worker
Web Worker
参考:https://wangdoc.com/javascript/bom/webworker.html
概述
JavaScript 语言采用的是单线程模型,也就是说,所有任务只能在一个线程上完成,一次只能做一件事。前面的任务没做完,后面的任务只能等着。随着电脑计算能力的增强,尤其是多核 CPU 的出现,单线程带来很大的不便,无法充分发挥计算机的计算能力。
Web Worker 的作用,就是为 JavaScript 创造多线程环境,允许主线程创建 Worker 线程,将一些任务分配给后者运行。在主线程运行的同时,Worker 线程在后台运行,两者互不干扰。等到 Worker 线程完成计算任务,再把结果返回给主线程。这样的好处是,一些计算密集型或高延迟的任务可以交由 Worker 线程执行,主线程(通常负责 UI 交互)能够保持流畅,不会被阻塞或拖慢。
Worker 线程一旦新建成功,就会始终运行,不会被主线程上的活动(比如用户点击按钮、提交表单)打断。这样有利于随时响应主线程的通信。但是,这也造成了 Worker 比较耗费资源,不应该过度使用,而且一旦使用完毕,就应该关闭。
限制
同源限制
- 分配给 Worker 线程运行的脚本文件,必须与主线程的脚本文件同源。
DOM 限制
- Worker 线程所在的全局对象,与主线程不一样,无法读取主线程所在网页的 DOM 对象,也无法使用
document、window、parent这些对象。但是,Worker 线程可以使用navigator对象和location对象。
全局对象限制
- Worker 的全局对象
WorkerGlobalScope,不同于网页的全局对象Window,很多接口拿不到。比如,理论上 Worker 线程不能使用console.log,因为标准里面没有提到 Worker 的全局对象存在console接口,只定义了Navigator接口和Location接口。不过,浏览器实际上支持 Worker 线程使用console.log,保险的做法还是不使用这个方法。
通信联系
- Worker 线程和主线程不在同一个上下文环境,它们不能直接通信,必须通过消息完成。
脚本限制
- Worker 线程不能执行
alert()方法和confirm()方法,但可以使用 XMLHttpRequest 对象发出 AJAX 请求。
文件限制
- Worker 线程无法读取本地文件,即不能打开本机的文件系统(
file://),它所加载的脚本,必须来自网络。
基本用法
主线程
主线程采用 new 命令,调用 Worker() 构造函数,新建一个 Worker 线程。
var worker = new Worker('work.js');
Worker() 构造函数的参数是一个脚本文件,该文件就是 Worker 线程所要执行的任务。由于 Worker 不能读取本地文件,所以这个脚本必须来自网络。如果下载没有成功(比如 404 错误),Worker 就会默默地失败。
然后,主线程调用 worker.postMessage() 方法,向 Worker 发消息。
worker.postMessage('Hello World');
worker.postMessage({method: 'echo', args: ['Work']});
worker.postMessage() 方法的参数,就是主线程传给 Worker 的数据。它可以是各种数据类型,包括二进制数据。
接着,主线程通过 worker.onmessage 指定监听函数,接收子线程发回来的消息。
worker.onmessage = function (event) {
doSomething(event.data);
}
function doSomething() {
// 执行任务
worker.postMessage('Work done!');
}
上面代码中,事件对象的 data 属性可以获取 Worker 发来的数据。
Worker 完成任务以后,主线程就可以把它关掉。
worker.terminate();
Worker 线程
Worker 线程内部需要有一个监听函数,监听 message 事件。
self.addEventListener('message', function (e) {
self.postMessage('You said: ' + e.data);
}, false);
上面代码中,self 代表子线程自身,即子线程的全局对象。因此,等同于下面两种写法。
// 写法一
this.addEventListener('message', function (e) {
this.postMessage('You said: ' + e.data);
}, false);
// 写法二
addEventListener('message', function (e) {
postMessage('You said: ' + e.data);
}, false);
除了使用 self.addEventListener() 指定监听函数,也可以使用 self.onmessage 指定。监听函数的参数是一个事件对象,它的 data 属性包含主线程发来的数据。self.postMessage() 方法用来向主线程发送消息。
根据主线程发来的数据,Worker 线程可以调用不同的方法,下面是一个例子。
self.addEventListener('message', function (e) {
var data = e.data;
switch (data.cmd) {
case 'start':
self.postMessage('WORKER STARTED: ' + data.msg);
break;
case 'stop':
self.postMessage('WORKER STOPPED: ' + data.msg);
self.close(); // Terminates the worker.
break;
default:
self.postMessage('Unknown command: ' + data.msg);
};
}, false);
上面代码中,self.close() 用于在 Worker 内部关闭自身。
Worker 加载脚本
Worker 内部如果要加载其他脚本,有一个专门的方法 importScripts()。
importScripts('script1.js');
该方法可以同时加载多个脚本。
importScripts('script1.js', 'script2.js');
错误处理
主线程可以监听 Worker 是否发生错误。如果发生错误,Worker 会触发主线程的 error 事件。
worker.onerror(function (event) {
console.log([
'ERROR: Line ', event.lineno, ' in ', event.filename, ': ', event.message
].join(''));
});
// 或者
worker.addEventListener('error', function (event) {
// ...
});
Worker 内部也可以监听 error 事件。
关闭 Worker
使用完毕,为了节省系统资源,必须关闭 Worker。
// 主线程
worker.terminate();
// Worker 线程
self.close();
数据通信
前面说过,主线程与 Worker 之间的通信内容,可以是文本,也可以是对象。需要注意的是,这种通信是拷贝关系,即是传值而不是传址,Worker 对通信内容的修改,不会影响到主线程。事实上,浏览器内部的运行机制是,先将通信内容串行化,然后把串行化后的字符串发给 Worker,后者再将它还原。
主线程与 Worker 之间也可以交换二进制数据,比如 File、Blob、ArrayBuffer 等类型,也可以在线程之间发送。下面是一个例子。
// 主线程
var uInt8Array = new Uint8Array(new ArrayBuffer(10));
for (var i = 0; i < uInt8Array.length; ++i) {
uInt8Array[i] = i * 2; // [0, 2, 4, 6, 8,...]
}
worker.postMessage(uInt8Array);
// Worker 线程
self.onmessage = function (e) {
var uInt8Array = e.data;
postMessage('Inside worker.js: uInt8Array.toString() = ' + uInt8Array.toString());
postMessage('Inside worker.js: uInt8Array.byteLength = ' + uInt8Array.byteLength);
};
但是,拷贝方式发送二进制数据,会造成性能问题。比如,主线程向 Worker 发送一个 500MB 文件,默认情况下浏览器会生成一个原文件的拷贝。为了解决这个问题,JavaScript 允许主线程把二进制数据直接转移给子线程,但是一旦转移,主线程就无法再使用这些二进制数据了,这是为了防止出现多个线程同时修改数据的麻烦局面。这种转移数据的方法,叫做 Transferable Objects。这使得主线程可以快速把数据交给 Worker,对于影像处理、声音处理、3D 运算等就非常方便了,不会产生性能负担。
如果要直接转移数据的控制权,就要使用下面的写法。
// Transferable Objects 格式
worker.postMessage(arrayBuffer, [arrayBuffer]);
// 例子
var ab = new ArrayBuffer(1);
worker.postMessage(ab, [ab]);
同页面的 Web Worker
通常情况下,Worker 载入的是一个单独的 JavaScript 脚本文件,但是也可以载入与主线程在同一个网页的代码。
<!DOCTYPE html>
<body>
<script id="worker" type="app/worker">
addEventListener('message', function () {
postMessage('some message');
}, false);
</script>
</body>
</html>
上面是一段嵌入网页的脚本,注意必须指定 <script> 标签的 type 属性是一个浏览器不认识的值,上例是 app/worker。
然后,读取这一段嵌入页面的脚本,用 Worker 来处理。
var blob = new Blob([document.querySelector('#worker').textContent]);
var url = window.URL.createObjectURL(blob);
var worker = new Worker(url);
worker.onmessage = function (e) {
// e.data === 'some message'
};
上面代码中,先将嵌入网页的脚本代码,转成一个二进制对象,然后为这个二进制对象生成 URL,再让 Worker 加载这个 URL。这样就做到了,主线程和 Worker 的代码都在同一个网页上面。
实例:Worker 线程完成轮询
有时,浏览器需要轮询服务器状态,以便第一时间得知状态改变。这个工作可以放在 Worker 里面。
function createWorker(f) {
var blob = new Blob(['(' + f.toString() + ')()']);
var url = window.URL.createObjectURL(blob);
var worker = new Worker(url);
return worker;
}
var pollingWorker = createWorker(function (e) {
var cache;
function compare(new, old) { ... };
setInterval(function () {
fetch('/my-api-endpoint').then(function (res) {
var data = res.json();
if (!compare(data, cache)) {
cache = data;
self.postMessage(data);
}
})
}, 1000)
});
pollingWorker.onmessage = function () {
// render data
}
pollingWorker.postMessage('init');
上面代码中,Worker 每秒钟轮询一次数据,然后跟缓存做比较。如果不一致,就说明服务端有了新的变化,因此就要通知主线程。
实例: Worker 新建 Worker
Worker 线程内部还能再新建 Worker 线程(目前只有 Firefox 浏览器支持)。下面的例子是将一个计算密集的任务,分配到 10 个 Worker。
主线程代码如下。
var worker = new Worker('worker.js');
worker.onmessage = function (event) {
document.getElementById('result').textContent = event.data;
};
Worker 线程代码如下。
// worker.js
// settings
var num_workers = 10;
var items_per_worker = 1000000;
// start the workers
var result = 0;
var pending_workers = num_workers;
for (var i = 0; i < num_workers; i += 1) {
var worker = new Worker('core.js');
worker.postMessage(i * items_per_worker);
worker.postMessage((i + 1) * items_per_worker);
worker.onmessage = storeResult;
}
// handle the results
function storeResult(event) {
result += event.data;
pending_workers -= 1;
if (pending_workers <= 0)
postMessage(result); // finished!
}
上面代码中,Worker 线程内部新建了 10 个 Worker 线程,并且依次向这 10 个 Worker 发送消息,告知了计算的起点和终点。计算任务脚本的代码如下。
// core.js
var start;
onmessage = getStart;
function getStart(event) {
start = event.data;
onmessage = getEnd;
}
var end;
function getEnd(event) {
end = event.data;
onmessage = null;
work();
}
function work() {
var result = 0;
for (var i = start; i < end; i += 1) {
// perform some complex calculation here
result += 1;
}
postMessage(result);
close();
}
API
主线程
构造函数 Worker()
浏览器原生提供 Worker() 构造函数,用来供主线程生成 Worker 线程。
var myWorker = new Worker(jsUrl, options);
参数
-
第一个参数是脚本的网址(必须遵守同源政策),该参数是必需的,且只能加载 JS 脚本,否则会报错。
-
第二个参数是配置对象,该对象可选。它的一个作用就是指定 Worker 的名称,用来区分多个 Worker 线程。
// 主线程 var myWorker = new Worker('worker.js', { name : 'myWorker' }); // Worker 线程 self.name // myWorker
返回值
- 构造函数返回一个 Worker 线程对象,用来供主线程操作 Worker。Worker 线程对象的属性和方法如下。
- Worker.onerror:指定 error 事件的监听函数。
- Worker.onmessage:指定 message 事件的监听函数,发送过来的数据在
Event.data属性中。 - Worker.onmessageerror:指定 messageerror 事件的监听函数。发送的数据无法序列化成字符串时,会触发这个事件。
- Worker.postMessage():向 Worker 线程发送消息。
- Worker.terminate():立即终止 Worker 线程。
Worker 线程
-
Web Worker 有自己的全局对象,不是主线程的
window,而是一个专门为 Worker 定制的全局对象。因此定义在window上面的对象和方法不是全部都可以使用。 -
Worker 线程有一些自己的全局属性和方法。
- self.name: Worker 的名字。该属性只读,由构造函数指定。
- self.onmessage:指定
message事件的监听函数。 - self.onmessageerror:指定 messageerror 事件的监听函数。发送的数据无法序列化成字符串时,会触发这个事件。
- self.close():关闭 Worker 线程。
- self.postMessage():向产生这个 Worker 的线程发送消息。
- self.importScripts():加载 JS 脚本。
SharedWorker
- WebWorker 只属于某个页面,不会和其他页面的 Render 进程(浏览器内核进程)共享
- 所以 Chrome 在 Render 进程中(每一个 Tab 页就是一个 render 进程)创建一个新的线程来运行 Worker 中的 JavaScript 程序。
- SharedWorker 是浏览器所有页面共享的,不能采用与 Worker 同样的方式实现,因为它不隶属于某个 Render 进程,可以为多个 Render 进程共享使用
- 所以 Chrome 浏览器为 SharedWorker 单独创建一个进程来运行 JavaScript 程序,在浏览器中每个相同的 JavaScript 只存在一个 SharedWorker 进程,不管它被创建多少次。
- 看到这里,应该就很容易明白了,本质上就是进程和线程的区别。SharedWorker 由独立的进程管理,WebWorker 只是属于 render 进程下的一个线程
Service Worker
概述
背景
有一个困扰 web 用户多年的难题——丢失网络连接。即使是世界上最好的 web app,如果下载不了它,也是非常糟糕的体验。如今虽然已经有很多种技术去尝试着解决这一问题。而随着 离线 页面的出现,一些问题已经得到了解决。但是,最重要的问题是,仍然没有一个好的统筹机制对资源缓存和自定义的网络请求进行控制。
之前的尝试 — AppCache — 看起来是个不错的方法,因为它可以很容易地指定需要离线缓存的资源。但是,它假定你使用时会遵循诸多规则,如果你不严格遵循这些规则,它会把你的 APP 搞得一团糟。关于 APPCache 的更多详情,请看 Jake Archibald 的文章: Application Cache is a Douchebag.
从 Firefox44 起,当使用 AppCache 来提供离线页面支持时,会提示一个警告消息,来建议开发者使用 Service workers 来实现离线页面。(bug 1204581.)
Service worker 最终要去解决这些问题。虽然 Service Worker 的语法比 AppCache 更加复杂,但是你可以使用 JavaScript 更加精细地控制 AppCache 的静默行为。有了它,你可以解决目前离线应用的问题,同时也可以做更多的事。
Service Worker 可以使你的应用先访问本地缓存资源,所以在离线状态时,在没有通过网络接收到更多的数据前,仍可以提供基本的功能(一般称之为 Offline First)。这是原生 APP 本来就支持的功能,这也是相比于 web app,原生 app 更受青睐的主要原因
Worker
对于 Service Worker ,了解过 Web Worker 的同学可能会比较好理解。它和 Web Worker 相比,有相同的点,也有不同的地方。
相同:
- Service Worker 工作在 worker context 中,是没有访问 DOM 的权限的,所以我们无法在 Service Worker 中获取 DOM 节点,也无法在其中操作 DOM 元素;
- 我们可以通过
postMessage接口把数据传递给其他 JS 文件; - Service Worker 中运行的代码不会被阻塞,也不会阻塞其他页面的 JS 文件中的代码;
不同的地方在于,Service Worker 是一个浏览器中的进程而不是浏览器内核下的线程,因此它在被注册安装之后,能够被在多个页面中使用,也不会因为页面的关闭而被销毁。因此,Service Worker 很适合被用与多个页面需要使用的复杂数据的计算——购买一次,全家“收益”。
使用前的设置
在已经支持 serivce workers 的浏览器的版本中,很多特性没有默认开启。如果你发现示例代码在当前版本的浏览器中怎么样都无法正常运行,你可能需要开启一下浏览器的相关配置:
- Firefox Nightly: 访问
about:config并设置dom.serviceWorkers.enabled的值为 true; 重启浏览器; - Chrome Canary: 访问
chrome://flags并开启experimental-web-platform-features; 重启浏览器 (注意:有些特性在 Chrome 中没有默认开放支持); - Opera: 访问
opera://flags并开启ServiceWorker 的支持; 重启浏览器。
另外,你需要通过 HTTPS 来访问你的页面 — 出于安全原因,Service Workers 要求必须在 HTTPS 下才能运行。Github 是个用来测试的好地方,因为它就支持 HTTPS。
为了便于本地开发,localhost 也被浏览器认为是安全源。
基本步骤
-
service worker URL 通过
serviceWorkerContainer.register()来获取和注册。 -
如果注册成功,service worker 就在
ServiceWorkerGlobalScope环境中运行; 这是一个特殊类型的 woker 上下文运行环境,与主运行线程(执行脚本)相独立,同时也没有访问 DOM 的能力。 -
service worker 现在可以处理事件了。
-
受 service worker 控制的页面打开后会尝试去安装 service worker。最先发送给 service worker 的事件是安装事件,在这个事件里可以开始进行填充 IndexDB 和缓存站点资源
这个流程同原生 APP 或者 Firefox OS APP 是一样的 — 让所有资源可离线访问。
-
当
oninstall事件的处理程序执行完毕后,可以认为 service worker 安装完成了 -
下一步是激活。当 service worker 安装完成后,会接收到一个激活事件(activate event)。
onactivate主要用途是清理先前版本的 service worker 脚本中使用的资源。 -
Service Worker 现在可以控制页面了,但仅是在
register()成功后的打开的页面。也就是说,页面起始于有没有 service worker ,会在页面的接下来生命周期内维持这个状态。所以,页面不得不重新加载以让 service worker 获得完全的控制。
生命周期

事件
下图展示了 service worker 所有支持的事件:

其中 Functional event 在激活后(activated) 才可以使用
注册 Worker
我们 app 的 JavaScript 文件里 — app.js — 的第一块代码就像下面的一样。这是我们使用 service worker 的入口:
if ('serviceWorker' in navigator) {
navigator.serviceWorker.register('/sw-test/sw.js', { scope: '/sw-test/' }).then(function(reg) {
// registration worked
console.log('Registration succeeded. Scope is ' + reg.scope);
}).catch(function(error) {
// registration failed
console.log('Registration failed with ' + error);
});
}
-
外面的代码块做了一个特性检查,在注册之前确保 service worker 是支持的。
-
接着,我们使用
ServiceWorkerContainer.register()函数来注册 站点的 service worker,service worker 只是一个驻留在我们的 app 内的一个 JavaScript 文件注意,这个文件的 url 是相对于 origin, 而不是相对于引用它的那个 JS 文件。
-
scope参数是选填的,可以被用来指定你想让 service worker 控制的内容的子目录。 在这个例子例,我们指定了'/sw-test/',表示 app 的 origin 下的所有内容。如果你留空的话,默认值也是这个值, 我们在指定只是作为例子。 -
register 方法返回一个 Promise 。如果注册失败,可以通过 catch 来捕获错误信息;如果注册成功,可以使用 then 来获取一个
ServiceWorkerRegistration的实例。 -
.then()函数链式调用我们的 promise,当 注册成功 的时候,里面的代码就会执行。 -
最后面我们链了一个
.catch()函数,当 promise rejected 才会执行。
这就注册了一个 service worker,它工作在 worker context,所以没有访问 DOM 的权限。在正常的页面之外运行 service worker 的代码来控制它们的加载。
单个 service worker 可以控制很多页面。每个你的 scope 里的页面加载完的时候,安装在页面的 service worker 可以控制它。
最大的 scope 是 service worker 所在的地址
如果你的 service worker 被激活在一个有 Service-Worker-Allowed header 的客户端,你可以为 service worker 指定一个最大的 scope 的列表。
牢记你需要小心 service worker 脚本里的全局变量: 每个页面不会有自己独有的 worker。
在同一个 Origin 下,我们可以注册多个 Service Worker。但是请注意,这些 Service Worker 所使用的 scope 必须是不相同的。
if ('serviceWorker' in window.navigator) {
navigator.serviceWorker.register('./sw/sw.js', { scope: './sw' })
.then(function (reg) {
console.log('success', reg);
})
navigator.serviceWorker.register('./sw2/sw2.js', { scope: './sw2' })
.then(function (reg) {
console.log('success', reg);
})
}
注意
关于 service workers 一个很棒的事情就是,如果你用像上面一样的浏览器特性检测方式发现浏览器并不支持。与此同时,如果你同时使用在一个页面上同时使用 AppCache 和 SW , 不支持 SW 但是支持 AppCache 的浏览器,可以使用 AppCache,如果都支持的话,则会采用 SW
在 Firefox, Service Worker APIs 在用户在 private browsing mode 下会被隐藏而且无法使用。
导致注册失败的原因
你没有在 HTTPS 下运行你的程序
service worker 文件的地址没有写对— 需要相对于 origin , 而不是 app 的根目录。在我们的例子例, service worker 是在 https://mdn.github.io/sw-test/sw.js,app 的根目录是 https://mdn.github.io/sw-test/。应该写成 /sw-test/sw.js 而非 /sw.js.
如果是在本地调式,需要把所有的 /sw-test/ 替换成 ./
service worker 在不同的 origin 而不是你的 app 的,这是不被允许的。

安装和激活:指定静态缓存
你的 service worker 函数像一个代理服务器一样,允许你修改请求和响应,用他们的缓存替代它们等等。
在你的 service worker 注册之后,浏览器会尝试为你的页面或站点安装并激活它。
install 事件会在安装完成之后触发。install 事件一般是被用来填充你的浏览器的离线缓存能力。
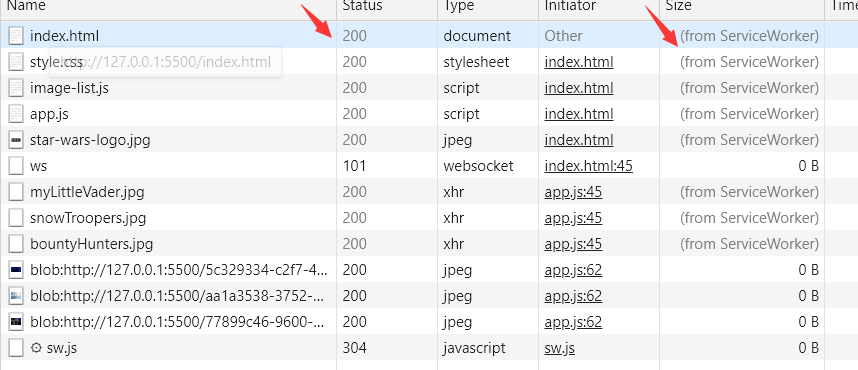
正常情况下,用户打开网页,浏览器会自动下载网页所需要的 JS 文件、图片等静态资源。我们可以通过 Chrome 开发工具的 Network 选项来查看。
但是如果用户在没有联网的情况下打开网页,浏览器就无法下载这些展示页面效果所必须的资源,页面也就无法正常的展示出来。
为了达成这个目的,我们使用了 Service Worker 的 新的标志性的存储 API — cache — 一个 service worker 上的全局对象,它使我们可以存储网络响应发来的资源,并且根据它们的请求来生成 key。这个 API 和浏览器的标准的缓存工作原理很相似,但是是特定你的域的,它会一直持久存在,直到你告诉它不再存储,你拥有全部的控制权。
注意: Cache API 并不被每个浏览器支持。(查看 Browser support 部分了解更多信息。) 如果你现在就想使用它,可以考虑采用一个 polyfill,比如 Google topeka demo,或者把你的资源存储在 IndexedDB 中。
可以在 sw.js 最开始,
self.importScripts('./serviceworker-cache-polyfill.js');,这里引入了 Cache API 的一个 polyfill,这个polyfill支持使得在较低版本的浏览器下也可以使用Cache Storage API。想要实现Service Worker的功能,一般都需要搭配Cache API代理网络请求到缓存中。在
Service Worker线程中,使用importScripts引入polyfill脚本,目的是对低版本浏览器的兼容。
让我们从一个代码示例来开始这个部分——sw.js
self.addEventListener('install', function(event) {
event.waitUntil(
caches.open('v1').then(function(cache) {
return cache.addAll([
'/sw-test/',
'/sw-test/index.html',
'/sw-test/style.css',
'/sw-test/app.js',
'/sw-test/image-list.js',
'/sw-test/star-wars-logo.jpg',
'/sw-test/gallery/bountyHunters.jpg',
'/sw-test/gallery/myLittleVader.jpg',
'/sw-test/gallery/snowTroopers.jpg'
]);
})
);
});
-
这里我们 新增了一个
install事件监听器,接着在事件上接了一个ExtendableEvent.waitUntil()方法——这会确保 Service Worker 不会在waitUntil()里面的代码执行完毕之前安装完成。 -
CacheStroage 在浏览器中的接口名是 caches ,我们使用
caches.open方法新建或打开一个已存在的缓存; -
由于资源的下载、缓存是异步行为,所以我们要使用事件对象提供的
event.waitUntil方法,它能够保证资源被缓存完成前 Service Worker 不会被安装完成,避免发生错误。 -
在
waitUntil()内,我们使用了caches.open()方法来创建了一个叫做v1的新的缓存,将会是我们的站点资源缓存的第一个版本。它返回了一个创建缓存的 promise,当它 resolved 的时候,我们接着会调用在创建的缓存示例上的一个方法addAll(),这个方法的参数是一个由一组相对于 origin 的 URL 组成的数组,这些 URL 就是你想缓存的资源的列表。 -
如果 promise 被 rejected,安装就会失败,这个 worker 不会做任何事情。这也是可以的,因为你可以修复你的代码,在下次注册发生的时候,又可以进行尝试。
-
当安装成功完成之后, service worker 就会激活。在第一次你的 service worker 注册/激活时,这并不会有什么不同。但是当 service worker 更新 (稍后查看 Updating your service worker 部分) 的时候 ,就不太一样了。
注意: localStorage 跟 service worker 的 cache 工作原理很类似,但是它是同步的,所以不允许在 service workers 内使用。
注意: IndexedDB 可以在 service worker 内做数据存储。
这时,我们可以在 Chorme 的开发者工具中看到我们注册的 Service Worker。
在默认情况下,Service Worker 必定会每 24 小时被下载一次,如果下载的文件是最新文件,那么它就会被重新注册和安装,但不会被激活,当不再有页面使用旧的 Service Worker 的时候,它就会被激活。
这对于我们开发来说是很不方便的,因此在这里我勾选了一个名为 Update on reload 的单选框,选中它之后,我们每次刷新页面都能够使用最新的 service worker 文件。
动态缓存和响应
Fetch 事件
现在你已经将你的站点资源缓存了,你需要告诉 service worker 让它用这些缓存内容来做点什么。有了 fetch 事件,这是很容易做到的。

每次任何被 service worker 控制的资源被请求到时,都会触发 fetch 事件,这些资源包括了指定的 scope 内的文档,和这些文档内引用的其他任何资源
比如
index.html发起了一个跨域的请求来嵌入一个图片,这个也会通过 service workerfetch 事件的触发,并不需要使用 fetch API
有一点需要注意,页面的路径不能大于 Service Worker 的 scope,不然 fetch 事件是无法被触发的。
你可以给 service worker 添加一个 fetch 的事件监听器,接着调用 event 上的 respondWith() 方法来劫持我们的 HTTP 响应,然后你用可以用自己的魔法来更新他们。
this.addEventListener('fetch', function(event) {
event.respondWith(
// magic goes here
);
});
我们可以用一个简单的例子开始,在任何情况下我们只是简单的响应这些缓存中的 url 和网络请求匹配的资源。
this.addEventListener('fetch', function(event) {
event.respondWith(
caches.match(event.request)
);
});
在回调函数中我们使用事件对象提供的 respondWith 方法,它可以劫持用户发出的 http 请求,并把一个 Promise 作为响应结果返回给用户。
caches.match(event.request) 允许我们对网络请求的资源和 cache 里可获取的资源进行匹配,查看是否缓存中有相应的资源。这个匹配通过 url 和 vary header 进行,就像正常的 http 请求一样。
当用户第一次访问页面的时候,资源的请求是早于 Service Worker 的安装的,所以静态资源是无法缓存的;只有当 Service Worker 安装完毕,用户第二次访问页面的时候,这些资源才会被缓存起来;
自定义响应
让我们看看我们在定义我们的魔法时的一些其他的选项 (查看 Fetch API documentation 了解更多有关 Request 和 Response 对象的更多信息。)
-
Response()构造函数允许你创建一个自定义的 response 。在这个例子中,我们只返回一个示例的字符串:this.addEventListener('fetch', function(event) { event.respondWith( new Response('Hello from your friendly neighbourhood service worker!') ) }); -
下面这个更复杂点的
Response展示了你可以在你的响应里选择性的传一系列 header ,来模仿标准的 HTTP 响应 header。这里我们只告诉浏览器我们虚假的响应的 content type:this.addEventListener('fetch', function(event) { event.respondWith( new Response('<p>Hello from your friendly neighbourhood service worker!</p>', { headers: { 'Content-Type': 'text/html' } }) ) }); -
如果没有在缓存中找到匹配的资源,你可以告诉浏览器对着资源直接去
fetch默认的网络请求:fetch(event.request) -
如果没有在缓存中找到匹配的资源,同时网络也不可用,你可以用
match()把一些回退的页面作为响应来匹配这些资源,比如:caches.match('/fallback.html'); -
你可以通过
FetchEvent返回的Request对象检索到非常多有关请求的信息:event.request.url event.request.method event.request.headers event.request.body
恢复失败的请求
在有 service worker cache 里匹配的资源时, caches.match(event.request) 是非常棒的。但是如果没有匹配资源呢?如果我们不提供任何错误处理,promise 就会 reject,同时也会出现一个网络错误。
幸运的是,service worker 的基于 promise 的结构,使得提供更多的成功的选项变得微不足道。 我们可以这样做:
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.match(event.request).then(function(response) {
return response || fetch(event.request);
})
);
});
如果 promise reject 了, catch() 函数会执行默认的网络请求,意味着在网络可用的时候可以直接像服务器请求资源。
如果我们足够聪明的话,我们就不会只是从服务器请求资源,而且还会把请求到的资源保存到缓存中,以便将来离线时所用!这意味着如果其他额外的图片被加入到 Star Wars 图库里,我们的 app 会自动抓取它们。下面就是这个诀窍:
self.addEventListener('fetch', function(event) {
event.respondWith(
caches.match(event.request).then(function(resp) {
return resp || fetch(event.request).then(function(response) {
return caches.open('v1').then(function(cache) {
cache.put(event.request, response.clone());
return response;
});
});
})
);
});
这里我们用 fetch(event.request) 返回了默认的网络请求,它返回了一个 promise 。
- 当网络请求的 promise 成功的时候,我们 通过执行一个函数用
caches.open('v1')来抓取我们的缓存,它也返回了一个 promise。 - 当这个 promise 成功的时候,
cache.put()被用来把这些资源加入缓存中。 - 资源是从
event.request抓取的,它的响应会被response.clone()克隆一份然后被加入缓存。这个克隆被放到缓存中,它的原始响应则会返回给浏览器来给调用它的页面。
为什么要这样做?这是因为请求和响应流只能被读取一次。为了给浏览器返回响应以及把它缓存起来,我们不得不克隆一份。所以原始的会返回给浏览器,克隆的会发送到缓存中。它们都是读取了一次。
当用户第一次访问页面的时候,资源的请求是早于 Service Worker 的安装的,所以静态资源是无法缓存的;只有当 Service Worker 安装完毕,用户第二次访问页面的时候,这些资源才会被缓存起来;
- Cache Stroage 只能缓存静态资源,所以它只能缓存用户的 GET 请求;
- Cache Stroage 中的缓存不会过期,但是浏览器对它的大小是有限制的,所以需要我们定期进行清理;
我们现在唯一的问题是当请求没有匹配到缓存中的任何资源的时候,以及网络不可用的时候,我们的请求依然会失败。让我们提供一个默认的回退方案以便不管发生了什么,用户至少能得到些东西:
self.addEventListener('fetch', function(event) {
event.respondWith(caches.match(event.request).then(function(response) {
// caches.match() always resolves
// but in case of success response will have value
if (response !== undefined) {
return response;
} else {
return fetch(event.request).then(function (response) {
// response may be used only once
// we need to save clone to put one copy in cache
// and serve second one
let responseClone = response.clone();
caches.open('v1').then(function (cache) {
cache.put(event.request, responseClone);
});
return response;
}).catch(function () {
return caches.match('/sw-test/gallery/myLittleVader.jpg');
});
}
}));
});
因为只有新图片会失败,我们已经选择了回退的图片,一切都依赖我们之前看到的 install 事件侦听器中的安装过程。
对于用户发起的 POST 请求,我们也可以在拦截后,通过判断请求中携带的 body 的内容来进行有选择的返回。
if(event.request.method === 'POST') {
event.respondWith(
new Promise(resolve => {
event.request.json().then(body => {
console.log(body); // 用户请求携带的内容
})
resolve(new Response({ a: 2 })); // 返回的响应
})
)
}
}
我们可以在 fetch 事件的回掉函数中对请求的 method 、url 等各项属性进行判断,选择不同的操作。
对于静态资源的缓存,Cache Stroage 是个不错的选择;而对于数据,我们可以使用 IndexedDB来存储,同样是拦截用户请求后,使用缓存在 IndexDB 中的数据作为响应返回,详细的内容我就不在这里讲了,有兴趣的同学可以自己去了解下。
更新你的 Service Worker
如果你的 service worker 已经被安装,但是刷新页面时有一个新版本的可用,新版的 service worker 会在后台安装,但是还没激活。当不再有任何已加载的页面在使用旧版的 service worker 的时候,新版本才会激活。一旦再也没有更多的这样已加载的页面,新的 service worker 就会被激活。
你想把你的新版的 service worker 里的 install 事件监听器改成下面这样(注意新的版本号):
self.addEventListener('install', function(event) {
event.waitUntil(
caches.open('v2').then(function(cache) {
return cache.addAll([
'/sw-test/',
'/sw-test/index.html',
'/sw-test/style.css',
'/sw-test/app.js',
'/sw-test/image-list.js',
…
// include other new resources for the new version...
]);
})
);
});
当安装发生的时候,前一个版本依然在响应请求,新的版本正在后台安装,我们调用了一个新的缓存 v2,所以前一个 v1 版本的缓存不会被扰乱。
当没有页面在使用当前的版本的时候,这个新的 service worker 就会激活并开始响应请求。
删除旧缓存
你还有个 activate 事件。当之前版本还在运行的时候,一般被用来做些会破坏它的事情,比如摆脱旧版的缓存。在避免占满太多磁盘空间清理一些不再需要的数据的时候也是非常有用的,每个浏览器都对 service worker 可以用的缓存空间有个硬性的限制。浏览器尽力管理磁盘空间,但它可能会删除整个域的缓存。浏览器通常会删除域下面的所有的数据。
传给 waitUntil() 的 promise 会阻塞其他的事件,直到它完成。所以你可以确保你的清理操作会在你的的第一次 fetch 事件之前会完成。
self.addEventListener('activate', function(event) {
var cacheWhitelist = ['v2'];
event.waitUntil(
caches.keys().then(function(keyList) {
return Promise.all(keyList.map(function(key) {
if (cacheWhitelist.indexOf(key) === -1) {
return caches.delete(key);
}
}));
})
);
});
首先在安装 Service Worker 的时候,要换一个 Cache Stroage 来存储,然后设置一个白名单,当 Service Worker 被激活的时候,将不在白名单中的 Cache Stroage 删除,释放存储空间。同样使用 event.waitUntil ,在 Service Worker 被激活前执行完删除操作。
信息和通讯
之前说过,使用 postMessage 方法可以进行 Service Worker 和页面之间的通讯,下面就让我们来试一下。
https://juejin.im/post/5b06a7b3f265da0dd8567513#heading-1
开发者工具
Chrome 有一个 chrome://inspect/#service-workers 可以展示当前设备上激活和存储的 service worker。
还有个 chrome://serviceworker-internals 可以展示更多细节来允许你开始/暂停/调试 worker 的进程。未来他们会支持流量调节控制/离线模式来模拟弱网或者没网状态,这也是非常好的。
Firefox 也开始实现一些关于 service worker 的有用的工具:
- 你可以访问 about:serviceworkers 来看注册了什么 SW,还可以更新和移除他们。
- 当测试时你想绕开 HTTPS 限制时,可以检查 Firefox Devtools 的选项 "Enable Service Workers over HTTP (when toolbox is open)" (齿轮图标)
Navigator.serviceWorker
只读属性
返回 关联文件 的 ServiceWorkerContainer 对象
let workerContainerInstance = navigator.serviceWorker;
Service Worker 是一个浏览器中的进程,可以通过 Navigator.serviceWorker 属性访问该进程对象,它提供对 ServiceWorker 的注册,删除,升级和通信的访问。
ServiceWorkerContainer
ServiceWorkerContainer 接口为 service worker 提供一个容器般的功能,包括对 service worker 的注册,卸载 ,更新和访问 service worker 的状态,以及他们的注册者
属性
ServiceWorkerContainer.controller
只读属性
当 ServiceWorker 对象的 state 是 active 的时候,返回一个 ServiceWorker 对象
和
ServiceWorkerRegistration.active) 返回相同的对象。
如果当前的 state 都不是 active 或者强制刷新浏览器则返回 null。
ServiceWorkerContainer.ready
只读
定义了一个 serviceWorker 是否准备好为一个页面服务,将返回一个 Promise,并且这个 Promise 永远不会 reject,这个 Promise 会在 ServiceWorkerRegistration 获取到一个 active 的 ServiceWorker 的时候被解决。
事件
方法
ServiceWorkerContainer.register()
-
register() 方法创建或更新一个给定
scriptURL的ServiceWorkerRegistration -
如果成功,一个服务工作者注册将提供的脚本 URL 与一个范围进行关联,后者用于导航匹配。如果该方法无法返回一个
ServiceWorkerRegistration,则返回一个Promise。 -
您可以从受控页无条件调用此方法, 即, 您不需要首先检查是否有一个有效的注册。
ServiceWorkerContainer.register(scriptURL, options) .then( function(ServiceWorkerRegistration) { // do something } );
参数
- scriptURL:service worker 脚本的 URL
- options:可选,注册时提供选项的配置对象。 目前可用的选项包括:
scope: 一个USVString,表示定义 service worker 注册范围的 URL ;service worker 可以控制的 URL 范围。通常是相对 URL。默认值是基于当前的 location,并以此来解析传入的路径
返回值
- 返回一个
Promise对象, 值是ServiceWorkerRegistration
self.skipWaiting() 执行,告知浏览器直接跳过等待阶段,淘汰过期的 sw.js 的 Service Worker 脚本,直接开始尝试激活新的 Service Worker。
推送
https://juejin.im/post/5bf3f6b2e51d45360069e527
配合 Webpack
https://juejin.im/post/5ba0fe356fb9a05d2c43a25c
https://juejin.im/post/5b4017c1f265da0fb0184fae
https://juejin.im/post/5cde2d24e51d45698161f63f
Service Worker Cache VS Http Cache
对比起 Http Header 缓存,Service Worker 配合 Cache Storage 也有自己的优势:
- 缓存与更新并存:每次更新版本,借助
Service Worker可以立马使用缓存返回,但与此同时可以发起请求,校验是否有新版本更新。 - 无侵入式:
hash值实在是太难看了。 - 不易被冲掉:
Http缓存容易被冲掉,也容易过期,而Cache Storage则不容易被冲掉。也没有过期时间的说法。 - 离线:借助
Service Worker可以实现离线访问应用。
但是缺点是,由于 Service Worker 依赖于 fetch API、依赖于 Promise、Cache Storage 等,兼容性不太好。
总结
Cache Storage 和 Service Worker 总是分不开的。Service Worker 的最佳用法其实就是配合 Cache Storage 做离线缓存。借助于 Service Worker,可以轻松实现对网络请求的控制,对于不同的网络请求,采取不同的策略。例如对于 Cache 的策略,其实也是存在多种情况。例如可以优先使用网络请求,在网络请求失败时再使用缓存、亦可以同时使用缓存和网络请求,一方面检查请求,一方面有检查缓存,然后看两个谁快,就用谁。
各种缓存对比
https://github.com/youngwind/blog/issues/113
https://github.com/amandakelake/blog/issues/43