http-basic
https://developer.mozilla.org/zh-CN/docs/Web/HTTP
HTTP 协议
HTTP 是一种能够获取如 HTML 这样的网络资源的 protocol(通讯协议)。
它是在 Web 上进行数据交换的基础,是一种 client-server 协议
一个完整的 Web 文档通常是由不同的子文档拼接而成的,像是文本、布局描述、图片、视频、脚本等等。

客户端和服务端通过交换各自的消息进行交互。由像浏览器这样的客户端发出的消息叫做 requests,被服务端响应的消息叫做 responses

HTTP 被设计于 20 世纪 90 年代初期,是一种可扩展的协议。它是应用层的协议,通过 TCP,或者是 TLS-加密的 TCP 连接来发送,理论上任何可靠的传输协议都可以使用。因为其良好的扩展性,时至今日,它不仅被用来传输超文本文档,还用来传输图片、视频或者向服务器发送如 HTML 表单这样的信息。HTTP 还可以根据网页需求,仅获取部分 Web 文档内容更新网页。
基于 HTTP 的组件系统
每一个发送到服务器的请求,都会被服务器处理并返回一个消息,也就是 response。在这个请求与响应之间,还有许许多多的被称为 proxies 的实体,他们的作用与表现各不相同,比如有些是网关,还有些是 caches 等。

实际上,在一个浏览器和处理请求的服务器之间,还有路由器、调制解调器等许多计算机。由于 Web 的层次设计,那些在网络层和传输层的细节都被隐藏起来了。HTTP 位于最上层的应用层。虽然底层对于分析网络问题非常重要,但是大多都跟对 HTTP 的描述不相干。
客户端:user-agent
user-agent 就是任何能够为用户发起行为的工具。这个角色通常都是由浏览器来扮演。一些例外情况,比如是工程师使用的程序,以及 Web 开发人员调试应用程序。
当然它也可能是任何东西,比如一个爬取网页生成维护搜索引擎索引的机器爬虫。
浏览器 总是 作为发起一个请求的实体,他永远不是服务器(虽然近几年已经出现一些机制能够模拟由服务器发起的请求消息了)。
Web 服务端
在上述通信过程的另一端,是由 Web Server 来服务并提供客户端所请求的文档。Server 只是虚拟意义上代表一个机器:它可以是共享负载(负载均衡)的一组服务器组成的计算机集群,也可以是一种复杂的软件,通过向其他计算机(如缓存,数据库服务器,电子商务服务器 ...)发起请求来获取部分或全部资源。
Server 不一定是一台机器,但一个机器上可以装载的众多 Servers。在 HTTP/1.1 和 Host 头部中,它们甚至可以共享同一个 IP 地址。
代理(Proxies)
在浏览器和服务器之间,有许多计算机和其他设备转发了 HTTP 消息。由于 Web 栈层次结构的原因,它们大多都出现在传输层、网络层和物理层上,对于 HTTP 应用层而言就是 透明 的,虽然它们可能会对应用层性能有重要影响。还有一部分是表现在应用层上的,被称为 代理(Proxies)。代理(Proxies)既可以表现得透明,又可以不透明(“改变请求”会通过它们)。代理主要有如下几种作用:
- 缓存(可以是公开的也可以是私有的,像浏览器的缓存)
- 过滤(像反病毒扫描,家长控制...)
- 负载均衡(让多个服务器服务不同的请求)
- 认证(对不同资源进行权限管理)
- 日志记录(允许存储历史信息)
HTTP 的基本性质
HTTP 是简单的
虽然下一代 HTTP/2 协议将 HTTP 消息封装到了帧(frames)中,HTTP 大体上还是被设计得简单易读。HTTP 报文能够被人读懂,还允许简单测试,降低了门槛,对新人很友好。
HTTP 是可扩展的
在 HTTP/1.0 中出现的 HTTP headers 让协议扩展变得非常容易。只要服务端和客户端就新 headers 达成语义一致,新功能就可以被轻松加入进来。
HTTP 是无状态,有会话的 @@@
HTTP 是无状态的:在同一个连接中,两个执行成功的请求之间是没有关系的
这就带来了一个问题,用户没有办法在同一个网站中进行连续的交互,比如在一个电商网站里,用户把某个商品加入到购物车,切换一个页面后再次添加了商品,这两次添加商品的请求之间没有关联,浏览器无法知道用户最终选择了哪些商品。
而使用 HTTP 的头部扩展,HTTP Cookies 就可以解决这个问题。把 Cookies 添加到头部中,创建一个会话让每次请求都能共享相同的上下文信息,达成相同的状态。
注意,HTTP 本质是无状态的,使用 Cookies 可以创建有状态的会话
HTTP 的发展
HTTP(HyperText Transfer Protocol)是万维网(World Wide Web)的基础协议。自 Tim Berners-Lee 博士和他的团队在 1989-1991 年间创造出它以来,HTTP 已经发生了太多的变化,在保持协议简单性的同时,不断扩展其灵活性。如今,HTTP 已经从一个只在实验室之间交换文件的早期协议进化到了可以传输图片,高分辨率视频和 3D 效果的现代复杂互联网协议。
万维网的发明
1989 年, 当时在 CERN 工作的 Tim Berners-Lee 博士写了一份关于建立一个通过网络传输超文本系统的报告。这个系统起初被命名为 Mesh,在随后的 1990 年项目实施期间被更名为万维网(World Wide Web)。 它在现有的 TCP 和 IP 协议基础之上建立,由四个部分组成:
- 一个用来表示超文本文档的文本格式,超文本标记语言(HTML)。
- 一个用来交换超文本文档的简单协议,超文本传输协议(HTTP)。
- 一个显示(以及编辑)超文本文档的客户端,即网络浏览器。第一个网络浏览器被称为 WorldWideWeb。
- 一个服务器用于提供可访问的文档,即 httpd 的前身。
这四个部分完成于 1990 年底,且第一批服务器已经在 1991 年初在 CERN 以外的地方运行了。 1991 年 8 月 16 日,Tim Berners-Lee 在公开的超文本新闻组上发表的文章被视为是万维网公共项目的开始。
HTTP 在应用的早期阶段非常简单,后来被称为 HTTP/0.9,有时也叫做单行(one-line)协议。
HTTP/0.9 – 单行协议
最初版本的 HTTP 协议并没有版本号,后来它的版本号被定位在 0.9 以区分后来的版本。 HTTP/0.9 极其简单:请求由单行指令构成,以唯一可用方法 GET 开头,其后跟目标资源的路径(一旦连接到服务器,协议、服务器、端口号这些都不是必须的)。
GET /mypage.html
响应也极其简单的:只包含响应文档本身。
<html>
这是一个非常简单的HTML页面
</html>
跟后来的版本不同,HTTP/0.9 的响应内容并不包含 HTTP 头,这意味着只有 HTML 文件可以传送,无法传输其他类型的文件;也没有状态码或错误代码:一旦出现问题,一个特殊的包含问题描述信息的 HTML 文件将被发回,供人们查看。
HTTP/1.0 – 构建可扩展性
由于 HTTP/0.9 协议的应用十分有限,浏览器和服务器迅速扩展内容使其用途更广:
- 协议版本信息现在会随着每个请求发送(
HTTP/1.0被追加到了GET行)。 - 状态码会在响应开始时发送,使浏览器能了解请求执行成功或失败,并相应调整行为(如更新或使用本地缓存)。
- 引入了 HTTP 头的概念,无论是对于请求还是响应,允许传输元数据,使协议变得非常灵活,更具扩展性。
- 在新 HTTP 头的帮助下,具备了传输除纯文本 HTML 文件以外其他类型文档的能力(感谢
Content-Type头)。
一个典型的请求看起来就像这样:
GET /mypage.html HTTP/1.0
User-Agent: NCSA_Mosaic/2.0 (Windows 3.1)
200 OK
Date: Tue, 15 Nov 1994 08:12:31 GMT
Server: CERN/3.0 libwww/2.17
Content-Type: text/html
<HTML>
一个包含图片的页面
<IMG SRC="/myimage.gif">
</HTML>
接下来是第二个连接,请求获取图片:
GET /myimage.gif HTTP/1.0 User-Agent: NCSA_Mosaic/2.0 (Windows 3.1) 200 OK Date:
Tue, 15 Nov 1994 08:12:32 GMT Server: CERN/3.0 libwww/2.17 Content-Type:
text/gif (这里是图片内容)
在 1991-1995 年,这些新扩展并没有被引入到标准中以促进协助工作,而仅仅作为一种尝试:服务器和浏览器添加这些新扩展功能,但出现了大量的互操作问题。直到 1996 年 11 月,为了解决这些问题,一份新文档(RFC 1945)被发表出来,用以描述如何操作实践这些新扩展功能。文档 RFC 1945 定义了 HTTP/1.0,但它是狭义的,并不是官方标准。
HTTP/1.1 – 标准化的协议
HTTP/1.0 多种不同的实现方式在实际运用中显得有些混乱,自 1995 年开始,即 HTTP/1.0 文档发布的下一年,就开始修订 HTTP 的第一个标准化版本。在 1997 年初,HTTP1.1 标准发布,就在 HTTP/1.0 发布的几个月后。
HTTP/1.1 消除了大量歧义内容并引入了多项改进:
- 连接可以复用,节省了多次打开 TCP 连接加载网页文档资源的时间。
- 增加流水线操作,允许在第一个应答被完全发送之前就发送第二个请求,以降低通信延迟。
- 支持响应分块。
- 引入额外的缓存控制机制。
- 引入内容协商机制,包括语言,编码,类型等,并允许客户端和服务器之间约定以最合适的内容进行交换。HTTP1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
- 感谢
Host头,能够使不同域名配置在同一个 IP 地址的服务器上。
一个典型的请求流程, 所有请求都通过一个连接实现,看起来就像这样:
GET /en-US/docs/Glossary/Simple_header HTTP/1.1 Host: developer.mozilla.org
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101
Firefox/50.0 Accept:
text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8 Accept-Language:
en-US,en;q=0.5 Accept-Encoding: gzip, deflate, br Referer:
https://developer.mozilla.org/en-US/docs/Glossary/Simple_header 200 OK
Connection: Keep-Alive Content-Encoding: gzip Content-Type: text/html;
charset=utf-8 Date: Wed, 20 Jul 2016 10:55:30 GMT Etag:
"547fa7e369ef56031dd3bff2ace9fc0832eb251a" Keep-Alive: timeout=5, max=1000
Last-Modified: Tue, 19 Jul 2016 00:59:33 GMT Server: Apache Transfer-Encoding:
chunked Vary: Cookie, Accept-Encoding (content) GET
/static/img/header-background.png HTTP/1.1 Host: developer.cdn.mozilla.net
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:50.0) Gecko/20100101
Firefox/50.0 Accept: */* Accept-Language: en-US,en;q=0.5 Accept-Encoding: gzip,
deflate, br Referer:
https://developer.mozilla.org/en-US/docs/Glossary/Simple_header 200 OK Age:
9578461 Cache-Control: public, max-age=315360000 Connection: keep-alive
Content-Length: 3077 Content-Type: image/png Date: Thu, 31 Mar 2016 13:34:46 GMT
Last-Modified: Wed, 21 Oct 2015 18:27:50 GMT Server: Apache (image content of
3077 bytes)
HTTP/1.1 在 1997 年 1 月以 RFC 2068 文件发布。
HTTP 用于复杂应用
在 2000 年,一种新的使用 HTTP 的模式被设计出来:representational state transfer (或者说 REST)。 由 API 发起的操作不再通过新的 HTTP 方法传达,而只能通过使用基本的 HTTP / 1.1 方法访问特定的 URI。 这允许任何 Web 应用程序通过提供 API 以允许查看和修改其数据,而无需更新浏览器或服务器:all what is needed was embedded in the files served by the Web sites through standard HTTP/1.1。 REST 模型的缺点在于每个网站都定义了自己的非标准 RESTful API,并对其进行了全面的控制;不同于 DAV 扩展,客户端和服务器是可互操作的。 RESTful API 在 2010 年变得非常流行。
自 2005 年以来,可用于 Web 页面的 API 大大增加,其中几个 API 为特定目的扩展了 HTTP 协议,大部分是新的特定 HTTP 头:
- Server-sent events,服务器可以偶尔推送消息到浏览器。
- WebSocket,一个新协议,可以通过升级现有 HTTP 协议来建立。
HTTP2
背景
HTTP2.0 可以说是 SPDY 的升级版(其实原本也是基于 SPDY 设计的),但是,HTTP2.0 跟 SPDY 仍有不同的地方,主要是以下两点:
- HTTP2.0 支持明文 HTTP 传输,而 SPDY 强制使用 HTTPS
- HTTP2.0 消息头的压缩算法采用 HPACK,而非 SPDY 采用的 DEFLATE
这些年来,网页愈渐变得的复杂,甚至演变成了独有的应用,可见媒体的播放量,增进交互的脚本大小也增加了许多:更多的数据通过 HTTP 请求被传输。HTTP/1.1 链接需要请求以正确的顺序发送,理论上可以用一些并行的链接(尤其是 5 到 8 个),带来的成本和复杂性堪忧。比如,HTTP 流水线就成为了 Web 开发的负担。
在 2010 年到 2015 年,谷歌通过实践了一个实验性的 SPDY 协议,证明了一个在客户端和服务器端交换数据的另类方式。其收集了浏览器和服务器端的开发者的焦点问题。明确了响应数量的增加和解决复杂的数据传输,SPDY 成为了 HTTP/2 协议的基础。
在 2015 年 5 月正式标准化后,HTTP/2 取得了极大的成功,在 2016 年 7 月前,8.7% 的站点已经在使用它,代表超过 68% 的请求 (https://www.keycdn.com/blog/http2-statistics/) 。高流量的站点最迅速的普及,在数据传输上节省了可观的成本和支出。
这种迅速的普及率很可能是因为 HTTP2 不需要站点和应用做出改变:使用 HTTP/1.1 和 HTTP/2 对他们来说是透明的。拥有一个最新的服务器和新点的浏览器进行交互就足够了。只有一小部分群体需要做出改变,而且随着陈旧的浏览器和服务器的更新,而不需 Web 开发者做什么,用的人自然就增加了。
前文说了 HTTP2.0 其实可以支持非 HTTPS 的,但是现在主流的浏览器像 chrome,firefox 表示还是只支持基于 TLS 部署的 HTTP2.0 协议,所以要想升级成 HTTP2.0 还是先升级 HTTPS 为好。
当你的网站已经升级 HTTPS 之后,那么升级 HTTP2.0 就简单很多,如果你使用 NGINX,只要在配置文件中启动相应的协议就可以了,可以参考 NGINX 白皮书,NGINX 配置 HTTP2.0 官方指南 https://www.nginx.com/blog/nginx-1-9-5/。
使用了 HTTP2.0 那么,原本的 HTTP1.x 怎么办,这个问题其实不用担心,HTTP2.0 完全兼容 HTTP1.x 的语义,对于不支持 HTTP2.0 的浏览器,NGINX 会自动向下兼容的。
HTTP/2 在 HTTP/1.1 有几处基本的不同,接下来会一一介绍
二进制协议
HTTP/2 是 二进制协议 而不是文本协议。不再可读,也不可无障碍的手动创建,HTTP/1.x 的解析是基于文本的。基于文本协议的解析存在天然缺陷,文本的表现形式有多样性,要做到全面性考虑的场景必然很多。二进制则不同,只识别 0 和 1 的组合。基于这种考虑 HTTP/2.0 的协议解析采用二进制格式,方便且强大。
在 应用层 (HTTP/2) 和传输层 (TCP or UDP) 之间增加一个二进制分帧层
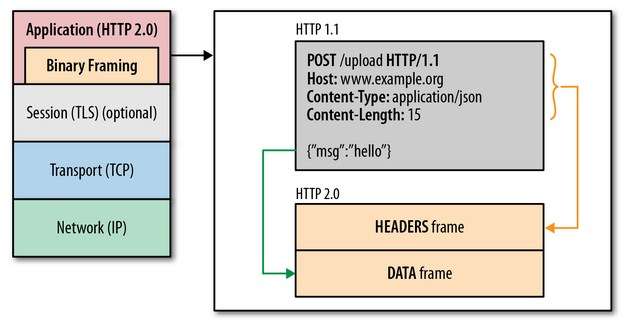
多路复用
即连接共享,即每一个 request 都是是用作连接共享机制的。一个 request 对应一个 id,这样一个连接上可以有多个 request,每个连接的 request 可以随机的混杂在一起,接收方可以根据 request 的 id 将 request 再归属到各自不同的服务端请求里面。
HTTP 性能优化的关键并不在于高带宽,而是低延迟。TCP 连接会随着时间进行自我「调谐」,起初会限制连接的最大速度,如果数据成功传输,会随着时间的推移提高传输的速度。这种调谐则被称为 TCP 慢启动。由于这种原因,让原本就具有突发性和短时性的 HTTP 连接变的十分低效。HTTP/2 通过让所有数据流共用同一个连接,可以更有效地使用 TCP 连接,让高带宽也能真正的服务于 HTTP 的性能提升。
头部压缩
如上文中所言,对前面提到过 HTTP1.x 的 header 带有大量信息,而且每次都要重复发送,HTTP2.0 使用 encoder 来减少需要传输的 header 大小,通讯双方各自 cache 一份 header fields 表,既避免了重复 header 的传输,又减小了需要传输的大小。
HTTP2.0 可以维护一个 字典,差量更新 HTTP 头部,大大降低因头部传输产生的流量。具体参考:HTTP/2 头部压缩技术介绍
服务端推送
同 SPDY 一样,HTTP2.0 也具有 server push 功能。其允许服务器在客户端缓存中填充数据,通过一个叫 服务器推送的机制来提前请求。
服务端推送能把客户端所需要的资源伴随着 index.html 一起发送到客户端,省去了客户端重复请求的步骤。正因为没有发起请求,建立连接等操作,所以静态资源通过服务端推送的方式可以极大地提升速度。
普通的客户端请求:

服务端推送的过程:

后 HTTP/2 进化
随着 HTTP/2.的发布,就像先前的 HTTP/1.x 一样,HTTP 没有停止进化,HTTP 的扩展性依然被用来添加新的功能。特别的,我们能列举出 2016 年里 HTTP 的新扩展:
- 对 Alt-Svc 的支持允许了给定资源的位置和资源鉴定,允许了更智能的 CDN 缓冲机制。
Client-Hints的引入允许浏览器或者客户端来主动交流它的需求,或者是硬件约束的信息给服务端。- 在 Cookie 头中引入安全相关的的前缀,现在帮助保证一个安全的 cookie 没被更改过。
HTTP 的进化证实了它良好的扩展性和简易性,释放了很多应用程序的创造力并且情愿使用这个协议。今天的 HTTP 的使用环境已经于早期 1990 年代大不相同。HTTP 的原先的设计不负杰作之名,允许了 Web 在 25 年间和平稳健得发展。修复漏洞,同时却也保留了使 HTTP 如此成功的灵活性和扩展性,HTTP/2 的普及也预示着这个协议的大好前程。
HTTP/3
HTTP/2.0 使用了多路复用,一般来说同一域名下只需要使用一个 TCP 连接。但当这个连接中出现了丢包的情况,那就会导致整个 TCP 都要开始等待重传,也就导致了后面的所有数据都被阻塞了。反而对于 HTTP/1.0 来说,可以开启多个 TCP 连接,出现丢包反倒只会影响其中一个连接,剩余的 TCP 连接还可以正常传输数据。 出现这个原因是因为底层 TCP 协议导致的问题,但是修改 TCP 协议是不现实的问题,就像 typeof null === 'object' 一样,修改这个问题会导致出现更多的问题。既然不能修改你,就新起一个协议取代你。Google 基于 UDP 协议推出了一个的 QUIC 协议,并且使用在了 HTTP/3 上。
QUIC 基于 UDP,但是 UDP 本书存在不稳定性等诸多问题,所以 QUIC 在 UDP 的基础上新增了很多功能,比如多路复用、0-RTT、使用 TLS1.3 加密、流量控制、有序交付、重传等等功能。优点诸多,参考 这里:
- 避免包阻塞: 多个数据在 TCP 连接上传输时,若一个数据包出现问题,TCP 需要等待该包重传后,才能继续传输其它数据包。但在 QUIC 中,因为其基于 UDP 协议,UDP 数据包在出问题需要重传时,并不会对其他数据包传输产生影响。
- 快速重启会话: 普通基于 tcp 的连接,是基于两端的 ip 和端口和协议来建立的。在网络切换场景,例如手机端切换了无线网,使用 4G 网络,会改变本身的 ip,这就导致 tcp 连接必须重新创建。而 QUIC 协议使用特有的 UUID 来标记每一次连接,在网络环境发生变化的时候,只要 UUID 不变,就能不需要握手,继续传输数据。
HTTP 连接管理
HTTP 连接
一个连接是由传输层来控制的,这从根本上不属于 HTTP 的范围。HTTP 并不需要其底层的传输层协议是面向连接的,只需要它是可靠的,或不丢失消息的(至少返回错误)。在互联网中,有两个最常用的传输层协议:TCP 是可靠的,而 UDP 不是。因此,HTTP 依赖于面向连接的 TCP 进行消息传递,但连接并不是必须的。
HTTP/1.0 为每一个请求/响应都打开一个 TCP 连接,导致了 2 个缺点:
- 打开一个 TCP 连接需要多次往返消息传递,因此速度慢。
- 但当多个消息周期性发送时,这样就变得更加高效:暖连接 比 冷连接 更高效。
为了减轻这些缺陷,HTTP/1.1 引入了流水线(被证明难以实现)和长连接的概念:底层的 TCP 连接可以通过 Connection 头部来被部分控制。HTTP/2 则发展得更远,通过在一个连接复用消息的方式来让这个连接始终保持为暖连接。
为了更好的适合 HTTP,设计一种更好传输协议的进程一直在进行。Google 就研发了一种以 UDP 为基础,能提供更可靠更高效的传输协议 QUIC。
HTTP/1.X 的连接管理
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Connection_management_in_HTTP_1.x
连接管理是一个 HTTP 的关键话题:打开和保持连接在很大程度上影响着网站和 Web 应用程序的性能。在 HTTP/1.x 里有多种模型:短连接, 长连接, 和 HTTP 流水线。

要注意的一个重点是 HTTP 的连接管理适用于两个连续节点之间的连接,如 hop-by-hop,而不是 end-to-end。当模型用于从客户端到第一个代理服务器的连接和从代理服务器到目标服务器之间的连接时 (或者任意中间代理) 效果可能是不一样的。HTTP 协议头受不同连接模型的影响,比如 Connection 和 Keep-Alive,就是 hop-by-hop 协议头,它们的值是可以被中间节点修改的。
短连接
又名:串行连接
HTTP 最早期的模型,也是 HTTP/1.0 的默认模型,是短连接。每一个 HTTP 请求都由它自己独立的连接完成;这意味着发起每一个 HTTP 请求之前都会有一次 TCP 握手,而且是连续不断的。
TCP 协议握手本身就是耗费时间的,所以 TCP 可以保持更多的热连接来适应负载。短连接破坏了 TCP 具备的能力,新的冷连接降低了其性能。
这是 HTTP/1.0 的默认模型 (如果没有指定
Connection协议头,或者是值被设置为close)。而在 HTTP/1.1 中,只有当Connection被设置为close时才会用到这个模型。
有两个新的模型在 HTTP/1.1 诞生了。
长连接
短连接有两个比较大的问题:创建新连接耗费的时间尤为明显,另外 TCP 连接的性能只有在该连接被使用一段时间后 (热连接) 才能得到改善。为了缓解这些问题,长连接 的概念便被设计出来了,甚至在 HTTP/1.1 之前。或者这被称之为一个 keep-alive 连接。
一个长连接会保持一段时间,重复用于发送一系列请求,节省了新建 TCP 连接握手的时间,还可以利用 TCP 的性能增强能力。当然这个连接也不会一直保留着:连接在空闲一段时间后会被关闭 (服务器可以使用 Keep-Alive 协议头 来指定一个最小的连接保持时间)。
长连接也还是有缺点的;就算是在空闲状态,它还是会消耗服务器资源,而且在重负载时,还有可能遭受 DoS attacks 攻击。这种场景下,可以使用非长连接,即尽快关闭那些空闲的连接,也能对性能有所提升。
HTTP/1.0 里默认并不使用长连接。把 Connection 设置成 close 以外的其它参数都可以让其保持长连接,通常会设置为 retry-after。
在 HTTP/1.1 里,默认就是长连接的,协议头都不用再去声明它 (但我们还是会把它加上,万一某个时候因为某种原因要退回到 HTTP/1.0 呢)。
HTTP 流水线
又名:管道化持久连接
由于这些原因,流水线已经被更好的算法给代替,如 multiplexing,已经用在 HTTP/2。
域名分片
除非你有紧急而迫切的需求,不要使用这一过时的技术,升级到 HTTP/2 就好了。在 HTTP/2 里,做域名分片就没必要了:HTTP/2 的连接可以很好的处理并发的无优先级的请求。域名分片甚至会影响性能。大多数 HTTP/2 的实现还会使用一种称作 连接凝聚 的技术去尝试合并被分片的域名。
HTTP/2 多路复用
每个 HTTP 请求都有一个序列标识符,这样浏览器可以并发多个请求,服务器接收到数据后,再根据序列标识符重新排序成不同的请求报文,而不会导致数据错乱( 细节参照此文)。同样,服务端也可以并发返回多个响应给浏览器,浏览器收到后根据序列标识重新排序并归入各自的请求的响应报文。并且同一个域名下的所有请求都复用同一个 TCP 连接,极大增加了服务器处理并发的上限。
逻辑上是这样的:

但实际上是这样的:

长连接只是复用了 TCP 连接,每次 HTTP 请求都是依次发送的
HTTP/2 同样是复用了 TCP 连接,但是同时也是是逻辑上的并发请求
总结
与服务器建立的连接是否会在一个 HTTP 请求后断开?什么情况下断开?
在 HTTP/1.0 中,一个服务器在发送完一个 HTTP 响应后,会断开 TCP 链接。
所以虽然标准中没有设定,某些服务器对 Connection: keep-alive 的 Header 进行了支持。意思是说,完成这个 HTTP 请求之后,不要断开 HTTP 请求使用的 TCP 连接。那么 SSL 的开销也可以避免。
持久连接: 既然维持 TCP 连接好处这么多,HTTP/1.1 就把 Connection 头写进标准,并且默认开启持久连接,除非请求中写明 Connection: close,那么浏览器和服务器之间是会维持一段时间的 TCP 连接,不会一个请求结束就断掉。
一个 TCP 连接可以对应几个 HTTP 请求
如果维持连接,一个 TCP 连接是可以发送多个 HTTP 请求的。
一个 TCP 连接中 HTTP 请求发送可以一起发送么?
HTTP/1.1 存在一个问题: 单个 TCP 连接在同一时刻只能处理一个请求。两个请求的生命周期不能重叠,任意两个 HTTP 请求从开始到结束的时间在同一个 TCP 连接里不能重叠。
HTTP2 提供了 Multiplexing 多路传输特性,可以在一个 TCP 连接中同时完成多个 HTTP 请求。
为什么有的时候刷新页面不需要重新建立 SSL 连接
在第一个问题的讨论中已经有答案了: TCP 连接有的时候会被浏览器和服务端维持一段时间。TCP 不需要重新建立,SSL 自然也会用之前的。
浏览器对同一 Host 建立 TCP 连接到数量有没有限制?
假设我们还处在 HTTP/1.1 时代,那个时候没有多路传输,当浏览器拿到一个有几十张图片的网页该怎么办呢?
肯定不能只开一个 TCP 连接顺序下载,那样用户肯定等的很难受,但是如果每个图片都开一个 TCP 连接发 HTTP 请求,那电脑或者服务器都可能受不了,要是有 1000 张图片的话总不能开 1000 个 TCP 连接吧,你的电脑同意 NAT 也不一定会同意。
所以答案是: 有。Chrome 最多允许对同一个 Host 建立六个 TCP 连接。不同的浏览器有一些区别
进阶阅读
https://www.zhihu.com/question/24774343/answer/96586977
https://www.mnot.net/talks/h2fe/
HTTP 消息
HTTP 消息是服务器和客户端之间交换数据的方式。有两种类型的消息︰
- 请求 -- 由客户端发送用来触发一个服务器上的动作;
- 响应 -- 来自服务器的应答。
HTTP 消息由采用 ASCII 编码的多行文本构成。在 HTTP/1.1 及早期版本中,这些消息通过连接公开地发送。在 HTTP/2 中,为了优化和性能方面的改进,曾经可人工阅读的消息被分到多个 HTTP 帧中。
Web 开发人员或网站管理员,很少自己手工创建这些原始的 HTTP 消息︰ 由软件、浏览器、 代理或 服务器完成。他们通过配置文件(用于代理服务器或服务器),API (用于浏览器)或其他接口提供 HTTP 消息。

HTTP/2 二进制框架机制被设计为不需要改动任何 API 或配置文件即可应用︰ 它大体上对用户是透明的。
HTTP 请求和响应具有相似的结构,由以下部分组成︰
- 一行起始行用于描述要执行的请求,或者是对应的状态,成功或失败。这个起始行总是 单行 的。
- 一个可选的 HTTP 头集合指明请求或描述消息正文。
- 一个空行指示所有关于请求的元数据已经发送完毕。
- 一个可选的包含请求相关数据的正文 (比如 HTML 表单内容), 或者响应相关的文档。 正文的大小有起始行的 HTTP 头来指定。
起始行和 HTTP 消息中的 HTTP 头统称为请求头,而其有效负载被称为消息正文。

HTTP 请求
HTTP Headers https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Headers
逐跳消息头
- 这类消息头仅对单次传输连接有意义,不能通过代理或缓存进行重新转发。这些消息头包括
Connection,Keep-Alive,Proxy-Authenticate,Proxy-Authorization,TE,Trailer,Transfer-Encoding及Upgrade。注意,只能使用Connection来设置逐跳一般头。
起始行
HTTP 请求是由客户端发出的消息,用来使服务器执行动作。起始行 (start-line) 包含三个元素:
-
一个 HTTP 方法,一个动词 (像
GET,PUT或者POST) 或者一个名词 (像HEAD或者OPTIONS), 描述要执行的动作. 例如,GET表示要获取资源,POST表示向服务器推送数据 (创建或修改资源, 或者产生要返回的临时文件)。 -
请求目标 (request target),通常是一个 URL,或者是协议、端口和域名的绝对路径,通常以请求的环境为特征。请求的格式因不同的 HTTP 方法而异。它可以是:
- 一个绝对路径,末尾跟上一个 ' ? ' 和 查询字符串。这是最常见的形式,称为 原始形式 (origin form),被 GET,POST,HEAD 和 OPTIONS 方法所使用。
POST / HTTP 1.1 GET /background.png HTTP/1.0 HEAD /test.html?query=alibaba HTTP/1.1 OPTIONS /anypage.html HTTP/1.0- 一个完整的 URL,被称为 绝对形式 (absolute form),主要在 GET 连接到代 理时使用。
GET http://developer.mozilla.org/en-US/docs/Web/HTTP/Messages HTTP/1.1 - 由域名和可选端口(以
':'为前缀)组成的 URL 的 authority component,称为 authority form。 仅在使用 CONNECT 建立 HT TP 隧道 时才使用。CONNECT developer.mozilla.org:80 HTTP/1.1 - 星号形式 (asterisk form),一个简单的星号
('*'),配合 OPTIONS 方法使 用,代表整 个服务器。OPTIONS * HTTP/1.1
-
HTTP 版本 (HTTP version),定义了剩余报文的结构,作为对期望的响应版本的指示符。
HTTP 请求方法
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Methods
HEAD CONNECT OPTIONS
HEAD
HEAD 方法和 GET 类似, 但是不会返回响应体, 使用场景:
- 可以用于快速验证资源是否合法
- 下载一个大文件前先获取其大小再决定是否要下载,以此可以节约带宽资源。
OPTIONS
OPTIONS 请求与 HEAD 类似,一般也是用于客户端查看服务器的性能。这个方法会请求服务器返回该资源所支持的所有 HTTP 请求方法,该方法会用 * 来代替资源名称,向服务器发送 OPTIONS 请求,可以测试服务器功能是否正常。JS 的 XMLHttpRequest 对象进行 CORS 跨域资源共享时,对于复杂请求,就是使用 OPTIONS 方法发送嗅探请求,以判断是否有对指定资源的访问权限。
Post 和 Get 的区别
Post 和 Get 是 HTTP 请求的两种方法。
- 从应用场景上来说,GET 请求是一个幂等的请求,一般 Get 请求用于对服务器资源不会产生影响的场景,比如说请求一个网 页。而 Post 不是一个幂等的请求,一般用于对服务器资源会产生影响的情景。比如注册用户这一类的操作。
- 因为不同的应用场景,所以浏览器一般会对 Get 请求缓存,但很少对 Post 请求缓存。
- 从发送的报文格式来说,Get 请求的报文中实体部分为空,Post 请求的报文中实体部分一般为向服务器发送的数据。
- 但是 Get 请求也可以将请求的参数放入 url 中向服务器发送,这样的做法相对于 Post 请求来说:
- 一个方面是不太安全, 因为请求的 url 会被保留在历史记录中
- 并且浏览器由于对 url 有一个长度上的限制,所以会影响 get 请求发送数据时 的长度。这个限制是浏览器规定的,并不是 RFC 规定的
- 还有就是 post 的参数传递支持更多的数据类型
Headers
来自请求的 HTTP headers 遵循和 HTTP header 相同的基本结构:不区分大小写的字符串,紧跟着的冒号 (':') 和一个结构取决于 header 的值。 整个 header(包括值)由一行组成,这一行可以相当长。
有许多请求头可用,它们可以分为几组:
- General headers,例如 Via,适用于整个报文。
- Request headers,例如 User-Agent,Accept-Type,通过进一步的定义 (例如 Accept-Language),或者给定上下文 (例如 Referer),或者进行有条件的限制 (例如
If-None) 来修改请求。 - Entity headers,例如
Content-Length,适用于请求的 body。显然,如果请求中没有任何 body,则不会发送这样的头文件。

Body
请求的最后一部分是它的 body。不是所有的请求都有一个 body:例如获取资源的请求,GET,HEAD,DELETE 和 OPTIONS,通常它们不需要 body。 有些请求将数据发送到服务器以便更新数据:常见的的情况是 POST 请求(包含 HTML 表单数据)。
Body 大致可分为两类:
- Single-resource bodies,由一个单文件组成。该类型 body 由两个 header 定义:
Content-Type和Content-Length. - Multiple-resource bodies,由多部分 body 组成,每一部分包含不同的信息位。通常是和 HTML Forms 连系在一起。
HTTP 响应
状态行
HTTP 响应的起始行被称作 状态行 (status line),包含以下信息:
- 协议版本,通常为
HTTP/1.1。 - 状态码 (status code),表明请求是成功或失败。常见的状态码是
200,404,或302。 - 状态文本 (status text)。一个简短的,纯粹的信息,通过状态码的文本描述,帮助人们理解该 HTTP 消息。
一个典型的状态行看起来像这样:HTTP/1.1 404 Not Found。
Headers
响应的 HTTP headers 遵循和任何其它 header 相同的结构:不区分大小写的字符串,紧跟着的冒号 (':') 和一个结构取决于 header 类型的值。 整个 header(包括其值)表现为 单行形式。
有许多响应头可用,这些响应头可以分为几组:
- **General headers,**例如
Via,适用于整个报文。 - **Response headers,**例如
Vary和Accept-Ranges,提供其它不符合状态行的关于服务器的信息。 - Entity headers,例如
Content-Length,适用于请求的 body。显然,如果请求中没有任何 body,则不会发送这样的头文件。

Body
响应的最后一部分是 body。不是所有的响应都有 body:具有状态码 (如 201 或 204) 的响应,通常不会有 body。
Body 大致可分为三类:
- Single-resource bodies,由 已知 长度的单个文件组成。该类型 body 由两个 header 定义:
Content-Type和Content-Length。 - Single-resource bodies,由 未知 长度的单个文件组成,通过将
Transfer-Encoding设置为chunked 来使用 chunks 编码。 - Multiple-resource bodies,由多部分 body 组成,每部分包含不同的信息段。但这是比较少见的。
HTTP/2 帧
HTTP/1.x 报文有一些性能上的缺点:
- Header 不像 body,它不会被压缩。
- 两个报文之间的 header 通常非常相似,但它们仍然在连接中重复传输。
- 无法复用。当在同一个服务器打开几个连接时:TCP 热连接比冷连接更加有效。
HTTP/2 引入了一个额外的步骤:它 将 HTTP/1.x 消息分成帧并嵌入到流 (stream) 中。数据帧和报头帧分离,这将允许报头压缩。将多个流组合,这是一个被称为 多路复用 (multiplexing) 的过程,它允许更有效的底层 TCP 连接。

HTTP 帧现在对 Web 开发人员是透明的。在 HTTP/2 中,这是一个在 HTTP/1.1 和底层传输协议之间附加的步骤。Web 开发人员不需要在其使用的 API 中做任何更改来利用 HTTP 帧;当浏览器和服务器都可用时,HTTP/2 将被打开并使用。
HTTP 状态码
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Status
HTTP 响应状态代码指示特定 HTTP 请求是否已成功完成。响应分为五类:信息响应,成功响应,重定向,客户端错误和服务器错误。状态代码由 section 10 of RFC 2616 定义
信息响应
100 Continue
这个临时响应表明,迄今为止的所有内容都是可行的,客户端应该继续请求,如果已经完成,则忽略它。
101 Switching Protocol
该代码是响应客户端的 Upgrade 标头发送的,并且指示服务器也正在切换的协议。
当使用 websocket 协议的时候在握手阶段
成功响应
200 OK
请求成功。成功的含义取决于 HTTP 方法:
- GET:资源已被提取并在消息正文中传输。
- HEAD:实体标头位于消息正文中。
- POST:描述动作结果的资源在消息体中传输。
TRACE:消息正文包含服务器收到的请求消息
201
202
203
204 No Content
服务器成功处理了请求,但不需要返回任何实体内容,并且希望返回更新了的元信息。响应可能通过实体头部的形式,返回新的或更新后的元信息。如果存在这些头部信息,则应当与所请求的变量相呼应。如果客户端是浏览器的话,那么用户浏览器应保留发送了该请求的页面,而不产生任何文档视图上的变化,即使按照规范新的或更新后的元信息应当被应用到用户浏览器活动视图中的文档。由于 204 响应被禁止包含任何消息体,因此它始终以消息头后的第一个空行结尾。
205 Reset Content
服务器成功处理了请求,且没有返回任何内容。但是与 204 响应不同,返回此状态码的响应要求请求者重置文档视图。该响应主要是被用于接受用户输入后,立即重置表单,以便用户能够轻松地开始另一次输入。与 204 响应一样,该响应也被禁止包含任何消息体,且以消息头后的第一个空行结束。
注意:返回该状态码,浏览器并不会自动清空表单
206 Partial Content
服务器已经成功处理了部分 GET 请求。类似于 FlashGet 或者迅雷这类的 HTTP 下载工具都是使用此类响应实现断点续传或者将一个大文档分解为多个下载段同时下载。该请求必须包含 Range 头信息来指示客户端希望得到的内容范围,并且可能包含 If-Range 来作为请求条件。
Content-Range 用以指示本次响应中返回的内容的范围;如果是 Content-Type 为 multipart/byteranges 的多段下载,则每一 multipart 段中都应包含 Content-Range 域用以指示本段的内容范围。假如响应中包含 Content-Length,那么它的数值必须匹配它返回的内容范围的真实字节数。
Date
ETag 和/或 Content-Location,假如同样的请求本应该返回 200 响应。
Expires, Cache-Control,和/或 Vary,假如其值可能与之前相同变量的其他响应对应的值不同的话。
假如本响应请求使用了 If-Range 强缓存验证,那么本次响应不应该包含其他实体头;假如本响应的请求使用了 If-Range 弱缓存验证,那么本次响应禁止包含其他实体头;这避免了缓存的实体内容和更新了的实体头信息之间的不一致。否则,本响应就应当包含所有本应该返回 200 响应中应当返回的所有实体头部域。
假如 ETag 或 Last-Modified 头部不能精确匹配的话,则 客户端缓存 应禁止将 206 响应返回的内容与之前任何缓存过的内容组合在一起。
重定向
重定向可以简单理解为跳转链接。
- 网站调整(如改变网页目录结构)
- 网页被移到一个新地址
- 网页扩展名改变 (如应用需要把.php 改成.Html 或.shtml)
这种情况下,如果不做重定向,则用户收藏夹或搜索引擎数据库中旧地址只能让访问客户得到一个 404 页面错误信息,访问流量白白丧失;再者某些注册了多个域名的网站,也需要通过重定向让访问这些域名的用户自动跳转到主站点等。
301 Moved Permanently
永久重定向
被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个 URI 之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为从服务器反馈回来的地址。除非额外指定,否则这个响应也是可缓存的。
新的永久性的 URI 应当在响应的 Location 域中返回。除非这是一个 HEAD 请求,否则响应的实体中应当包含指向新的 URI 的 超链接 及简短说明。
如果这不是一个 GET 或者 HEAD 请求,因此浏览器禁止自动进行重定向,除非得到用户的确认,因为请求的条件可能因此发生变化。
注意:对于某些使用 HTTP/1.0 协议的浏览器,当它们发送的 POST 请求得到了一个 301 响应的话,接下来的重定向请求将会变成 GET 方式。
- 域名 到期不想 续费(或 者发现了 更适合网 站的域名 ),想换 个域名。
- 在搜索引擎的搜索结果中出现了不带 www 的域名,而带 www 的域名却没有收录,这个时候可以用 301 重定向来告诉 搜索引擎 我们目标 的域名是 哪一个。
- 空间服务器不稳定,换空间的时候。
- http 升级 https
302 Found
302 Found 临时重定向
请求的资源现在临时从不同的 URI 响应请求。由于这样的重定向是临时的,客户端应当继续向原有地址发送以后的请求。只有在 Cache-Control 或 Expires 中进行了指定的情况下,这个响应才是可缓存的。
如果这不是一个 GET 或者 HEAD 请求,那么浏览器禁止自动进行重定向,除非得到用户的确认,因为请求的条件可能因此发生变化。
注意:虽然 RFC 1945 和 RFC 2068 规范不允许客户端在重定向时改变请求的方法,但是很多现存的浏览器将 302 响应视作为 303 响应,并且使用 GET 方式访问在 Location 中规定的 URI,而无视原先请求的方法。状态码 303 和 307 被添加了进来,用以明确服务器期待客户端进行何种反应。
- 未 登录的时 候跳转到 登陆页面
- 404 的时候跳转到首页
303 See Other
对应当前请求的响应可以在另一个 URI 上被找到,而且客户端应当采用 GET 的方式访问那个资源。这个方法的存在主要是为了允许由脚本激活的 POST 请求输出重定向到一个新的资源。
注意:许多 HTTP/1.1 版以前的浏览器不能正确理解 303 状态。如果需要考虑与这些浏览器之间的互动,302 状态码应该可以胜任,因为大多数的浏览器处理 302 响应时的方式恰恰就是上述规范要求客户端处理 303 响应时应当做的。
304 Not Modified
如果客户端发送了一个带条件的 GET 请求且该请求已被允许,而文档的内容(自上次访问以来或者根据请求的条件)并没有改变,则服务器应当返回这个状态码。304 响应禁止包含消息体,因此始终以消息头后的第一个空行结尾。
虽然 304 被划分在 3XX,但和重定向一毛钱关系都没有,可以理解为重定向到缓存
该响应必须包含以下的头信息:
Date,除非这个服务器没有时钟。假如没有时钟的服务器也遵守这些规则,那么 代理服务器 以及客户端可以自行将 Date 字段添加到接收到的响应头中去(正如 RFC 2068 中规定的一样),缓存机制将会正常工作。
ETag 和/或 Content-Location,假如同样的请求本应返回 200 响应。
Expires, Cache-Control,和/或 Vary,假如其值可能与之前相同变量的其他响应对应的值不同的话。
假如本响应请求使用了强 缓存 验证,那么本次响应不应该包含其他实体头;否则(例如,某个带条件的 GET 请求使用了弱缓存验证),本次响应禁止包含其他实体头;这避免了缓存了的实体内容和更新了的实体头信息之间的不一致。
假如某个 304 响应指明了当前某个实体没有缓存,那么缓存系统必须忽视这个响应,并且重复发送不包含限制条件的请求。
假如接收到一个要求更新某个缓存条目的 304 响应,那么缓存系统必须更新整个条目以反映所有在响应中被更新的字段的值。
305 Use Proxy
被请求的资源必须通过指定的代理才能被访问。Location 域中将给出指定的代理所在的 URI 信息,接收者需要重复发送一个单独的请求,通过这个代理才能访问相应资源。只有原始服务器才能建立 305 响应。
注意:RFC 2068 中没有明确 305 响应是为了重定向一个单独的请求,而且只能被原始服务器建立。忽视这些限制可能导致严重的安全后果。
307 Temporary Redirect
临时重定向 ,和 30 2 有 着相同含义尽管 302 标准禁止 POST 变为 GET,但没人听他的 而 307 就会遵照标准,不会从 POST 变为 GET 但处理响应行为,各个浏览器可能不同。 如果这不是一个 GET 或者 HEAD 请求,那么浏览器禁止自动进行重定向,除非得到用户的确认,因为请求的条件可能因此发生变化。
客户端响应
这类的状态码代表了客户端看起来可能发生了错误,妨碍了服务器的处理。除非响应的是一个 HEAD 请求,否则服务器就应该返回一个解释当前错误状况的实体,以及这是临时的还是永久性的状况。这些状态码适用于任何请求方法。浏览器应当向用户显示任何包含在此类错误响应中的实体内容。
如果错误发生时客户端正在传送数据,那么使用 TCP 的服务器实现应当仔细确保在关闭客户端与服务器之间的连接之前,客户端已经收到了包含错误信息的数据包。如果客户端在收到错误信息后继续向服务器发送数据,服务器的 TCP 栈将向客户端发送一个重置数据包,以清除该客户端所有还未识别的输入缓冲,以免这些数据被服务器上的应用程序读取并干扰后者。
400 Bad Request
- 语义有误,当前请求无法被服务器理解。除非进行修改,否则客户端不应该重复提交这个请求。
- 请求参数有误。
当服务器要求必须有一些 url 参数时,但请求没有带上或者参数名写错了,会返回 400
401 Unauthorized
当前请求需要用户验证。该响应必须包含一个适用于被请求资源的 WWW-Authenticate 信息头用以询问用户信息。客户端可以重复提交一个包含恰当的 Authorization 头信息的请求。如果当前请求已经包含了 Authorization 证书,那么 401 响应代表着服务器验证已经拒绝了那些证书。如果 401 响应包含了与前一个响应相同的身份验证询问,且浏览器已经至少尝试了一次验证,那么浏览器应当向用户展示响应中包含的实体信息,因为这个实体信息中可能包含了相关诊断信息。
403 Forbidden
服务器已经理解请求,但是拒绝执行它。与 401 响应不同的是,身份验证并不能提供任何帮助,而且这个请求也不应该被重复提交。如果这不是一个 HEAD 请求,而且服务器希望能够讲清楚为何请求不能被执行,那么就应该在实体内描述拒绝的原因。当然服务器也可以返回一个 404 响应,假如它不希望让客户端获得任何信息。
当浏览器通过 js 提交跨域的复杂请求时,会先发送一个 OPTION 请求,如果服务器检测不允许其跨域请求,则返回 403
- 你的 I P 被列入 黑名单。
- 在一定时间内过多地访问此网站(一般是用采集程序),被防火墙拒绝访问了。
- 站域名解析到了空间,但空间未绑定此域名。
- 的网页脚本文件在当前目录下没有执行权限。
- 不允许写/创建文件的目录中执行了创建/写文件操作。
- http 方式访问需要 ssl 连接的网址。
- 览器不支持 SSL 128 时访问 SSL 128 的连接。
- 身份验证的过程中输入了错误的密码。
- NS 解析错误,手动更改 DNS 服务器地址。
- 连接的用户过多,可以过后再试。
- 服务器繁忙,同一 IP 地址发送请求过多,遭到服务器智能屏蔽。
404 Not Found
请求失败,请求所希望得到的资源未被在服务器上发现。没有信息能够告诉用户这个状况到底是暂时的还是永久的。假如服务器知道情况的话,应当使用 410 状态码来告知旧资源因为某些内部的配置机制问题,已经永久的不可用,而且没有任何可以跳转的地址。404 这个状态码被广泛应用于当服务器不想揭示到底为何请求被拒绝或者没有其他适合的响应可用的情况下。
405 Method Not Allowed
请求行中指定的请求方法不能被用于请求相应的资源。该响应必须返回一个 Allow 头信息用以表示出当前资源能够接受的请求方法的列表。 鉴于 PUT,DELETE 方法会对服务器上的资源进行写操作,因而绝大部分的网页服务器都不支持或者在默认配置下不允许上述请求方法,对于此类请求均会返回 405 错误。
服务端响应
500 Internal Server Error
服务器遇到了不知道如何处理的情况。
503 Service Unavailable
服务器没有准备好处理请求。 常见原因是服务器因维护或重载而停机。 请注意,与此响应一起,应发送解释问题的用户友好页面。 这个响应应该用于临时条件和 Retry-After:如果可能的话,HTTP 头应该包含恢复服务之前的估计时间。 网站管理员还必须注意与此响应一起发送的与缓存相关的标头,因为这些临时条件响应通常不应被缓存。
504 Gateway Timeout
当服务器作为网关,不能及时得到响应时返回此错误代码。
HTTP 首部字段
概述
HTTP/1.1 一共规范了 47 种首部字段
结构
HTTP 首部字段是由首部字段名和字段值构成的,中间用冒号”:”分隔。
另外,字段值对应单个 HTTP 首部字段可以有多个值。
当 HTTP 报文首部中出现了两个或以上具有相同首部字段名的首部字段时,这种情况在规范内尚未明确,根据浏览器内部处理逻辑的不同,优先处理的顺序可能不同,结果可能并不一致。
大写驼峰 @@@
分类
首部字段根据实际用途被分为以下 4 种类型:
| 类型 | 描述 |
|---|---|
| 通用首部字段 | 请求报文和响应报文两方都会使用的首部 |
| 请求首部字段 | 从客户端向服务器端发送请求报文时使用的首部。补充了请求的附加内容、客户端信息、响应内容相关优先级等信息 |
| 响应首部字段 | 从服务器端向客户端返回响应报文时使用的首部。补充了响应的附加内容,也会要求客户端附加额外的内容信息。 |
| 实体首部字段 | 针对请求报文和响应报文的实体部分使用的首部。补充了资源内容更新时间等与实体有关的的信息。 |
通用首部字段
一览
| 首部字段名 | 说明 |
|---|---|
| Cache-Control | 控制缓存的行为 |
| Connection | 逐条首部、连接的管理 |
| Date | 创建报文的日期时间 |
| Pragma | 报文指令 |
| Trailer | 报文末端的首部一览 |
| Transfer-Encoding | 指定报文主体的传输编码方式 |
| Upgrade | 升级为其他协议 |
| Via | 代理服务器的相关信息 |
| Warning | 错误通知 |
Cache-Control 控制缓存
Connection 连接管理、逐跳首部
Connection 首部字段具备以下两个作用:
控制不再转发的首部字段
不转发 upgrade 字段
Connection: Upgrade
在客户端发送请求和服务器返回响应中,使用 Connection 首部字段,可控制不再转发给代理的首部字段,即删除后再转发(即 Hop-by-hop 首部)。
管理持久连接
HTTP/1.1 版本的默认连接都是持久连接。当服务器端想明确断开连接时,则指定 Connection 首部字段的值为 close。
Connection: close
Connection: Keep - Alive;
HTTP/1.1 之前的 HTTP 版本的默认连接都是非持久连接。为此,如果想在旧版本的 HTTP 协议上维持持续连接,则需要指定 Connection 首部字段的值为 Keep-Alive。
Date 创建报文的日期
表明创建 HTTP 报文的日期和时间
Date: Mon, 10 Jul 2017 15:50:06 GMT
HTTP/1.1 协议使用在 RFC1123 中规定的日期时间的格式。
Pragma 报文指令
缓存相关字段
Trailer
首部字段 Trailer 会事先说明在 报文主体后记录了哪些首部字段。可应用在 HTTP/1.1 版本分块传输编码时。
Trailer: Expires;
Transfor-Encoding
报文主体的传输编码格式
Transfer-Encoding: chunked
规定了传输报文主体时采用的编码方式。
HTTP/1.1 的传输编码方式仅对 分块传输编码 有效。
Upgrade
升级为其他协议
Upgrade: TSL/1.0
用于检测 HTTP 协议及其他协议是否可使用更高的版本进行通信,其参数值可以用来指定一个完全不同的通信协议。
Via
代理服务器的相关信息
Via: 1.1 a1.sample.com(Squid/2.7)
为了追踪客户端和服务器端之间的请求和响应报文的传输路径。
报文经过代理或网关时,会现在首部字段 Via 中附加该服务器的信息,然后再进行转发。
首部字段 Via 不仅用于追踪报文的转发,还可避免请求回环的发生。
Wraning
错误和警告通知
该首部字段通常会告知用户一些与缓存相关的问题的警告。
Warning 首部字段的格式如下:
Warning:[警告码][警告的主机:端口号] "[警告内容]"([日期时间])
最后的日期时间可省略。
HTTP/1.1 中定义了 7 种警告,警告码对应的警告内容仅推荐参考,另外,警告码具备扩展性,今后有可能追加新的警告码。
| 警告码 | 警告内容 | 说明 |
|---|---|---|
| 110 | Response is stale(响应已过期) | 代理返回已过期的资源 |
| 111 | Revalidation failed(再验证失败) | 代理再验证资源有效性时失败(服务器无法到达等原因) |
| 112 | Disconnection operation(断开连接操作) | 代理与互联网连接被故意切断 |
| 113 | Heuristic expiration(试探性过期) | 响应的试用期超过 24 小时 (有效缓存的设定时间大于 24 小时的情况下) |
| 199 | Miscellaneous warning(杂项警告) | 任意的警告内容 |
| 214 | Transformation applied(使用了转换) | 代理对内容编码或媒体类型等执行了某些处理时 |
| 299 | Miscellaneous persistent warning(持久杂项警告) | 任意的警告内容 |
请求首部字段
一览
| 首部字段名 | 说明 |
|---|---|
| Accept | 用户代理可处理的媒体类型 |
| Accept-Charset | 优先的字符集 |
| Accept-Encoding | 优先的内容编码 |
| Accept-Language | 优先的语言(自然语言) |
| Authorization | Web 认证信息 |
| Expect | 期待服务器的特定行为 |
| From | 用户的电子邮箱地址 |
| Host | 请求资源所在服务器 |
| If-Match | 比较实体标记(ETag),一致时处理该请求 |
| If-Modified-Since | 比较资源的更新时间 |
| If-None-Match | 比较实体标记(与 If-Macth 相反),不一致时处理该请求 |
| If-Range | 资源未更新时发送实体 Byte 的范围请求 |
| If-Unmodified-Since | 比较资源的更新时间 (与 If-Modified-Since 相反) |
| Max-Forwards | 最大传输逐跳数 |
| Proxy-Authorization | 代理服务器要求客户端的认证信息 |
| Range | 实体的字节范围请求 |
| Referer | 对请求中 URI 的原始获取方 |
| TE | 传输编码的优先级 |
| User-Agent | HTTP 客户端程序的信息 |
Accept
Accept 首部字段可通知服务器,用户代理能够处理的媒体类型及媒体类型的相对优先级。可使用 type/subtype 这种形式,一次指定多种媒体类型。
Accept: text/html, application/xhtml+xml, application/xml; q=0.5
若想要给显示的媒体类型增加优先级,则使用 q=[数值] 来表示权重值,用分号(;)进行分隔。权重值的范围 0~1(可精确到小数点后三位),且 1 为最大值。不指定权重值时,默认为 1
Accept-Charset
Accept-Charset 首部字段可用来通知服务器用户代理支持的字符集及字符集的相对优先顺序。另外,可一次性指定多种字符集。
Accept-Charset: iso-8859-5, unicode-1-1; q=0.8
同样使用 q=[数值] 来表示相对优先级
Accept-Encoding
Accept-Encoding 首部字段用来告知服务器用户代理支持的内容编码及内容编码的优先顺序,并可一次性指定多种内容编码。
Accept-Encoding: gzip, deflate
同样使用 q=[数值] 来表示相对优先级。也可使用星号(*)作为通配符,指定任意的编码格式
Accept-Language
告知服务器用户代理能够处理的自然语言集(指中文或英文等),以及自然语言集的相对优先级,可一次性指定多种自然语言集。
Accept-Lanuage: zh-cn,zh;q=0.7,en=us,en;q=0.3
同样使用 q=[数值] 来表示相对优先级
Authorization
告知服务器用户代理的认证信息(证书值)
Authorization: Basic ldfKDHKfkDdasSAEdasd==
通常,想要通过服务器认证的用户代理会在接收到返回的 401 状态码响应后,把首部字段 Authorization 加入请求中。共用缓存在接收到含有 Authorization 首部字段的请求时的操作处理会略有差异
Proxy-Authorization
接收到从代理服务器发来的认证质询时,客户端会发送包含首部字段 Proxy-Authorization 的请求,以告知服务器认证所需要的信息。
Proxy-Authorization: Basic dGlwOjkpNLAGfFY5
这个行为是与客户端和服务器之间的 HTTP 访问认证相类似的,不同之处在于,认证行为发生在客户端与代理之间。
Expect
告知服务器客户端期望出现的某种特定行为
Expect: 100-continue
From
告知服务器使用用户代理的电子邮件地址
From: [email protected]
Host
告知服务器,请求的资源所处的互联网主机和端口号
Host: andrewpqc.xyz
Host 首部字段是 HTTP/1.1 规范内 唯一一个必须被包含在请求内的首部字段
若服务器未设定主机名,那直接发送一个空值即可 Host:
If-XXX
形如 If-xxx 这种样式的请求首部字段,都可称为条件请求。服务器接收到附带条件的请求后,只有判断指定条件为真时,才会执行请求。
不光可以用于缓存,在普通的请求中也是经常使用的
If-Match
首部字段 If-Match,属附带条件之一,它会告知服务器匹配资源所用的实体标记(ETag)值。这时的服务器无法使用弱 ETag 值。
If-Match: "123456"
服务器会比对 If-Match 的字段值和资源的 ETag 值,仅当两者一致时,才会执行请求。反之,则返回状态码 412 Precondition Failed 的响应。
还可以使用星号(*)指定 If-Match 的字段值。针对这种情况,服务器将会忽略 ETag 的值,只要资源存在就处理请求。
If-None-Match
首部字段 If-None-Match 属于附带条件之一。它和首部字段 If-Match 作用相反。用于指定 If-None-Match 字段值的实体标记(ETag)值与请求资源的 ETag 不一致时,它就告知服务器处理该请求。
If-None-Match: "123456"
If-Modified-Since
首部字段 If-Modified-Since,属附带条件之一,用于确认代理或客户端拥有的本地资源的有效性
If-Modified-Since: Mon, 10 Jul 2017 15:50:06 GMT
它会告知服务器若 If-Modified-Since 字段值早于资源的更新时间,则希望能处理该请求。而在指定 If-Modified-Since 字段值的日期时间之后,如果请求的资源都没有过更新,则返回状态码 304 Not Modified 的响应。
If-Unmodified-Since
首部字段 If-Unmodified-Since 和首部字段 If-Modified-Since 的作用相反。它的作用的是告知服务器,指定的请求资源只有在字段值内指定的日期时间之后,未发生更新的情况下,才能处理请求。如果在指定日期时间后发生了更新,则以状态码 412 Precondition Failed 作为响应返回
If-Unmodified-Since: Mon, 10 Jul 2017 15:50:06 GMT
If-Range
首部字段 If-Range 属于附带条件之一。它告知服务器若指定的 If-Range 字段值(ETag 值或者时间)和请求资源的 ETag 值或时间相一致时,则作为范围请求处理。反之,则返回全体资源。
If-Range: "123456"
下面我们思考一下不使用首部字段 If-Range 发送请求的情况。服务器端的资源如果更新,那客户端持有资源中的一部分也会随之无效,当然,范围请求作为前提是无效的。这时,服务器会暂且以状态码 412 Precondition Failed 作为响应返回,其目的是催促客户端再次发送请求。这样一来,与使用首部字段 If-Range 比起来,就需要花费两倍的功夫
Range
对于只需获取部分资源的范围请求,包含首部字段 Range 即可告知服务器资源的指定范围。
Range: bytes=5001-10000
接收到附带 Range 首部字段请求的服务器,会在处理请求之后返回状态码为 206 Partial Content 的响应。无法处理该范围请求时,则会返回状态码 200 OK 的响应及全部资源。
Max-Forwards
通过 TRACE 方法或 OPTIONS 方法,发送包含首部字段 Max-Forwards 的请求时,该字段以十进制整数形式指定可经过的服务器最大数目。服务器在往下一个服务器转发请求之前,Max-Forwards 的值减 1 后重新赋值。当服务器接收到 Max-Forwards 值为 0 的请求时,则不再进行转发,而是直接返回响应。
Max-Forwards: 10
Referer
Referer 首部包含了当前请求页面的来源页面的地址,即表示当前页面是通过此来源页面里的链接进入的。
Referer: http://www.sample.com/index.html
TE
首部字段 TE 会告知服务器客户端能够处理响应的传输编码方式及相对优先级。它和首部字段 Accept-Encoding 的功能很相像,但是用于传输编码。
TE: gzip, deflate; q=0.5
首部字段 TE 除指定传输编码之外,还可以指定伴随 trailer 字段的分块传输编码的方式。应用后者时,只需把 trailers 赋值给该字段值。TE: trailers
User-Agent
首部字段 User-Agent 会将创建请求的浏览器和用户代理名称等信息传达给服务器。
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:13.0) Gecko/20100101
由网络爬虫发起请求时,有可能会在字段内添加爬虫作者的电子邮件地址。此外,如果请求经过代理,那么中间也很可能被添加上代理服务器的名称。
响应首部字段
一览
| 首部字段名 | 说明 |
|---|---|
| Accept-Ranges | 是否接受字节范围请求 |
| Age | 推算资源创建经过时间 |
| ETag | 资源的匹配信息 |
| Location | 令客户端重定向至指定 URI |
| Proxy-Authenticate | 代理服务器对客户端的认证信息 |
| Retry-After | 对再次发起请求的时机要求 |
| Server | HTTP 服务器的安装信息 |
| Vary | 代理服务器缓存的管理信息 |
| WWW-Authenticate | 服务器对客户端的认证信息 |
Accept-Ranges
首部字段 Accept-Ranges 是用来告知客户端服务器是否能处理范围请求,以指定获取服务器端某个部分的资源。
可指定的字段值有两种,可处理范围请求时指定其为 bytes,反之则指定其为 none。
Accept-Ranges: bytes
Age
首部字段 Age 能告知客户端,源服务器在多久前创建了响应。字段值的单位为秒。
Age: 1200
若创建该响应的服务器是缓存服务器,Age 值是指缓存后的响应再次发起认证到认证完成的时间值。代理创建响应时必须加上首部字段 Age。
ETag
首部字段 ETag 能告知客户端实体标识。它是一种可将资源以字符串形式做唯一性标识的方式。服务器会为每份资源分配对应的 ETag 值。
另外,当资源更新时,ETag 值也需要更新。生成 ETag 值时,并没有统一的算法规则,而仅仅是由服务器来分配。
ETag 中有强 ETag 值和弱 ETag 值之分。强 ETag 值,不论实体发生多么细微的变化都会改变其值;
弱 ETag 值只用于提示资源是否相同。只有资源发生了根本改变,产生差异时才会改变 ETag 值。这时,会在字段值最开始处附加 W/: ETag: W/“usagi-1234”
ETag: "usagi-1234"
Location
使用首部字段 Location 可以将响应接收方引导至某个与请求 URI 位置不同的资源。
基本上,该字段会配合 3xx :Redirection 的响应,提供重定向的 URI。
几乎所有的浏览器在接收到包含首部字段 Location 的响应后,都会强制性地尝试对已提示的重定向资源的访问。
Location: http://www.sample.com/sample.html
Proxy-Authenticate
首部字段 Proxy-Authenticate 会把由代理服务器所要求的认证信息发送给客户端。
它与客户端和服务器之间的 HTTP 访问认证的行为相似,不同之处在于其认证行为是在客户端与代理之间进行的。
Proxy-Authenticate: Basic realm="Usagidesign Auth"
Retry-After
首部字段 Retry-After 告知客户端应该在多久之后再次发送请求。主要配合状态码 503 Service Unavailable 响应,或 3xx Redirect 响应一起使用。
字段值可以指定为具体的日期时间(Mon, 10 Jul 2017 15:50:06 GMT 等格式),也可以是创建响应后的秒数
Retry-After: 180
Server
首部字段 Server 告知客户端当前服务器上安装的 HTTP 服务器应用程序的信息。不单单会标出服务器上的软件应用名称,还有可能包括版本号和安装时启用的可选项。
Server: Apache/2.2.6 (Unix) PHP/5.2.5
Vary
缓存相关
WWW-Authenticate
首部字段 WWW-Authenticate 用于 HTTP 访问认证。它会告知客户端适用于访问请求 URI 所指定资源的认证方案(Basic 或是 Digest)和带参数提示的质询(challenge)。
WWW-Authenticate: Basic realm="Usagidesign Auth"
实体首部字段
一览
| 首部字段名 | 说明 |
|---|---|
| Allow | 资源可支持的 HTTP 方法 |
| Content-Encoding | 实体主体适用的编码方式 |
| Content-Language | 实体主体的自然语言 |
| Content-Length | 实体主体的大小(单位:字节) |
| Content-Location | 替代对应资源的 URI |
| Content-MD5 | 实体主体的报文摘要 |
| Content-Range | 实体主体的位置范围 |
| Content-Type | 实体主体的媒体类型 |
| Expires | 实体主体过期的日期时间 |
| Last-Modified | 资源的最后修改日期时间 |
Allow
首部字段 Allow 用于通知客户端能够支持 Request-URI 指定资源的所有 HTTP 方法。
当服务器接收到不支持的 HTTP 方法时,会以状态码 405 Method Not Allowed 作为响应返回。与此同时,还会把所有能支持的 HTTP 方法写入首部字段 Allow 后返回
Allow: GET, HEAD
Content-Encoding
首部字段 Content-Encoding 会告知客户端服务器对实体的主体部分选用的内容编码方式。内容编码是指在不丢失实体信息的前提下所进行的压缩。
主要采用这 4 种内容编码的方式(gzip、compress、deflate、identity)
Content-Encoding: gzip
Content-Language
首部字段 Content-Language 会告知客户端,实体主体使用的自然语言(指中文或英文等语言)
Content-Language: zh-CN
Content-Length
首部字段 Content-Length 表明了实体主体部分的大小(单位是字节)。对实体主体进行内容编码传输时,不能再使用 Content-Length 首部字段。
Content-Length: 15000
Content-Location
首部字段 Content-Location 给出与报文主体部分相对应的 URI。和首部字段 Location 不同,Content-Location 表示的是报文主体返回资源对应的 URI。
Content-Location: http://www.sample.com/index.html
Content-MD5
首部字段 Content-MD5 是一串由 MD5 算法生成的值,其目的在于检查报文主体在传输过程中是否保持完整,以及确认传输到达。
Content-MD5: OGFkZDUwNGVhNGY3N2MxMDIwZmQ4NTBmY2IyTY==
Content-Range
针对范围请求,返回响应时使用的首部字段 Content-Range,能告知客户端作为响应返回的实体的哪个部分符合范围请求。字段值以字节为单位,表示当前发送部分及整个实体大小。
Content-Range: bytes 5001-10000/10000
Content-Type
首部字段 Content-Type 说明了实体主体内对象的媒体类型。和首部字段 Accept 一样,字段值用 type/subtype 形式赋值。参数 charset 使用 iso-8859-1 或 euc-jp 等字符集进行赋值
Content-Type: text/html; charset=UTF-8
Expires
Last-Modified
首部字段 Last-Modified 指明资源最终修改的时间。一般来说,这个值就是 Request-URI 指定资源被修改时间。但类似使用 CGI 脚本进行动态数据处理时,该值有可能会变成数据最终修改时的时间。
与 Cookie 相关的字段
| 首部字段名 | 说明 | 首部类型 |
|---|---|---|
| Set-Cookie | 开始状态管理所使用的 Cookie 信息 | 响应首部字段 |
| Cookie | 服务器接收到的 Cookie 信息 | 请求首部字段 |
缓存相关的字段
其他字段
https://andrewpqc.github.io/2018/07/15/http2/
字段操作
如何在浏览器端操作 Http 请求的首部字段?
cookie 相关字段
XMLHttpRequest.setRequestHeader()
fetch(request,{headers})
koa: ctx.response.header
如果在服务器端操作 Http 响应的首部字段?
koa2:ctx.headers
*web 资源 URI
HTTP 请求的内容通称为 " 资源 "。”资源“这一概念非常宽泛,它可以是一份文档,一张图片,或所有其他你能够想到的格式。每个资源都由一个 (URI) 来进行标识。
一般情况下,资源的名称和位置由同一个 URL(统一资源定位符,它是 URI 的一种)来标识。也有某些特殊情况,资源的名称和位置由不同的 URI 进行标识:例如,待请求的资源希望客户端从另外一个位置访问它。我们可以使用一个特定的首部字段,Alt-Svc,来指示这种情况。

URLs 与 URNs
URLs
URI 的最常见形式是统一资源定位符 (URL),它也被称为 Web 地址。
https://developer.mozilla.org https://developer.mozilla.org/en-US/docs/Learn/
https://developer.mozilla.org/en-US/search?q=URL
在浏览器的地址栏中输入上述任一地址,浏览器就会加载相应的网页(资源)。
URL 由多个必须或可选的组件构成。下面给出了一个复杂的 URL:
http://www.example.com:80/path/to/myfile.html?key1=value1&key2=value2#SomewhereInTheDocument
URNs
URN 是另一种形式的 URI,它通过特定命名空间中的唯一名称来标识资源。
urn:isbn:9780141036144 urn:ietf:rfc:7230
上面两个 URN 标识了下面的资源:
- 乔治·奥威尔所著的《1984》
- IETF 规范 7230,超文本传输协议 (HTTP/1.1):Message Syntax and Routing.
统一资源标识符的语法
方案或协议

“http://” 告诉浏览器使用何种协议。对于大部分 Web 资源,通常使用 HTTP 协议或其安全版本,HTTPS 协议。另外,浏览器也知道如何处理其他协议。例如, “mailto:” 协议指示浏览器打开邮件客户端;“ftp:”协议指示浏览器处理文件传输。常见的方案有:
| 方案 | 描述 |
|---|---|
| data | Data URIs |
| file | 指定主机上文件的名称 |
| ftp | 文件传输协议 |
| http/https | 超文本传输协议/安全的超文本传输协议 |
| mailto | 电子邮件地址 |
| ssh | 安全 shell |
| tel | 电话 |
| urn | 统一资源名称 |
| view-source | 资源的源代码 |
| ws/wss | (加密的) WebSocket 连接 |
主机

www.example.com 既是一个域名,也代表管理该域名的机构。它指示了需要向网络上的哪一台主机发起请求。当然,也可以直接向主机的 IP address 地址发起请求。但直接使用 IP 地址的场景并不常见。
端口

:80 是端口。它表示用于访问 Web 服务器上资源的技术“门”。如果访问的该 Web 服务器使用 HTTP 协议的标准端口(HTTP 为 80,HTTPS 为 443)授予对其资源的访问权限,则通常省略此部分。否则端口就是 URI 必须的部分。
路径

/path/to/myfile.html 是 Web 服务器上资源的路径。在 Web 的早期,类似这样的路径表示 Web 服务器上的物理文件位置。现在,它主要是由没有任何物理实体的 Web 服务器抽象处理而成的。
查询

?key1=value1&key2=value2 是提供给 Web 服务器的额外参数。这些参数是用 & 符号分隔的键/值对列表。Web 服务器可以在将资源返回给用户之前使用这些参数来执行额外的操作。每个 Web 服务器都有自己的参数规则,想知道特定 Web 服务器如何处理参数的唯一可靠方法是询问该 Web 服务器所有者。
片段

#SomewhereInTheDocument 是资源本身的某一部分的一个锚点。锚点代表资源内的一种“书签”,它给予浏览器显示位于该“加书签”点的内容的指示。 例如,在 HTML 文档上,浏览器将滚动到定义锚点的那个点上;在视频或音频文档上,浏览器将转到锚点代表的那个时间。值得注意的是 # 号后面的部分,也称为片段标识符,永远不会与请求一起发送到服务器。
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Basics_of_HTTP/Identifying_resources_on_the_Web
https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Basics_of_HTTP
HTTP Cookie @link
HTTP CORS @link
HTTP 缓存 @link
Web Storage @link
IndexedDB
Web 服务器
这里不关心服务器是 Apache 还是 Nginx,而是在于服务器的作用。一台服务器可以作为源服务器,也可以作为中转服务器,甚至可以在一台服务器上搭建多个不同域名的网站。
虚拟主机
HTTP/1.1 规范允许一台 HTTP 服务器搭建多个 Web 站点。利用虚拟主机的功能,可以在一台物理服务器(一个 IP 地址)上虚拟出多个主机,每个主机映射一个独立的域名。因此,当用户访问域名 http://www.laogeng.com/ 时,DNS 域名系统会将其解析成 IP 地址,根据 IP 找到物理服务器,然后再通过请求首部的 HOST 字段(现在知道 HOST 为什么是 HTTP/1.1 强制要求携带的了吧)确认对应的虚拟主机。
代理服务器
代理服务器就是客户端和服务端之间的“中间商”,即 HTTP 请求通过代理服务器转发给服务器,再将服务器的响应返回给客户端的行为。代理服务器可以用来作为缓存服务器,也可以用来隐藏用户身份(正向代理)或者服务器身份(反向代理)增加安全性。
正向代理
所谓正向代理,是从客户/客户端角度出发,为了从源服务器中取得内容,由客户端向代理服务器发出请求,并 指定目标访问服务器,然后,代理服务器向源服务器转交需求,并将获得的内容返回给客户端。需要注意的是,在正向代理过程中隐藏了真实请求的客户端,即服务端不知道正式请求客户是谁。(科学上网)
不知道客户端是谁
反向代理
所谓反向代理,是从客户端发向反向代理出请求,反向代理服务器收到需求后判断请求走向何处,然后再将结果反馈给客户端。同样需要注意的是,在反向代理过程中,隐藏了内部服务器的信息,用户不需要知道是具体哪一台服务器提供的服务,只要知道反向代理服务器是谁就好了,我们甚至可以把反向代理服务器当做真正服务器看待。这种形式的代理通常被用作实现 负载均衡,比如 Nginx 就是一种出色的反向代理服务器。
不知道服务器是谁
缓存服务器
缓存服务器指的是将需要频繁访问的网络内容存放在离用户较近、访问速度更快的服务器中,以提高内容访问速度的一种技术。缓存服务器是浏览器和源服务器之间的中间服务器,浏览器先向这个中间服务器发起 HTTP 请求,经过处理后(比如权限验证,缓存匹配等),再将请求转发到源服务器。