
SELECT
invoice_id,
invoice_total,
(
SELECT AVG(invoice_total)
FROM invoices
) AS invoice_average,
invoice_total - (SELECT invoice_average) AS difference
FROM invoices
) AS sales_summary
此时必须给返回的虚拟表一个别名
内置函数
内置函数的权衡
本质上从数据库获取数据,每一个 SELECT 语句都是一次遍历,如果在遍历的过程中直接使用内置函数处理一部分的数据,那样在后端或者前端就不需要再次处理了。相当于是可以节省一次遍历
Numeric Function
https://dev.mysql.com/doc/refman/8.0/en/numeric-functions.html
String Fucntion
https://dev.mysql.com/doc/refman/8.0/en/string-functions.html
Date & Time Function
https://dev.mysql.com/doc/refman/8.0/en/date-and-time-functions.html
格式化
DATE_FORMAT
SELECT TIME_FORMAT(NOW(), '%Y %M %d')
TIME_FORMAT
SELECT TIME_FORMAT(NOW(), '%H:%i %p')
计算
DATE_ADD
SELECT DATE_ADD(NOW(), INTERVAL 1 DAY)
DATE_SUB
SELECT DATE_SUB(NOW(), INTERVAL 1 YEAR)
DATE_DIFF,返回日期的间隔,不包含具体的时间
DATE_DIFF(subtrahend,minuend)
SELECT DATE_DIFF(NOW(), '2021-01-01')
TIME_TO_SEC,返回距离当天凌晨 00:00 间隔的秒数
SELECT TIME_TO_SEC('09:00')
Useful Function
IFNULL
接受两个参数,第一个参数为可能是 null 的值,第二个参数为如果是 null 时需要显示的值
SELECT IFNULL(A,'空') FROM employees;
COALESCE
vi. 合并; 联合; 结合;
接受多个参数,类似于可选链,如果前一个值为 NULL,则返回下一个值,直到最后
SELECT COALESCE(shipper_Id, commnets, 'Not assinged')
FROM orders
IF
IF(expression, trueValue, falseValue)
比起 IF 语句,其实 sql 的 if 函数更像是三目运算符
SELECT
order_id,
order_date,
IF(
YEAR(order_date) = YEAR(NOW()),
'Active',
'Archived'
)
FROM orders
CASE
多目运算符
SELECT
order_id,
CASE
WHEN YEAR(order_date) = YEAR(NOW()) THEN 'Active'
WHEN YEAR(order_date) = YEAR(NOW()) - 1 THEN 'Last Year'
WHEN YEAR(order_date) < YEAR(NOW()) - 1 THEN 'Archived'
ELSE 'Future'
END AS category
FROM orders
DML
INSERT
插入数据
当我们需要向数据库表中插入一条新记录时,就必须使用 INSERT 语句
insert into <表名> [( <字段名1>[,..<字段名n > ])] values (值1 )[, (值n )];

注意到我们并没有列出 id 字段,也没有列出 id 字段对应的值,这是因为 id 字段是一个自增主键,它的值可以由数据库自己推算出来。此外,如果一个字段有默认值,那么在 INSERT 语句中也可以不出现。
要注意,字段顺序不必和数据库表的字段顺序一致,但值的顺序必须和字段顺序一致。也就是说,可以写 INSERT INTO students (score, gender, name, class_id) ...,但是对应的 VALUES 就得变成 (80, 'M', '大牛', 2)。
还可以一次性添加多条记录,只需要在 VALUES 子句中指定多个记录值,每个记录是由 (...) 包含的一组值:
INSERT INTO students (class_id, name, gender, score) VALUES
(DEFAULT, '大宝', 'M', 87),
(2, '二宝', 'M', 81);
SELECT * FROM students;
INSERT INTO canon.character_pixiv_tag (date, tags) SELECT date, tags FROM canon.muses;
INSERT INTO canon_record.llss_seiyuu (date, type_id, member_Id, record) VALUES
('2022-04-29', 17, 80, 0),
('2022-04-29', 17, 81, 0),
('2022-04-29', 17, 82, 0),
('2022-04-29', 17, 83, 0)
;
插入分层数据 INSERT Hierarchical Rows
INSERT INTO orders (customer_id, order_date, status)
VALUES (1, '2019-01-02', '1');
INSERT INTO order_items
VALUES (last_insert_id(), 1, 1, 2.95),
(last_insert_id(), 2, 1, 3.95);
orders 表只存了订单的 id,具体订单购买的物品都存放在 order_items 表
因此新增一笔订单之后,需要在 order_items 新增 N 个该订单购买的物品
通过 laset_insert_id() 函数,获取新增的订单 id
UPDATE
如果要更新数据库表中的记录,我们就必须使用 UPDATE 语句。
UPDATE 语句的基本语法是:
UPDATE <表名> SET 字段1=值1, 字段2=值2, ... WHERE ...;

注意到 UPDATE 语句的 WHERE 条件和 SELECT 语句的 WHERE 条件其实是一样的,因此完全可以一次更新多条记录:
UPDATE students SET name='小牛', score=77 WHERE id>=5 AND id<=7;
-- 查询并观察结果:
SELECT * FROM students;
在 UPDATE 语句中,更新字段时可以使用表达式。例如,把所有 80 分以下的同学的成绩加 10 分:
UPDATE students SET score=score+10 WHERE score<80;
-- 查询并观察结果:
SELECT * FROM students;
异常
- 如果
WHERE条件没有匹配到任何记录,UPDATE语句不会报错,也不会有任何记录被更新
注意
- 最后,要特别小心的是,
UPDATE语句可以没有WHERE条件。 - 这时,整个表的所有记录都会被更新。所以,在执行
UPDATE语句时要非常小心,最好先用SELECT语句来测试WHERE条件是否筛选出了期望的记录集,然后再用UPDATE更新。
使用子查询
UPDATE invoices
SET
payment_total = invoice_total * 0.5,
payment_date = due_date
WHERE client_id IN (
SELECT client_id
FROM clients
WHERE location IN ('CA', 'NY')
)
DELETE
-
如果要删除数据库表中的记录,我们可以使用
DELETE语句。 -
DELETE语句的基本语法是:DELETE FROM <表名> WHERE ...;
-
注意到
DELETE语句的WHERE条件也是用来筛选需要删除的行,因此和UPDATE类似,DELETE语句也可以一次删除多条记录。 -
如果
WHERE条件没有匹配到任何记录,DELETE语句不会报错,也不会有任何记录被删除。 -
最后,要特别小心的是,和
UPDATE类似,不带WHERE条件的DELETE语句会删除整个表的数据
插入或替换
-
如果我们希望插入一条新记录(INSERT),但如果记录已经存在,就先删除原记录,再插入新记录。此时,可以使用
REPLACE语句,这样就不必先查询,再决定是否先删除再插入:REPLACE INTO students (id, class_id, name, gender, score) VALUES (1, 1, '小明', 'F', 99);若
id=1的记录不存在,REPLACE语句将插入新记录,否则,当前id=1的记录将被删除,然后再插入新记录。
插入或更新
-
如果我们希望插入一条新记录(INSERT),但如果记录已经存在,就更新该记录,此时,可以使用
INSERT INTO ... ON DUPLICATE KEY UPDATE ...语句:INSERT INTO students (id, class_id, name, gender, score) VALUES (1, 1, '小明', 'F', 99) ON DUPLICATE KEY UPDATE name='小明', gender='F', score=99;若
id=1的记录不存在,INSERT语句将插入新记录,否则,当前id=1的记录将被更新,更新的字段由UPDATE指定。
插入或忽略
-
如果我们希望插入一条新记录(INSERT),但如果记录已经存在,就啥事也不干直接忽略,此时,可以使用
INSERT IGNORE INTO ...语句:INSERT IGNORE INTO students (id, class_id, name, gender, score) VALUES (1, 1, '小明', 'F', 99);若
id=1的记录不存在,INSERT语句将插入新记录,否则,不执行任何操作。
快照
-
如果想要对一个表进行快照,即复制一份当前表的数据到一个新表,可以结合
CREATE TABLE和SELECT:-- 对class_id=1的记录进行快照,并存储为新表students_of_class1: CREATE TABLE students_of_class1 SELECT * FROM students WHERE class_id=1;新创建的表结构和
SELECT使用的表结构完全一致。
写入查询结果集
-
如果查询结果集需要写入到表中,可以结合
INSERT和SELECT,将SELECT语句的结果集直接插入到指定表中。例如,创建一个统计成绩的表
statistics,记录各班的平均成绩:CREATE TABLE statistics ( id BIGINT NOT NULL AUTO_INCREMENT, class_id BIGINT NOT NULL, average DOUBLE NOT NULL, PRIMARY KEY (id) );然后,我们就可以用一条语句写入各班的平均成绩:
INSERT INTO statistics (class_id, average) SELECT class_id, AVG(score) FROM students GROUP BY class_id;确保
INSERT语句的列和SELECT语句的列能一一对应,就可以在statistics表中直接保存查询的结果:
强制使用指定索引
-
在查询的时候,数据库系统会自动分析查询语句,并选择一个最合适的索引。但是很多时候,数据库系统的查询优化器并不一定总是能使用最优索引。如果我们知道如何选择索引,可以使用
FORCE INDEX强制查询使用指定的索引。例如:> SELECT * FROM students FORCE INDEX (idx_class_id) WHERE class_id = 1 ORDER BY id DESC;指定索引的前提是索引
idx_class_id必须存在。
视图
概念
视图的层级与数据库表格一致,所以视图的 CREATE、DROP 等属于 DDL
只保存了 sql 逻辑,没有保存实际的数据,一般只用于查询,不会进行增删改
为了简化查询,通过把子查询保存为视图,可以复用子查询的结果
CREATE OR REPLACE VIEW sales_by_client AS
SELECT
c.client_id,
c.name,
SUM(invoice_total) AS total_sales
FROM clients c
JOIN invoices i USING (client_id)
GROUP BY client_id, name
优点
复用查询逻辑
可以减少数据库改动带来的影响,视图给表格提供了一层抽象
查询基于视图比基于表格更容易维护
一层模糊的权限,基于视图的修改不会影响到基础表格,相当于是增加了一层权限
可更新视图
-- DISTINCT
-- Aggregate Functions (MIN, MAX, SUM)
-- GROUP BY / HAVING
-- UNIONI
当视图没有使用上述语句时,被称为可更新视图,可以使用 DML 对视图进行更新
WITH CHECK OPTION
当更新视图或者删除视图时,可能会导致视图中的某些行不再符合视图创建的规则,比如 WHERE age > 18
如果想保持视图中的行不被剔除再最后加上关键字就好
CREATE OR REPLACE VIEW invoices_with_balance AS
SELECT
*,
invoice_total - payment_total as balance
FROM invoices
WHERE (invoice_total - payment_total) > 0
WITH CHECK OPTION
函数、存储过程、触发器、事件
存储过程
概念
存储过程是一个包含一堆 SQL 代码的数据库对象,在应用程序的代码中,我们以你改通过调用这些存储过程来获取和保存数据
大多数 DBMS 可以对存储过程里的代码做一些优化
同时也在一定程度上起到数据安全的作用,我们可以取消所有对表的直接访问权限,仅允许通过存储过程操作
mysql 的存储过程功能很弱(与商业数据库相比),同时互联网逻辑变化快,一般实践中会把这部分逻辑直接放在后端实现
基础示例
-- 临时切换分隔符,告诉mysql,将下述的语句当作一个整体,作为存储过程
DELIMITER $$
CREATE PROCEDURE get_invoice_with_balance()
BEGIN
SELECT *
FROM invoices_with_balance
WHERE balance > 0;
END $$
DELIMITER ;
也可以通过 GUI 的右键创建,此时只需要填写 sql 语句即可
参数
DROP PROCEDURE IF EXISTS get_clients_by_state
DELIMITER $$
CREATE PROCEDURE get_clients_by_state()
(
state CHAR(2)
)
BEGIN
-- 加上默认值
IF state IS NULL THEN
SET state = 'CA';
END IF;
SELECT *
FROM clients c
WHERE c.state = state;
END $$
DELIMITER ;
所有的参数都是必填的
CALL get_clients_by_state('VA')
DROP PROCEDURE IF EXISTS get_clients_by_state
DELIMITER $$
CREATE PROCEDURE get_clients_by_state()
(
state CHAR(2)
)
BEGIN
SELECT *
FROM clients c
-- 若为空,则返回所有值
WHERE c.state = IFNULL(state, c.state);
END $$
DELIMITER ;
参数验证
sql state errors:https://www.ibm.com/docs/en/db2-for-zos/11?topic=codes-sqlstate-values-common-error
IF payment_amount <=0 THEN
SIGNAL SQLSTATE '22003'
SET MESSAGE_TEXT = 'Invalid payment amount'
变量
局部变量
CREATE PROCEDURE get_risk_factor()
BEGIN
-- 声明变量
DECLARE risk_factor DECIMAL(9, 2) DEFAULT 0;
DECLARE invoices_total DECIMAL(9, 2);
DECLARE invoices_count INT:
-- 给变量赋值
SELECT COUNT(*), SUM(invoice_total)
INTO invoices_count, invoices_total
FROM invoices;
-- 给变量赋值
SET risk_facter = invoices_total / invoices_count * 5;
SELECT risk_facter;
END
函数
函数与储存过程有点像,区别在于函数只能返回单一的只,而存储过程可以返回多行和多列的结果集
基础示例
CREATE FUNCTION get_risk_factor_for_client
(
cliend_id INT
)
RETURNS INTEGER
-- 同样的输入,总是得到同样的输出
-- DETERMINISTIC
-- 代表着函数需要读取数据
READS SQL DATA
-- MODIFIES SQL DATA
BEGIN
-- 声明变量
DECLARE risk_factor DECIMAL(9, 2) DEFAULT 0;
DECLARE invoices_total DECIMAL(9, 2);
DECLARE invoices_count INT:
-- 给变量赋值
SELECT COUNT(*), SUM(invoice_total)
INTO invoices_count, invoices_total
FROM invoices i;
WHERE i.client_id = client_id
-- 给变量赋值
SET risk_facter = invoices_total / invoices_count * 5;
RETURN IFNULL(risk_facter, 0)
END;
SELECT
client_id,
name,
get_risk_factor_for_client(client_id)
FROM clients;
触发器 Trigger
当执行一些操作之前或者之后需要触发的逻辑,都可以放在 trigger
比如更新了购物车的内容之后,客户的消费总额也需要相应的更新
基础示例
DELIMITER $$
CREATE TRIGGER payments_after_insert
AFTER INSERT ON payments
FOR EACH ROW
BEGIN
UPDATE invoices
SET payment_total = payment_total + NEW.amount;
WHERE invoice_id = NEW.invoice_id
END $$
DELIMITER ;
SHOW TRIGGER
SHOW TRIGGER
DROP TRIGGER IF EXISTS
日志
通过 trigger 生成操作日志
DELIMITER $$
DROP TRIGGER IF EXISTS payments_after_insert
CREATE TRIGGER payments_after_insert
AFTER INSERT ON payments
FOR EACH ROW
BEGIN
UPDATE invoices
SET payment_total = payment_total + NEW.amount;
WHERE invoice_id = NEW.invoice_id
-- 记录操作日志
INSERT INTO payment_audit
VALUES (NEW.client_id, NEW.date, NEW.amount, 'Insert', NOW());
END $$
DELIMITER ;
事件 Events
事件是根据计划执行的任务或者一堆 SQL 代码,可以按照一定的规律执行,自动化维护 sql
查看事件调度器 Event Scheduler
SHOW VARIABLES LIKE 'event%';
SET GLOBAL event_scheduler = ON;
基础示例
DELIMITER $$
DROP EVENT IF EXISTS yearly_delete_state_audit_rows
CREATE EVENT yearly_delete_state_audit_rows
ON SCHEDULE
-- AT '2019-05-01'
EVERY 1 DAY STARTS '2019-01-01' END '2029-01-01'
DO BEGIN
-- 定时删除超过一年的审计记录
DELETE FROM payments_audit
WHERE actiono_date < NOW() - INTERVAL 1 YEAR
END $$
DELIMITER ;
查看事件
SHOW EVENTS
修改事件
ALTER EVENT yearly_delete_state_audit_rows DISABLE;
事务 Transaction
概述
在执行 SQL 语句的时候,某些业务要求,一系列操作必须全部执行,而不能仅执行一部分。
示例
例如,一个转账操作:
-- 从id=1的账户给id=2的账户转账100元
-- 第一步:将id=1的A账户余额减去100
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
-- 第二步:将id=2的B账户余额加上100
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
这两条 SQL 语句必须全部执行,或者,由于某些原因,如果第一条语句成功,第二条语句失败,就必须全部撤销。
这种把多条语句作为一个整体进行操作的功能,被称为数据库事务。数据库事务可以确保该事务范围内的所有操作都可以全部成功或者全部失败。如果事务失败,那么效果就和没有执行这些 SQL 一样,不会对数据库数据有任何改动
特性
数据库事务具有 ACID 这 4 个特性:
- A:Atomic,原子性,将所有 SQL 作为原子工作单元执行,要么全部执行,要么全部不执行;
- C:Consistent,一致性,事务完成后,所有数据的状态都是一致的,即 A 账户只要减去了 100,B 账户则必定加上了 100;
- I:Isolation,隔离性,如果有多个事务并发执行,每个事务作出的修改必须与其他事务隔离;
- D:Duration,持久性,即事务完成后,对数据库数据的修改被持久化存储。
基础操作
开始事务
对于单条 SQL 语句,数据库系统自动将其作为一个事务执行,这种事务被称为隐式事务。
SHOW VARIABLES LIKE 'autocommit';
要手动把多条 SQL 语句作为一个事务执行,使用 BEGIN 开启一个事务,使用 COMMIT 提交一个事务,这种事务被称为显式事务,例如,把上述的转账操作作为一个显式事务:
START TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
COMMIT;
很显然多条 SQL 语句要想作为一个事务执行,就必须使用显式事务。
COMMIT 是指提交事务,即试图把事务内的所有 SQL 所做的修改永久保存。如果 COMMIT 语句执行失败了,整个事务也会失败。
USE sql_store;
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
SELECT points
FROM customers
WHERE customer_id = 1;
此处设置了事务的隔离级别为 UNCOMMITTED,因为隐式事务,所以下一条 SQL 语句会处于该隔离级别
ROLLBACK 回滚事务
有些时候,我们希望主动让事务失败,这时,可以用 ROLLBACK 回滚事务,整个事务会失败:
BEGIN;
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
ROLLBACK;
数据库事务是由数据库系统保证的,我们只需要根据业务逻辑使用它就可以。
并发和锁定
默认的锁机制
默认情况下 mysql 会为每个事务的操作行开启一个锁,如果有多个事物同时想要操作同一个行,则必须等到上一个事务完成或者 ROLLBACK
在 mysql 默认的机制下,大部分时候都不需要担心并发问题
https://www.bilibili.com/video/BV1UE41147KC?p=87&spm_id_from=pageDriver
这个默认的锁机制看着像是 serializable
这里的操作指的是同时进行更新或者删除?这个时候会默认进到 serializable?
死锁
两个事务都在等待对方,并永远没有释放锁
USE sql_store;
-- SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
START TRANSACTION;
UPDATE orders SET status = '1' WHERE order_id = 1;
UPDATE customers SET state = 'VA' WHERE customer_id = 1;
COMMIT;
USE sql_store;
-- SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
START TRANSACTION;
-- 锁定了该条记录 customers 1
UPDATE customers SET state = 'VA' WHERE customer_id = 1;
UPDATE orders SET status = '1' WHERE order_id = 1;
COMMIT;
相反的顺序更新表格,很容易出现死锁
尽量简化事务,事务执行的时间越长,越有可能与其他事务发生冲突
如果事务的执行时长无法减少,则考虑把该事务挪动到用户不活跃的时间执行
丢失更新
当没有使用锁时,较晚提交的事务会覆盖较早提交的事务的更改,有可能会导致更新丢失
例如:一个事务想要更新顾客的积分,一个事务想要更新顾客的个人信息
隔离级别
概述
对于两个并发执行的事务,如果涉及到操作同一条记录的时候,可能会发生问题。因为并发操作会带来数据的不一致性,包括脏读、不可重复读、幻读等。数据库系统提供了隔离级别来让我们有针对性地选择事务的隔离级别,避免数据不一致的问题。
SQL 标准定义了 4 种隔离级别,分别对应可能出现的数据不一致的情况:
| Isolation Level | 丢失更新(Lost Updates) | 脏读(Dirty Read) | 不可重复读(Non Repeatable Read) | 幻读(Phantom Read) |
|---|---|---|---|---|
| Read Uncommitted | Yes | Yes | Yes | Yes |
| Read Committed | Yes | - | Yes | Yes |
| Repeatable Read | - | - | - | Yes |
| Serializable | - | - | - | - |
我们会依次介绍 4 种隔离级别的数据一致性问题。
Read Uncommitted
Read Uncommitted 是隔离级别最低的一种事务级别。在这种隔离级别下,一个事务会读到另一个事务更新后但未提交的数据,如果另一个事务回滚,那么当前事务读到的数据就是脏数据,这就是脏读(Dirty Read)。
脏读(Dirty Read)
-
首先,我们准备好
students表的数据,该表仅一行记录:mysql> select * from students; +----+-------+ | id | name | +----+-------+ | 1 | Alice | +----+-------+ 1 row in set (0.00 sec) -
然后,分别开启两个 MySQL 客户端连接,按顺序依次执行事务 A 和事务 B:
| 时刻 | 事务 A | 事务 B |
|---|---|---|
| 1 | SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; | SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED; |
| 2 | BEGIN; | BEGIN; |
| 3 | UPDATE students SET name = 'Bob' WHERE id = 1; | |
| 4 | SELECT * FROM students WHERE id = 1; | |
| 5 | ROLLBACK; | |
| 6 | SELECT * FROM students WHERE id = 1; | |
| 7 | COMMIT; |
- 当事务 A 执行完第 3 步时,它更新了
id=1的记录,但并未提交,而事务 B 在第 4 步读取到的数据就是未提交的数据。 - 随后,事务 A 在第 5 步进行了回滚,事务 B 再次读取
id=1的记录,发现和上一次读取到的数据不一致,这就是脏读。
可见,在 Read Uncommitted 隔离级别下,一个事务可能读取到另一个事务更新但未提交的数据,这个数据有可能是脏数据。
Read Committed
为了解决脏读(Dirty Read)的问题,我们可以使用 Read Committed 隔离级别。在此级别下事务只能读取到已经提交的数据。
不可重复读(Non Repeatable Read)
- 在 Read Committed 隔离级别下,一个事务可能会遇到不可重复读(Non Repeatable Read)的问题。
- 不可重复读是指,在一个事务内,多次读同一数据,在这个事务还没有结束时,如果另一个事务恰好修改了这个数据,那么,在第一个事务中,两次读取的数据就可能不一致。
mysql> select * from students;
+----+-------+
| id | name |
+----+-------+
| 1 | Alice |
+----+-------+
1 row in set (0.00 sec)
- 然后,分别开启两个 MySQL 客户端连接,按顺序依次执行事务 A 和事务 B:
| 时刻 | 事务 A | 事务 B |
|---|---|---|
| 1 | SET TRANSACTION ISOLATION LEVEL READ COMMITTED; | SET TRANSACTION ISOLATION LEVEL READ COMMITTED; |
| 2 | BEGIN; | BEGIN; |
| 3 | SELECT * FROM students WHERE id = 1; | |
| 4 | UPDATE students SET name = 'Bob' WHERE id = 1; | |
| 5 | COMMIT; | |
| 6 | SELECT * FROM students WHERE id = 1; | |
| 7 | COMMIT; |
- 当事务 B 第一次执行第 3 步的查询时,得到的结果是
Alice,随后,由于事务 A 在第 4 步更新了这条记录并提交,所以,事务 B 在第 6 步再次执行同样的查询时,得到的结果就变成了Bob,因此,在 Read Committed 隔离级别下,事务不可重复读同一条记录,因为很可能读到的结果不一致。
Repeatable Read
为了解决不可重复读(Non Repeatable Read)的问题,我们可以使用 Repeatable Read 隔离级别。在此级别下事务只能读取到已经提交的数据。而且,读取的数据不会收到其他事务的更改影响,相当于是在事务开始前做了一个快照,后续事务的逻辑都通过快照读取数据。
幻读(Phantom Read)
- 在 Repeatable Read 隔离级别下,一个事务可能会遇到幻读(Phantom Read)的问题。
- 幻读是指,在一个事务中,第一次查询某条记录,发现没有,但是,当试图更新这条不存在的记录时,竟然能成功,并且,再次读取同一条记录,它就神奇地出现了。
- 我们在查询的过程中遗漏了部分数据,因为有其他事务正在更新他们,而我们没有意识到改事务的修改。这些遗漏的数据就像是 Phantom 幽灵,鬼魂 ghost
- 我们仍然先准备好
students表的数据:
mysql> select * from students;
+----+-------+
| id | name |
+----+-------+
| 1 | Alice |
+----+-------+
1 row in set (0.00 sec)
- 然后,分别开启两个 MySQL 客户端连接,按顺序依次执行事务 A 和事务 B:
| 时刻 | 事务 A | 事务 B |
|---|---|---|
| 1 | SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; | SET TRANSACTION ISOLATION LEVEL REPEATABLE READ; |
| 2 | BEGIN; | BEGIN; |
| 3 | SELECT * FROM students WHERE id = 99; | |
| 4 | INSERT INTO students (id, name) VALUES (99, 'Bob'); | |
| 5 | COMMIT; | |
| 6 | SELECT * FROM students WHERE id = 99; | |
| 7 | UPDATE students SET name = 'Alice' WHERE id = 99; | |
| 8 | SELECT * FROM students WHERE id = 99; | |
| 9 | COMMIT; |
- 事务 B 在第 3 步第一次读取
id=99的记录时,读到的记录为空,说明不存在id=99的记录。随后,事务 A 在第 4 步插入了一条id=99的记录并提交。事务 B 在第 6 步再次读取id=99的记录时,读到的记录仍然为空,但是,事务 B 在第 7 步试图更新这条不存在的记录时,竟然成功了,并且,事务 B 在第 8 步再次读取id=99的记录时,记录出现了。
可见,幻读就是没有读到的记录,以为不存在,但其实是可以更新成功的,并且,更新成功后,再次读取,就出现了。
Serializable
Serializable 是最严格的隔离级别。在 Serializable 隔离级别下,所有事务按照次序依次执行,因此,脏读、不可重复读、幻读都不会出现。
虽然 Serializable 隔离级别下的事务具有最高的安全性,但是,由于事务是串行执行,所以效率会大大下降,应用程序的性能会急剧降低。如果没有特别重要的情景,一般都不会使用 Serializable 隔离级别。
默认隔离级别
如果没有指定隔离级别,数据库就会使用默认的隔离级别。在 MySQL 中,如果使用 InnoDB,默认的隔离级别是 Repeatable Read。
设置隔离级别
SET SESSION TRANSACTION
SET GLOBAL TRANSACTION
索引 INDEXES
基础
概述
索引可以显著提高查询的性能
索引本质上是数据库用来快速查找数据的数据结构
特点
加快索引的速度:假如想要找到所有位于加州的顾客,如果没有索引,mysql 必须要进行一次遍历才能找出。为 state column 创建一个索引,就像是电话簿上按照名称排序一样。索引维护了 state column 到 customers 表的引用
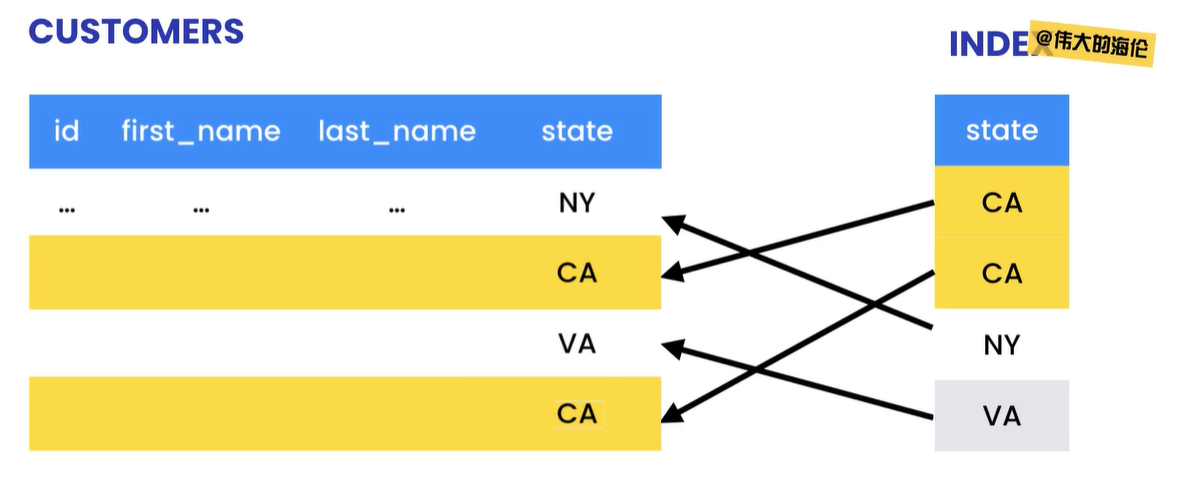
增加数据库的大小:索引必须永久的存储在表的旁边
对性能的负面影响:每次我们更新、添加、删除表的时候,mysql 都需要更新索引
综上:我们应该只为性能关键查询添加索引
基础示例
EXPLAIN
SELECT
customer_id
FROM sql_store.customers
WHERE state = 'CA';

type: ALL 代表着 mysql 会做全遍历
rows: 1010,代表着要扫描的行数
CREATE INDEX idx_state ON customers (state);
EXPLAIN
SELECT
customer_id
FROM sql_store.customers
WHERE state = 'CA';

查看索引
SHOW INDEXES IN customers;
主键会自动创建索引,主键的索引也被称为聚合索引,一级索引
我们手动创建的索引,被称为二级索引,二级索引会保存自身的索引值和主键
外键也会自动创建索引,也是二级索引,可以加快 join 的速度
索引的储存形式是 BTREE,二进制树
前缀索引
通过前缀字符串为建立字符串类型的数据建立索引
-- 指定合适的字符数
CREATE INDEX idx_lastname ON customers (last_name(20));
寻找合适的索引长度
SELECT COUNT(*) FROM customers;
SELECT
COUNT(DISTINCT LEFT(last_name, 1)), -- 25
COUNT(DISTINCT LEFT(last_name, 5)), -- 966
COUNT(DISTINCT LEFT(last_name, 10)), -- 996,增加了5位索引长度,却只新增了30位 unique,因此 5 比 10 更优
FROM customers;
全文索引
常用于文章搜索的场景
基础示例
USE sql_blog;
SELECT *
FROM posts
WHERE title LIKE '%react redux%' OR body LIKE '%react redux%'
全文索引包含整个字符串,而不仅仅是存储前缀。他们会忽略任何停止词,比如: in、on、the。本质上存储了一张单词表,同时存储了每个单词出现的行和记录
CREATE FULLTEXT INDEX idx_title_body ON posts (title,body);
SELECT
*,
MATCH(title, body) AGAINST('react redux') -- 返回值即是相关性得分
FROM posts
WHERE MATCH(title, body) AGAINST('react redux');
使用两个内置函数来支持全文索引,上述查询会返回在 title 和 body 两列中,包含一个或多个关键词的文章
关键词可以以任意顺序、也可以被一个或多个单词分隔
全文索引 自带 相关性得分
布尔模式
全文索引有两种模式,默认的自然模式。另一种是布尔模式,该模式下可以包括或者排除某些单词
CREATE FULLTEXT INDEX idx_title_body ON posts (title,body);
SELECT
*,
MATCH(title, body) AGAINST('react redux')
FROM posts
WHERE MATCH(title, body) AGAINST('react -redux +form' IN BOOLEAN MODE);
在关键词前添加一个负号,表示不包含
添加正号,表示在每一列中,都必须包含关键词 form
WHERE MATCH(title, body) AGAINST('"muset include exactly text"' IN BOOLEAN MODE);
必须完全包含指定的字符串
复合索引
基础示例
USE sql_store;
CREATE INDEX idx_state ON customers (state);
CREATE INDEX idx_points ON customers (points);
EXPLAIN
SELECT
customer_id
FROM sql_store.customers
WHERE state = 'CA' AND points > 1000;
多种索引的情况下,mysql 也只会使用单一索引

上例中因为 state 的索引更加精准,所以 mysql 会先使用 state 索引定位,然后再全遍历 idx_state 查找 points > 1000
因此需要复合索引,对多列建立索引
USE sql_store;
CREATE INDEX idx_state_points ON customers (state, points);
EXPLAIN
SELECT
customer_id
FROM sql_store.customers
WHERE state = 'CA' AND points > 1000;

复合索引中的列顺序
越常用的列越靠前
索引集数高得靠前
索引查询技巧
以特定索引查询
USE sql_store;
EXPLAIN
SELECT
customer_id
FROM sql_store.customers
USE INDEX (idx_lastname_state)
WHERE state = 'CA' AND last_name LIKE 'A%';
一般而言,lastname 的索引基数会更大,但是在上述特定的查询中,因为 state 是强指定的,而此时 last_name 更加宽泛,此时复合索引中先使用 state 效率会更高
拆分查询以匹配索引
USE sql_store;
EXPLAIN
SELECT
customer_id
FROM sql_store.customers
WHERE state = 'CA' OR points > 1000;

使用索引,进行了一次全遍历,虽然会比直接查表快,但是依然是全遍历
因为是 OR 查询,因此拆分查询,使用不同的索引,是一个可以考虑的方案
USE sql_store;
-- CREATE INDEX idx_points ON customers (points);
EXPLAIN
SELECT
customer_id
FROM sql_store.customers
WHERE state = 'CA'
UNION
SELECT
customer_id
FROM customers
WHERE points > 1000;

primary 主查询,使用了 idx_state,扫描了 112 行
unioin 联合查询,使用了 idx_points,扫描了 529
表达式使得索引失效
USE sql_store;
EXPLAIN
SELECT
customer_id
FROM customers
WHERE points + 10 > 1010;
覆盖索引
如果索引中包含的列覆盖了查询需要返回的所有信息,该索引即是覆盖索引。此时 mysql 仅会在索引中做查询,不会读取表
使用索引排序
基础示例
当我们为某列创建了索引,mysql 在索引中就已经进行了一次排序
USE sql_store;
EXPLAIN
SELECT
customer_id
FROM customers
ORDER BY points;
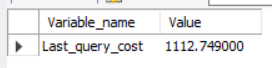
SHOW STATUS LIKE 'last_query_cost';


如果排序的列没有索引,则 mysql 会使用 filesort 这个算法对返回值进行排序,该算法性能消耗较大
USE sql_store;
EXPLAIN
SELECT
customer_id
FROM customers
ORDER BY first_name;
SHOW STATUS LIKE 'last_query_cost';

查询排序与索引排序匹配
USE sql_store;
EXPLAIN
SELECT
customer_id
FROM customers
ORDER BY state, points DESC;
SHOW STATUS LIKE 'last_query_cost';
idx_state_points 默认是升序创建的索引,而查询是降序的,与索引不匹配,依然会影响查询的效率

可以看到,先使用了 index 类型,查询,然后又使用了 filesort
本质:查询如果可以匹配索引,那么就可以直接使用索引的排序
- 对于索引 (a , b):
- a
- a , b
- a DESC , b DESC
USE sql_store;
EXPLAIN
SELECT
customer_id
FROM customers
ORDER BY state DESC, points DESC; -- 索引 idx_staet_points 的逆序
SHOW STATUS LIKE 'last_query_cost';
USE sql_store;
EXPLAIN
SELECT
customer_id
FROM customers
WHERE state = 'ca'
ORDER BY points DESC; -- 索引 idx_staet_points 在单个 state 中 points 已排序
SHOW STATUS LIKE 'last_query_cost';
数据类型
概述
基本分类如下:
- String Types
- Numeric Types
- Date and Time Types
- Blob Types
- Spatial Types
Mysql Int Size
SMALLINT
https://www.techonthenet.com/mysql/datatypes.php
数据类型
对于一个关系表,除了定义每一列的名称外,还需要定义每一列的数据类型。关系数据库支持的标准数据类型包括数值、字符串、时间等:
| 名称 | 类型 | 说明 |
|---|---|---|
| INT | 整型 | 4 字节整数类型,范围约 +/-21 亿 |
| BIGINT | 长整型 | 8 字节整数类型,范围约 +/-922 亿亿 |
| REAL | 浮点型 | 4 字节浮点数,范围约 +/-1038 |
| DOUBLE | 浮点型 | 8 字节浮点数,范围约 +/-10308 |
| DECIMAL(M,N) | 高精度小数 | 由用户指定精度的小数,例如,DECIMAL(20,10) 表示一共 20 位,其中小数 10 位,通常用于财务计算 |
| CHAR(N) | 定长字符串 | 存储指定长度的字符串,例如,CHAR(100) 总是存储 100 个字符的字符串 |
| VARCHAR(N) | 变长字符串 | 存储可变长度的字符串,例如,VARCHAR(100) 可以存储 0~100 个字符的字符串,优化空间 |
| BOOLEAN | 布尔类型 | 存储 True 或者 False |
| DATE | 日期类型 | 存储日期,例如,2018-06-22。字符串类型的 YYYY-MM-DD 可以直接用于运算 |
| TIME | 时间类型 | 存储时间,例如,12:20:59 |
| DATETIME | 日期和时间类型 | 存储日期 + 时间,例如,2018-06-22 12:20:59 |
| JSON | JSON 类型 |
上面的表中列举了最常用的数据类型。很多数据类型还有别名,例如,REAL 又可以写成 FLOAT(24)。还有一些不常用的数据类型,例如,TINYINT(范围在 0~255)。各数据库厂商还会支持特定的数据类型,例如 JSON。
选择数据类型的时候,要根据业务规则选择合适的类型。通常来说,BIGINT 能满足整数存储的需求,VARCHAR(N) 能满足字符串存储的需求,这两种类型是使用最广泛的。
字符串类型
CHAR() 和 VARCHART()
各个区间内的字符串使用的长度统一
对于用户名和密码,可以统一使用 VARCHART(50)
对于地址这类更长的字符串,可以统一使用 VARCHART(255)
max: 65535 (~64KB)
| 名称 | 类型 | 说明 |
|---|---|---|
| CHAR(N) | 定长字符串 | 存储指定长度的字符串,例如,CHAR(100) 总是存储 100 个字符的字符串 |
| VARCHAR(N) | 变长字符串 | 存储可变长度的字符串,例如,VARCHAR(100) 可以存储 0~100 个字符的字符串,优化空间 |
| MEDIUMTEXT | max:16MB | |
| LONGTEXT | max:4GB | |
| TINYTEXT | max:255 bytes | |
| TEXT | max:64kb |
BTYES
mysql 支持国际语言,英语 1 个字节,中东和欧洲语言 2 个字节,中文和日文 3 个字节
因此 CHAR(10),将会预留 30 个字节,以支持国际语言
数值类型
整数类型 Integer Types
| 名称 | 说明 |
|---|---|
| INT | 4 字节整数类型,范围约 +/-21 亿 |
| BIGINT | 8 字节整数类型,范围约 +/-922 亿亿 |
| TINYINT | 1 字节,[-128, 127] |
| UNSIGNED TINYINT | 1 字节,[0, 255],常用于存储年龄 |
| SMALLINT | 2B, [-32K, 32K] |
| MEDIUMINT | 3B, |
当储存的数值超出了类型的范围,Mysql 会提示操作失败
前导零 ZEROFILL
定义数值列的时候,我们可以在括号中显示指定大小
INT(4) 0001,只影响 mysql 的显示,不影响 mysql 存储
定点数和浮点数类型 Fixed-point and Floating-point Types
| 名称 | 类型 | 说明 |
|---|---|---|
| REAL / FLOAT(4) | 浮点型 | 4 字节浮点数,范围约 +/-1038,在科学计算中处理特别大或者特别小的数,精度不咋重要 |
| DOUBLE | 浮点型 | 8 字节浮点数,范围约 +/-10308,在科学计算中处理特别大或者特别小的数,精度不咋重要 |
| DECIMAL(precision, scale) | 高精度小数 | 由用户指定精度的小数,例如,DECIMAL(20,10) 表示一共 20 位,其中小数 10 位,通常用于财务计算 精度明确了最大的位数,介于 1 和 65 |
布尔类型
| 名称 | 类型 | 说明 |
|---|---|---|
| BOOLEAN | 布尔类型 | 存储 True 或者 False |
布尔类型其实也是 1 为真,0 为 false。其实可以用 TINYINT 代替
枚举和集合类型
ENUM('small', 'medium', 'large')
SET()
改变枚举类型的成员成本很高,不太推荐使用
如果有其他地方使用到了相同的枚举值,每次修改必须全部一起改动
更好的方案是新建一张枚举表,枚举值同表中获取,表扩展起来也非常方便
日期和时间类型
| 名称 | 类型 | 说明 |
|---|---|---|
| DATE | 日期类型 | 存储日期,例如,2018-06-22。字符串类型的 YYYY-MM-DD 可以直接用于运算 |
| TIME | 时间类型 | 存储时间,例如,12:20:59 |
| DATETIME | 日期和时间类型 | 存储日期 + 时间,例如,2018-06-22 12:20:59 |
| TIMESTAMP | 4 个字节,2038 年问题 | |
| YAER |
Blob 二进制长对象
| 名称 | 说明 |
|---|---|
| TINYBOLB | 255b 的二进制数据 |
| BLOB | 65KB 的二进制数据 |
| MEDIUMBLOP | 16MB |
| LONGBLOB | 4GB |
一般来说不要把图片、视频等二进制内容储存到数据库中,因为 mysql 是关系型数据库,读取文件的速度总是慢于文件系统
JSON 类型
JSON_OBJECT()
UPDATE products
SET properties = JSON_OBJECT(
'weight', 10,
'dimensions', JSON_ARRAY(1,2,3),
'manufacturer', JSON_OBJECT('name', 'sony')
)
WHERE product_id = 1;
读取 JSON 的键值对
SELECT product_id, JSON_EXTRACT(properties, '$.weight')
FROM products
WHERE product_id = 1;
-- 列路径操作符
SELECT product_id, properties -> '$.dimensions[1]'
FROM products
WHERE product_id = 1;
-- 列路径操作符,且返回值不带双引号
SELECT product_id, properties ->> '$.manufacturer.name'
FROM products
WHERE properties ->> '$.manufacturer.name' = 'sony';
更新 JSON 的字段
UPDATE products
SET properties = JSON_SET(
properties,
'$.weight', 20,
'$.age', 10,
)
WHERE product_id = 1;
UPDATE products
SET properties = JSON_REMOVE(
properties,
'$.age'
)
WHERE product_id = 1;
关系型数据库
概述
我们已经知道,关系数据库是建立在关系模型上的。而关系模型本质上就是若干个存储数据的二维表,可以把它们看作很多 Excel 表。
表的每一行称为记录(Record),记录是一个逻辑意义上的数据。
表的每一列称为字段(Column),同一个表的每一行记录都拥有相同的若干字段。
字段定义了数据类型(整型、浮点型、字符串、日期等),以及是否允许为 NULL。注意 NULL 表示字段数据不存在。一个整型字段如果为 NULL 不表示它的值为 0,同样的,一个字符串型字段为 NULL 也不表示它的值为空串 ''。
通常情况下,字段应该避免允许为 NULL。不允许为 NULL 可以简化查询条件,加快查询速度,也利于应用程序读取数据后无需判断是否为 NULL。
关系数据库的表和表之间需要建立“一对多”,“多对一”和“一对一”的关系,这样才能够按照应用程序的逻辑来组织和存储数据。
在关系数据库中,关系是通过主键和外键来维护的。我们在后面会分别深入讲解。
实体
主键
对于关系表,有个很重要的约束,就是任意两条记录不能重复。重复不是指两条记录完全相同,而是指能够通过某个字段唯一区分出不同的记录,这个字段被称为主键。
例如,假设我们把 name 字段作为主键,那么通过名字 小明 或 小红 就能唯一确定一条记录。但是,这么设定,就没法存储同名的同学了,因为插入相同主键的两条记录是不被允许的。
对主键的要求,最关键的一点是:记录一旦插入到表中,主键最好不要再修改,因为主键是用来唯一定位记录的,修改了主键,会造成一系列的影响。
由于主键的作用十分重要,如何选取主键会对业务开发产生重要影响。
如果我们以学生的身份证号作为主键,似乎能唯一定位记录。然而,身份证号也是一种业务场景,如果身份证号升位了,或者需要变更,作为主键,不得不修改的时候,就会对业务产生严重影响。
所以,选取主键的一个基本原则是:不使用任何业务相关的字段作为主键。
因此,身份证号、手机号、邮箱地址这些看上去可以唯一的字段,均不可用作主键。
作为主键最好是完全业务无关的字段,我们一般把这个字段命名为 id。常见的可作为 id 字段的类型有:
- 自增整数类型:数据库会在插入数据时自动为每一条记录分配一个自增整数,这样我们就完全不用担心主键重复,也不用自己预先生成主键;
- 全局唯一 GUID 类型:使用一种全局唯一的字符串作为主键,类似
8f55d96b-8acc-4636-8cb8-76bf8abc2f57。GUID 算法通过网卡 MAC 地址、时间戳和随机数保证任意计算机在任意时间生成的字符串都是不同的,大部分编程语言都内置了 GUID 算法,可以自己预算出主键。
对于大部分应用来说,通常自增类型的主键就能满足需求。我们在 students 表中定义的主键也是 BIGINT NOT NULL AUTO_INCREMENT 类型。
如果使用 INT 自增类型,那么当一张表的记录数超过 2147483647(约 21 亿)时,会达到上限而出错。使用 BIGINT 自增类型则可以最多约 922 亿亿条记录。
联合主键
关系数据库实际上还允许通过多个字段唯一标识记录,即两个或更多的字段都设置为主键,这种主键被称为联合主键。
对于联合主键,允许一列有重复,只要不是所有主键列都重复即可:
| id_num | id_type | other columns... |
|---|---|---|
| 1 | A | ... |
| 2 | A | ... |
| 2 | B | ... |
如果我们把上述表的 id_num 和 id_type 这两列作为联合主键,那么上面的 3 条记录都是允许的,因为没有两列主键组合起来是相同的。
没有必要的情况下,我们尽量不使用联合主键,因为它给关系表带来了复杂度的上升。
外键
当我们用主键唯一标识记录时,我们就可以在 students 表中确定任意一个学生的记录:
| id | name | other columns... |
|---|---|---|
| 1 | 小明 | ... |
| 2 | 小红 | ... |
我们还可以在 classes 表中确定任意一个班级记录:
| id | name | other columns... |
|---|---|---|
| 1 | 一班 | ... |
| 2 | 二班 | ... |
但是我们如何确定 students 表的一条记录,例如,小明,属于哪个班级呢?
由于一个班级可以有多个学生,在关系模型中,这两个表的关系可以称为“一对多”,即一个 classes 的记录可以对应多个 students 表的记录。
为了表达这种一对多的关系,我们需要在 students 表中加入一列 class_id,让它的值与 classes 表的某条记录相对应:
| id | class_id | name | other columns... |
|---|---|---|---|
| 1 | 1 | 小明 | ... |
| 2 | 1 | 小红 | ... |
| 5 | 2 | 小白 | ... |
这样,我们就可以根据 class_id 这个列直接定位出一个 students 表的记录应该对应到 classes 的哪条记录。
在 students 表中,通过 class_id 的字段,可以把数据与另一张表关联起来,这种列称为外键。
外键并不是通过列名实现的,而是通过定义外键约束实现的:
ALTER TABLE students
ADD CONSTRAINT fk_class_id
FOREIGN KEY (class_id)
REFERENCES classes (id);
其中,外键约束的名称 fk_class_id 可以任意,FOREIGN KEY (class_id) 指定了 class_id 作为外键,REFERENCES classes (id) 指定了这个外键将关联到 classes 表的 id 列(即 classes 表的主键)。
由于外键约束会降低数据库的性能,大部分互联网应用程序为了追求速度,并不设置外键约束,而是仅靠应用程序自身来保证逻辑的正确性。这种情况下,class_id 仅仅是一个普通的列,只是它起到了外键的作用而已。
要删除一个外键约束,也是通过 ALTER TABLE 实现的:
ALTER TABLE students
DROP FOREIGN KEY fk_class_id;
注意:删除外键约束并没有删除外键这一列。删除列是通过 DROP COLUMN ... 实现的。
外键约束 Foreign Key Consistance
On Update 添加外键级联, CASCADE,当主键发生改变的时候自动更新外键
RESTRICT 拒绝更新
SET NULL
NO ACITION
On Delete RESTICT,防止记录丢失
实际上, 外键约束也会影响性能, 据说直接通过列名约束就行
一对多
通过一个表的外键关联到另一个表,我们可以定义出一对多关系。
多对多
有些时候,还需要定义“多对多”关系。例如,一个老师可以对应多个班级,一个班级也可以对应多个老师,因此,班级表和老师表存在多对多关系。
多对多关系实际上是通过两个一对多关系实现的,即通过一个中间表,关联两个一对多关系,就形成了多对多关系:
teachers 表:
| id | name |
|---|---|
| 1 | 张老师 |
| 2 | 王老师 |
| 3 | 李老师 |
| 4 | 赵老师 |
classes 表:
| id | name |
|---|---|
| 1 | 一班 |
| 2 | 二班 |
中间表 teacher_class 关联两个一对多关系:
| id | teacher_id | class_id |
|---|---|---|
| 1 | 1 | 1 |
| 2 | 1 | 2 |
| 3 | 2 | 1 |
| 4 | 2 | 2 |
| 5 | 3 | 1 |
| 6 | 4 | 2 |
通过中间表 teacher_class 可知 teachers 到 classes 的关系。
一对一
一对一关系是指,一个表的记录对应到另一个表的唯一一个记录。
例如,students 表的每个学生可以有自己的联系方式,如果把联系方式存入另一个表 contacts,我们就可以得到一个“一对一”关系:
| id | student_id | mobile |
|---|---|---|
| 1 | 1 | 135xxxx6300 |
| 2 | 2 | 138xxxx2209 |
| 3 | 5 | 139xxxx8086 |
有细心的童鞋会问,既然是一对一关系,那为啥不给 students 表增加一个 mobile 列,这样就能合二为一了?
如果业务允许,完全可以把两个表合为一个表。但是,有些时候,如果某个学生没有手机号,那么,contacts 表就不存在对应的记录。实际上,一对一关系准确地说,是 contacts 表一对一对应 students 表。
还有一些应用会把一个大表拆成两个一对一的表,目的是把经常读取和不经常读取的字段分开,以获得更高的性能。例如,把一个大的用户表分拆为用户基本信息表 user_info 和用户详细信息表 user_profiles,大部分时候,只需要查询 user_info 表,并不需要查询 user_profiles 表,这样就提高了查询速度。
索引
在关系数据库中,如果有上万甚至上亿条记录,在查找记录的时候,想要获得非常快的速度,就需要使用索引。
索引是关系数据库中对某一列或多个列的值进行预排序的数据结构。通过使用索引,可以让数据库系统不必扫描整个表,而是直接定位到符合条件的记录,这样就大大加快了查询速度。
例如,对于 students 表:
| id | class_id | name | gender | score |
|---|---|---|---|---|
| 1 | 1 | 小明 | M | 90 |
| 2 | 1 | 小红 | F | 95 |
| 3 | 1 | 小军 | M | 88 |
如果要经常根据 score 列进行查询,就可以对 score 列创建索引:
ALTER TABLE students
ADD INDEX idx_score (score);
使用 ADD INDEX idx_score (score) 就创建了一个名称为 idx_score,使用列 score 的索引。索引名称是任意的,索引如果有多列,可以在括号里依次写上,例如:
ALTER TABLE students
ADD INDEX idx_name_score (name, score);
索引的效率取决于索引列的值是否散列,即该列的值如果越互不相同,那么索引效率越高。反过来,如果记录的列存在大量相同的值,例如 gender 列,大约一半的记录值是 M,另一半是 F,因此,对该列创建索引就没有意义。
可以对一张表创建多个索引。索引的优点是提高了查询效率,缺点是在插入、更新和删除记录时,需要同时修改索引,因此,索引越多,插入、更新和删除记录的速度就越慢。
对于主键,关系数据库会自动对其创建主键索引。使用主键索引的效率是最高的,因为主键会保证绝对唯一。
唯一索引
在设计关系数据表的时候,看上去唯一的列,例如身份证号、邮箱地址等,因为他们具有业务含义,因此不宜作为主键。
但是,这些列根据业务要求,又具有唯一性约束:即不能出现两条记录存储了同一个身份证号。这个时候,就可以给该列添加一个唯一索引。例如,我们假设 students 表的 name 不能重复:
ALTER TABLE students
ADD UNIQUE INDEX uni_name (name);
通过 UNIQUE 关键字我们就添加了一个唯一索引。
也可以只对某一列添加一个唯一约束而不创建唯一索引:
ALTER TABLE students
ADD CONSTRAINT uni_name UNIQUE (name);
这种情况下,name 列没有索引,但仍然具有唯一性保证。
索引的意义
无论是否创建索引,对于用户和应用程序来说,使用关系数据库不会有任何区别。这里的意思是说,当我们在数据库中查询时,如果有相应的索引可用,数据库系统就会自动使用索引来提高查询效率,如果没有索引,查询也能正常执行,只是速度会变慢。因此,索引可以在使用数据库的过程中逐步优化。
设计数据库
数据建模
关键步骤
- 理解和分析业务需求(最重要的一步)
- 构建业务的概念模型:识别业务中的实体、事务、概念以及他们之间的关系
- 构建逻辑模型:生成一个数据模型或者数据结构用以存储数据
- 构建实体模型:数据库支持的具体类型等一系列数据库相关的属性
下文将以一个在线课程销售网站为例,对上述步骤进行讲解
概念模型
识别业务中的实体、事务、概念以及他们之间的关系
学生、课程
我们可以通过 Entity Relationship 实体关系图、ER 图以及 UML(标准建模语言图)
ER 图通常用于数据建模,而 UML 不光是可以,适用性更加广泛
在构建概念和逻辑数据模型时,两种图表都很优秀
ER 图
draw.io -> basic graph -> entity relationship
概念模型,仅仅设计一些常人都可以理解的概念,用于与普通人沟通
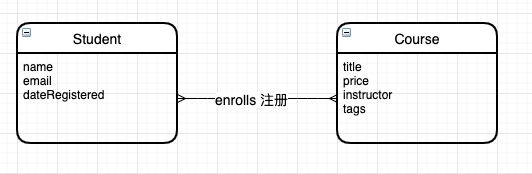
逻辑模型
逻辑模型独立于数据库,当我们使用了具体的数据库,例如 mysql 时,我们会再修改这个逻辑模型,为了适应这个特定的数据库管理系统
通常我们会对概念模型做如下操作:
- 将字段拆分得更加详细,便于我们通过单个字段进行查询
- 为每个字段加上类型
- 描述实体之间的关系
现在我们想增加一个注册日期的属性,这个属性因为学生和课程之间的多对多关系,无论放在哪个实体都是不合理的,此时,我们就需要增加一个新的实体,用来表示学生和注册的课程之间的关系
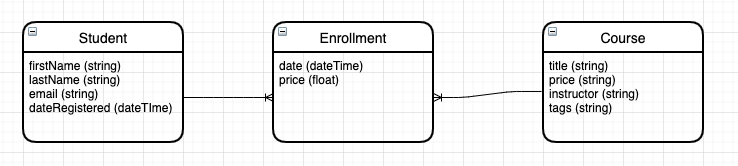
实体模型
基础示例
在 mysql GUI 中创建 , new Model -> add Diagram
- 定义列和类型
- 添加主键,主键会重复出现,所以不应该过长,主键不应该发生变化,just meaningless id,自增
- 添加关系,注册外键即可
- 外键复合主键,可以防止同一个学生重复注册课程。如果未来出现了新表,需要注册表作为外键,那么该复合主键会不断重复
- 新列 id 主键,可以等到未来出现了另一张依赖表,再写一个变更脚本来操作
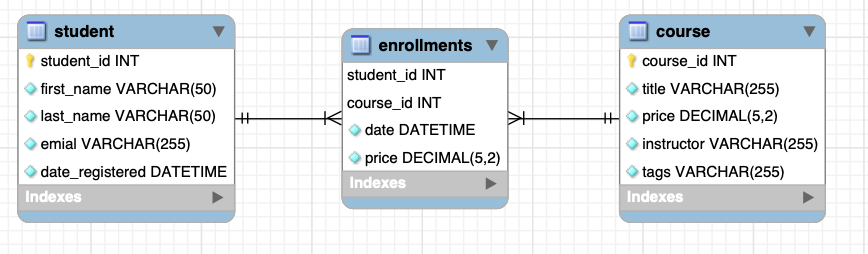
- 添加外键级联, CASCADE
- 减少冗余数据,防止数据重复,7 NORMAL FROM,7 范式
第一范式
一行中的每个单元格都应该有单一值,且不能出现重复列
示例:
- tags column,我们仅通过一个列来储存一系列的标签,但是问题在于我们无法提前知道有多少的标签。我们需要为标签单独表建模
- 缺点:当重命名一个标签的时候,此时会锁定课程的行
- 新建一个中间表,描述多对多的关系,删除 tag column
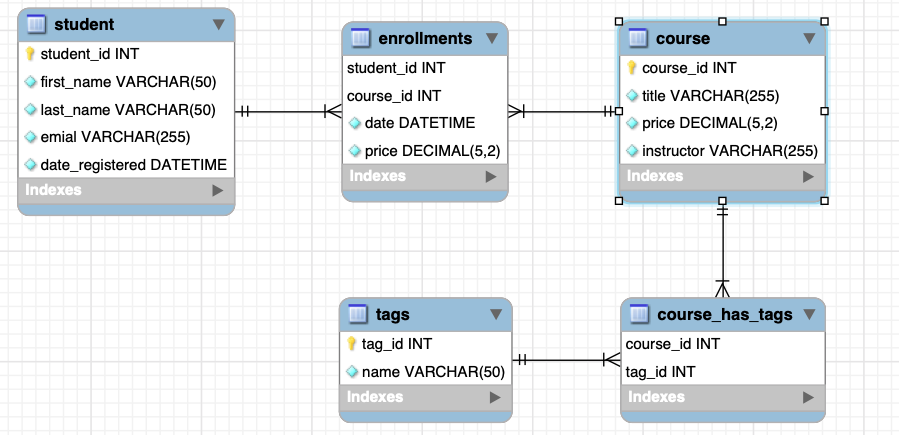
第二范式
要满足第二范式,必须先满足第一范式
并且它不能有任何取决于这组关系任何候选键的任何真子集的非主属性
每张表都应该有一个单一的目的,即每张表只能表示一个实体,然后每一列都应该用来描述该实体
符合第二范式的一个关键:没有重复的冗余字符。
示例中的课程表 instrutor 违反了第二范式,如果一个讲师教授多门课程,他的名字就会重复
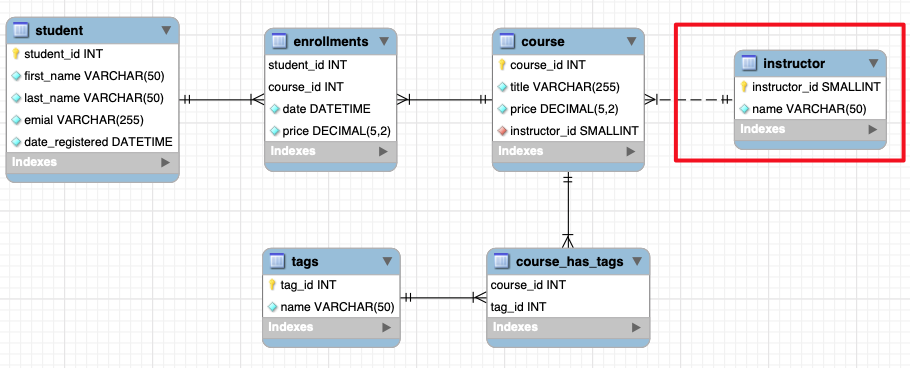
第三范式
实体和表首先应该满足第二范式
表中的所有属性只能由那组关系的候选键决定,而不能是任何非主属性
第三范式:表中的列不应该派生自其他列

balance is no need
实践范式
没必要死记硬背这些 XX 范式,在实践中需要尽所能减少冗余数据即可,减少冗余数据代表着减少 UPDATE 的成本,因为每次更新的地方会变少,也就更安全了
从实体的概念和逻辑开始考虑,不要直接建表
不要试图泛化模型,以便支撑未来的需求,但是大多数时候,这些未来的需求仅仅只存在于脑中,最终的结果就是创建了极复杂但是无用的数据库
为当下的问题寻找最佳的解决方案,而不是永远不可能发生的未来
从实体模型建表
MENU -> Database -> forward Engineer
仅在没有数据的时候使用 forward Engineer
数据模型同步
MENU -> Database -> Synchronize Model
通过 GIT 同步生成的脚本即可
反向工程
从表创建 model,一个数据库一个 model
MENU -> Database -> Reverse Engineer
常见问题
多个表只有一个字段不同
拆分一个基础表,通过关系 join 成差异表
改表名会影响到外键等关系吗?
不会,关键是外键自身,仅仅是改表名不会影响外键列
权限
基础操作
创建用户
CREATE USER [email protected] -- 只能从装有mysql服务的server连接数据库
CREATE USER john@'%.codewithmosh.com' -- 允许相关子域名
CREATE USER john -- 允许从任意服务器
CREATE USER john IDENTIFIED BY '1234' -- 需要输入密码才能访问
查看用户
SELECT * FROM mysql.user
删除用户
DROP USER john@'%.codewithmosh.com'
更改密码
SET PASSWORD FOR john = '1234'
SET PASSWORD '1234' -- 为当前登录的用户创建密码,可以是根用户
权限控制
授予
CREATE USER moon_app IDENTIFIED BY '1234'
GRANT SELECT, INSERT, UPDATE, DELETE, EXECUTE
ON sql_sotre.*
TO moon_app;
CREATE USER moon_app IDENTIFIED BY '1234'
GRANT ALL
ON *.*
TO moon_app;
查看
SHOW GRANTS FOR john;
SHOW GRANTS; -- 查看当前用户
撤销
GRANT CREATE VIEW
ON sql_store.*
TO moon_app;
REVOKE CREATE VIEW
ON sql_store.*
FROM moon_app;
GUI
创建模型
file -> new Model
先 select,之后在表的右上角 export
用户操作
Administration -> Users and Privileges
备份
备份数据
将 mydatabase 数据导出为 mydatabase_out.sql 文件,在终端窗口输入命令:
mysqldump –u root –p mydatabase > mydatabase_out.sql;
mysqldump –u root –p canon > canon-2021-12-12.sql
注意:该命令不能在 MySQL 内执行,要退出 MySQL,在终端窗口命令行下执行。
执行命令后,mydatabase_out.sql 文件被默认存储在根目录下,在终端窗口输入 ls 命令可以查看到输出的文件。
备份多个数据库
mysqldump -u root -p --databases canon_member canon_record canon_event canon_twitter> canon-2022-07-24.sql
还原数据
大多数情况下,要执行导入备份操作,我们先要创建一个数据库,如果数据库已经存在,我们先要将其删除。
在以下示例中,第一个命令将创建一个名为 database_name 的数据库,第二个命令将名为 database_name.sql 的数据库分文文件导入其中:
mysql -u root -p database_name < database_name.sql
mysql -u root -p canon_member canon_record canon_event canon_twitter < canon-2022-07-24.sql
https://www.niuqi360.com/lamp-config/backup-restore-mysql-databases-mysqldump/