!framework-common
如何学习一个新的框架
现代框架都是文档先行的, 一个优秀的框架, 文档肯定是不赖的.
不要像以前那样疯狂 copy 文档了
主要做 faq 和 对比总结类型的笔记
语法上的 Common 对比
可以直接使用 react 官网的 quick start 作为基础架构.
框架的官方文档的结构肯定是可以信赖的
NextTick
用宏任务和微任务来实现 nextTick,其实代码运行的时机是不一样的,用微任务是在渲染前,用宏任务会在渲染后
nextTick 其实只是在 dom 更新完之后,就可以拿到更新完的数据和 dom 了,页面没必要渲染,只需要 js 部分是最新的就行了
然后微任务和宏任务翻译的不好,还是用 task 和 job 来去即可,微任务的执行时间完全有可能比宏任务长
nextTIck
因为 js 是单线程的,在 setData 之后,到底什么时候派发 nextTickReach 是可以有选择的
- data 真正更新之后马上 reach,此时框架控制的节点树都还没更新呢,别说是真实的 dom 树了
- 等框架控制的节点树更新完之后派发,对于 san 就是 changes 传导到了每个节点的 _update 方法之后,对于 vue 和 react 就是 vDom 更新完毕之后
讨论的 issue:https://github.com/baidu/san/issues/141
vue 最新的源码:https://github.com/vuejs/vue/blob/dev/dist/vue.js
把 na 组件的插入操作放在 nextTick 中,可以延后执行 na 组件的插入操作,可以提升组件性能
san 的视图更新是异步的。组件数据变更后,将在下一个时钟周期更新视图。如果你修改了某些数据,想要在 DOM 更新后做某些事情,则需要使用
nextTick方法。san.dev.js 搜索 nextTick 即可
只能是 attached 之后了,感觉是类似 FMP 的一个逻辑,可以 san 组件实例已经走到 attached 了,再插入 NA 组件本身
用 cts 实例测试发现好几个 cover-view 都 attached 了 之后,此时很多 h5 的内容都已经上屏了,才进去第一个 nextTick
假如我有 1w 个 na 组件,也会在全部 attached 之后才到 nextTick 的轮次吗?感觉有可能哦
从上面的表现来看,我们这里的 nextTick 不就是宏任务的吗?不一定哦,因为 debugger 是可以挂起 js 线程的,alert 会占用 js 线程,并没有让给 gui,反而是 debugger 是让给了 gui 的
可以测试一下 nextTick 的微任务和宏任务了,无论是微任务还是宏任务,反正端能力都会异步的,除非是宏任务,可以做到保证在 h5 的组件渲染完成
我们现在 setImmediate 和 messageChannel 都是有的,所以是宏任务
san 的数据更新操作是异步的,会被打包在一个 nextTick 中。因此我们再使用 nextTick 可以获取到数据更新的 nextTick 之后的 data,微任务队列
还有一个点就是 dom 的更新和 UI 渲染是两个概念,因为 js 线程和渲染线程是互斥的,所以 UI 渲染之前,dom 就已经是更新完的了。
这就涉及到我们 dom api 获取的究竟是?肯定是从 dom 树入手的呀,render 树究竟是怎么样的,确实有部分 dom api 是从 render 树 入手的,但是有部分的 dom api 会强制渲染,这个时候会发生什么?
如果是 promise 这种微任务实现,当我们在 nextTick 中再次 setData,那么会在 UI 渲染前成功 setData
如果选择宏任务实现会在 UI 渲染之后,导致重新渲染,因此微任务应该是更好的选择,但是为什么 san 中优先选择了宏任务呢?vue 目前也是 promise 优先
我们 slave 触发的是哪个 nextTick 呢?我们组件代码运行在 slave 上,是 webview 环境,有 js 解释器 bom api dom api
我自己也是可以测试的,无论是 san 还是 vue,我需要有一个方法知道 dom 到底更新了没有,还需要明确一点 dom 更新和 UI 渲染的关系
网上的文章并没有错,nextTick 的初衷是为了获取更新后的 dom? 那问题就只剩下上一个了,dom 的更新和 ui 的渲染,肯定是分开的吧,不可能说 UI 渲染完了 dom 才更新了,肯定是更新后的 dom 被用于 UI 渲染了
我只要整一个函数更新 dom,然后看看实际的 dom 结构更新和渲染的先后关系
采用 alert 语句进行提示,alert 语句会 block 住 js 线程,将执行权让给 gui 渲染线程,执行 alert 之后浏览器会把这个语句之前的所有对 dom 的操作都进行体现。
感觉打断点的话也会被 js 线程也会被吊起,ui 渲染会直接进行,因此没办法捕捉到 dom 更新了,但是 UI 没渲染的那个瞬间
体验 dom 更新了,但是 UI 没有渲染的过程:https://blog.csdn.net/qdmoment/article/details/83657410
数据绑定
单向数据绑定
单向数据绑定,带来单向数据流
指的是我们先把模板写好,然后把模板和数据(数据可能来自后台)整合到一起形成 HTML 代码,然后把这段 HTML 代码插入到文档流里面。适用于整体项目,并于追溯。
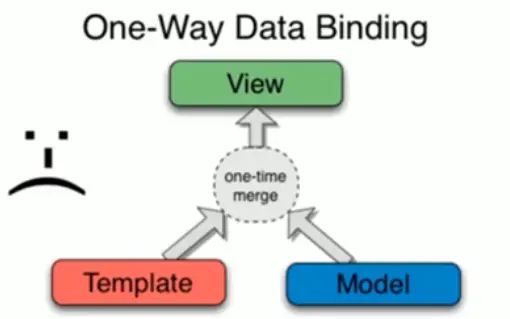
优点
- 所有状态的改变可记录、可跟踪,源头易追溯;
- 所有数据只有一份,组件数据只有唯一的入口和出口,使得程序更直观更容易理解,有利于应用的可维护性;
- 一旦数据变化,就去更新页面 (data- 页面),但是没有 (页面 -data);
- 如果用户在页面上做了变动,那么就手动收集起来 (双向是自动),合并到原有的数据中。
缺点
- HTML 代码渲染完成,无法改变,有新数据,就须把旧 HTML 代码去掉,整合新数据和模板重新渲染;
- 代码量上升,数据流转过程变长,出现很多类似的样板代码;
- 同时由于对应用状态独立管理的严格要求 (单一的全局 store),在处理局部状态较多的场景时 (如用户输入交互较多的“富表单型”应用),会显得啰嗦及繁琐。
双向数据绑定
双向数据绑定,带来双向数据流。AngularJS2 添加了单向数据绑定
数据模型(Module)和视图(View)之间的双向绑定。无论数据改变,或是用户操作,都能带来互相的变动,自动更新。适用于项目细节,如:UI 控件中 (通常是类表单操作)。
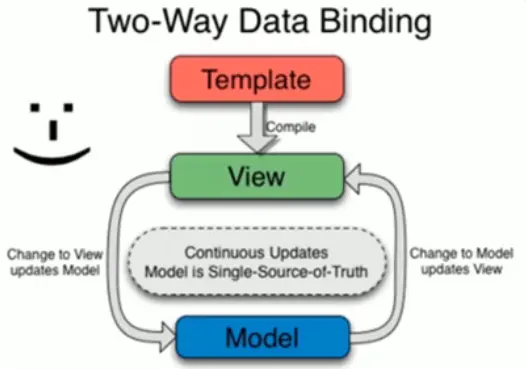
优点
- 用户在视图上的修改会自动同步到数据模型中去,数据模型中值的变化也会立刻同步到视图中去;
- 无需进行和单向数据绑定的那些 CRUD(Create,Retrieve,Update,Delete)操作;
- 在表单交互较多的场景下,会简化大量业务无关的代码。
缺点
- 无法追踪局部状态的变化;
- “暗箱操作”,增加了出错时 debug 的难度;
- 由于组件数据变化来源入口变得可能不止一个,数据流转方向易紊乱,若再缺乏“管制”手段,血崩。
在 angular 中,他没有办法判断你的数据是否做了更改, 所以它设置了一些条件,当你触发了这些条件之后,它就执行一个检测来遍历所有的数据,对比你更改了地方,然后执行变化。这个检查很不科学。而且效率不高,有很多多余的地方,所以官方称为脏检查
本质
双向绑定 = 单向绑定 + UI 事件监听。
请看下面的代码示例
<body>
<div id="app">
<input type="text" v-model="meg">
<p>{{data}}</p>
</div>
<script>
var app = new Vue({
el:'#app',
data :{
meg:''
}
})
</script>
</body>
当你在页面的 input 框中输入值时,下面一行同步显示内容,如果我们不要 v-model 指令能实现这个效果吗? 只需要改为:
//首先设置value属性为meg,然后监听输入事件
<input type="text" :value="meg" @input="meg=$event.target.value">
具体实例
目前几种主流的 mvc(vm) 框架都实现了单向数据绑定,而我所理解的双向数据绑定无非就是在单向绑定的基础上给可输入元素(input、textare 等)添加了 change(input) 事件,来动态修改 model 和 view,并没有多高深。所以无需太过介怀是实现的单向或双向绑定。
发布者 - 订阅者模式
一般通过 sub, pub 的方式实现数据和视图的绑定监听,更新数据方式通常做法是 vm.set('property', value),这里有篇文章讲的比较详细,有兴趣可点 这里
这种方式现在毕竟太 low 了,我们更希望通过 vm.property = value 这种方式更新数据,同时自动更新视图,于是有了下面两种方式
脏值检查
angular.js 是通过脏值检测的方式比对数据是否有变更,来决定是否更新视图,最简单的方式就是通过 setInterval() 定时轮询检测数据变动,当然 Google 不会这么 low,angular 只有在指定的事件触发时进入脏值检测,大致如下:
- DOM 事件,譬如用户输入文本,点击按钮等。( ng-click )
- XHR 响应事件 ( $http )
- 浏览器 Location 变更事件 ( $location )
- Timer 事件 ( $timeout , $interval )
- 执行 $digest() 或 $apply()
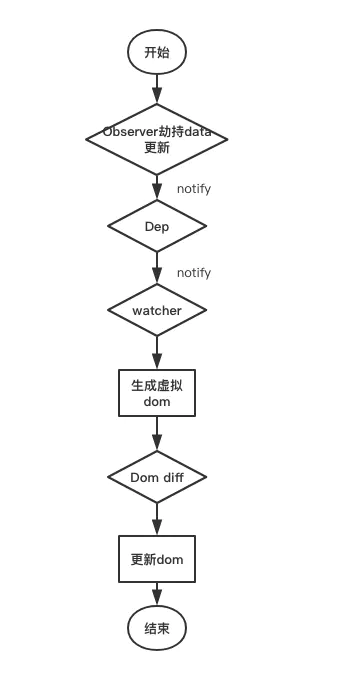
数据劫持
vue.js 则是采用数据劫持结合发布者 - 订阅者模式的方式,通过 Object.defineProperty() 来劫持各个属性的 setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。
vue3 通过 proxy 实现劫持
响应式机制
对比
与 React 对比
react 手动 setState 更新了 vm 之后,vm 的变动到 v 的更新 (vDOM) 实现了单向绑定
vue 中手动更新了 data 之后,vm 的变动到 v 的更新 (vDom) 实现了单向绑定
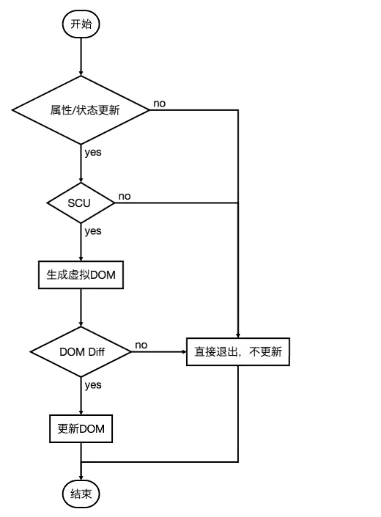
在 React 应用中,当某个组件的状态发生变化时,它会以该组件为根,重新渲染整个组件子树。当然,这可以通过 shouldComponentUpdate 这个生命周期方法来进行控制 purerender,但 Vue 将此视为默认的优化。
vue 中实现数据绑定靠的是数据劫持(Object.defineProperty())+ 观察者模式。在 Vue 应用中,组件的依赖是在渲染过程中自动追踪的,所以系统能精确知晓哪个组件需要被重渲染。你可以理解为每一个组件都已经自动获得了 shouldComponentUpdate,并且没有上述的子树问题限制。Vue对比其他框架
实现双向绑定 Proxy 与 Object.defineProperty 相比优劣如何?
-
Object.definedProperty 的作用是劫持一个对象的属性,劫持属性的 getter 和 setter 方法,在对象的属性发生变化时进行特定的操作。而 Proxy 劫持的是整个对象。
let obj = {name: 'Yvette', hobbits: ['travel', 'reading'], info: { age: 20, job: 'engineer' }}; let p = new Proxy(obj, { get(target, key) { //第三个参数是 proxy, 一般不使用 console.log('读取成功'); return Reflect.get(target, key); }, set(target, key, value) { if(key === 'length') return true; //如果是数组长度的变化,返回。 console.log('设置成功'); return Reflect.set([target, key, value]); } }); p.name = 20; //设置成功 p.age = 20; //设置成功; 不需要事先定义此属性 p.hobbits.push('photography'); //读取成功;注意不会触发设置成功 p.info.age = 18; //读取成功;不会触发设置成功 -
Proxy 会返回一个代理对象,我们只需要操作新对象即可,而
Object.defineProperty只能遍历对象属性直接修改。 -
Object.definedProperty 不支持数组,更准确的说是不支持数组的各种 API,因为如果仅仅考虑 arry[i] = value 这种情况,是可以劫持的,但是这种劫持意义不大。而 Proxy 可以支持数组的各种 API。
Object.definedProperty 可以将数组的索引作为属性进行劫持,但是仅支持直接对 arry[i] 进行操作,不支持数组的 API,非常鸡肋。
Proxy 可以监听到数组的变化,支持各种 API。注意数组的变化触发 get 和 set 可能不止一次,如有需要,自行根据 key 值决定是否要进行处理。
let hobbits = ['travel', 'reading']; let p = new Proxy(hobbits, { get(target, key) { // if(key === 'length') return true; //如果是数组长度的变化,返回。 console.log('读取成功'); return Reflect.get(target, key); }, set(target, key, value) { // if(key === 'length') return true; //如果是数组长度的变化,返回。 console.log('设置成功'); return Reflect.set([target, key, value]); } }); p.splice(0,1) //触发get和set,可以被劫持 p.push('photography');//触发get和set p.slice(1); //触发get;因为 slice 是不会修改原数组的 -
尽管 Object.defineProperty 有诸多缺陷,但是其兼容性要好于 Proxy.
Virtual DOM
SolidJS源码解读 - 用函数闭包实现高性能发布订阅模式 - 掘金
什么是 Virtual DOM
首先对我们将要插入到文档中的 DOM 树结构进行分析,使用 js 对象将其表示出来,比如一个元素对象,包含 TagName、props 和 Children 这些属性。然后我们将这个 js 对象树给保存下来,最后再将 DOM 片段插入到文档中。
当页面的状态发生改变,我们需要对页面的 DOM 的结构进行调整的时候,我们首先根据变更的状态,重新构建起一棵对象树,然后将这棵新的对象树和旧的对象树进行比较,记录下两棵树的的差异。
最后将记录的有差异的地方应用到真正的 DOM 树中去,这样视图就更新了。
我认为 Virtual DOM 这种方法对于我们需要有大量的 DOM 操作的时候,能够很好的提高我们的操作效率,通过在操作前确定需要做的最小修改,尽可能的减少 DOM 操作带来的回流和重绘的影响。其实 Virtual DOM 并不一定比我们真实的操作 DOM 要快,这种方法的目的是为了提高我们开发时的可维护性,在任意的情况下,都能保证一个尽量小的性能消耗去进行操作
还有一个原因就是 vDOM 可以作为节点的抽象, 渲染到不同的平台上, 比如 SSR 和混合开发
详细资料可以参考: 《Virtual DOM》 《理解 Virtual DOM》 《深度剖析:如何实现一个 Virtual DOM 算法》 《网上都说操作真实 DOM 慢,但测试结果却比 React 更快,为什么?》
如何比较两个 DOM 树的差异
两个树的完全 diff 算法的时间复杂度为 O(n^3) ,但是在前端中,我们很少会跨层级的移动元素,所以我们只需要比较同一层级的元素进行比较,这样就可以将算法的时间复杂度降低为 O(n)。
算法首先会对新旧两棵树进行一个深度优先的遍历,这样每个节点都会有一个序号。在深度遍历的时候,每遍历到一个节点,我们就将这个节点和新的树中的节点进行比较,如果有差异,则将这个差异记录到一个对象中。
在对列表元素进行对比的时候,由于 TagName 是重复的,所以我们不能使用这个来对比。我们需要给每一个子节点加上一个 key,列表对比的时候使用 key 来进行比较,这样我们才能够复用老的 DOM 树上的节点。
为了解决这个问题,React 提供 pureComponent, shouldComponentUpdate, useMemo, useCallback 让开发者来操心哪些 subtree 是需要重新渲染的,哪些是不需要重新渲染的。究其本质,是因为 React 采用的 JSX 语法过于灵活,难以理解开发者写出代码所代表的意义,没有办法做出优化。
为什么 React 和 Vue 需要 Virtual DOM
React 对数据的处理是不可变(immutable):具体表现是整树更新,更新时,不关注是具体哪个状态变化了,只要有状态改变,直接整树 Diff 找出差异进行对应更新。
Vue 对数据的处理是响应式、可变的(mutable):更新时,能够精确知道是哪些状态发生了改变,能够实现精确到组件级的更新。
比如说,下面的例子中,React 为了更新 message 对应的 DOM 节点,需要做 n 多次遍历,才能找到具体要更新哪些节点。

为了解决这个问题,React 提供 pureComponent, shouldComponentUpdate, useMemo, useCallback 让开发者来操心哪些 subtree 是需要重新渲染的,哪些是不需要重新渲染的。究其本质,是因为 React 采用的 JSX 语法过于灵活,难以理解开发者写出代码所代表的意义,没有办法做出优化。
而 Vue2 虽然实现了精确到组件级别的响应式更新,但对于组件内部的 DOM 节点还是需要进行 n 多次遍历的 Diff 运算。直到 Vue3 中借鉴 Svelte 的思路使用静态提升对渲染函数做 AOT (ahead-of-time,可以理解为预编译) 优化后,才使得性能进一步提升。
更新粒度对比
- 应用级:有状态改变,就更新整个应用,生成新的虚拟 DOM 树,与旧树进行
Diff(代表作:React,当然了,现在它的虚拟 DOM 已升级为了Fiber)。 - 组件级:与上方类似,只不过粒度小了一个等级(代表作:Vue2 及之后的版本)。
- 节点级:状态更新直接与具体的更新节点的操作绑定(代表作 vue1.x 、Svelte、SolidJS)。
Vue1.x 时代,对于数据是每个生成一个对应的 Wather,更新颗粒度为节点级别,但这样创建大量的 Wather 会造成极大的性能开销,因此在 Vue2.x 时代,通过引入虚拟 DOM 优化响应,改为了组件级颗粒度的更新。
而对于 React 来说,虚拟 DOM 就是至关重要的部分,甚至是核心,React 是属于应用级别的更新,因此整个 DOM 树的更新开销是极大的,所以这里对于 Virtual DOM Diff 的使用就是极其必要的。
是否采用虚拟 DOM
这个选择是与上边采用何种粒度的更新设计紧密相关的:
- 是:对应用级的这种更新粒度,虚拟 DOM 简直是必需品,因为在 Diff 前它并不能得到此次更新的具体节点信息,必须要通过 Virtual DOM Diff 筛选出最小差异,不然整树
append对性能是灾难(代表框架:React、vue)。 - 否:对节点级更新粒度的框架来说,没有必要采用虚拟 DOM(代表作:Svelte、SolidJS)
预编译 (AOT) 阶段的代码优化
JSX 阵营:React/SolidJs
Template 阵营:Vue/Svelte
JSX 优缺点
JSX 具有 JavaScript 的完整表现力,非常具有表现力,可以构建非常复杂的组件。
但是灵活的语法,也意味着引擎难以理解,无法预判开发者的用户意图,从而难以优化性能。你很可能会写出下面的代码:
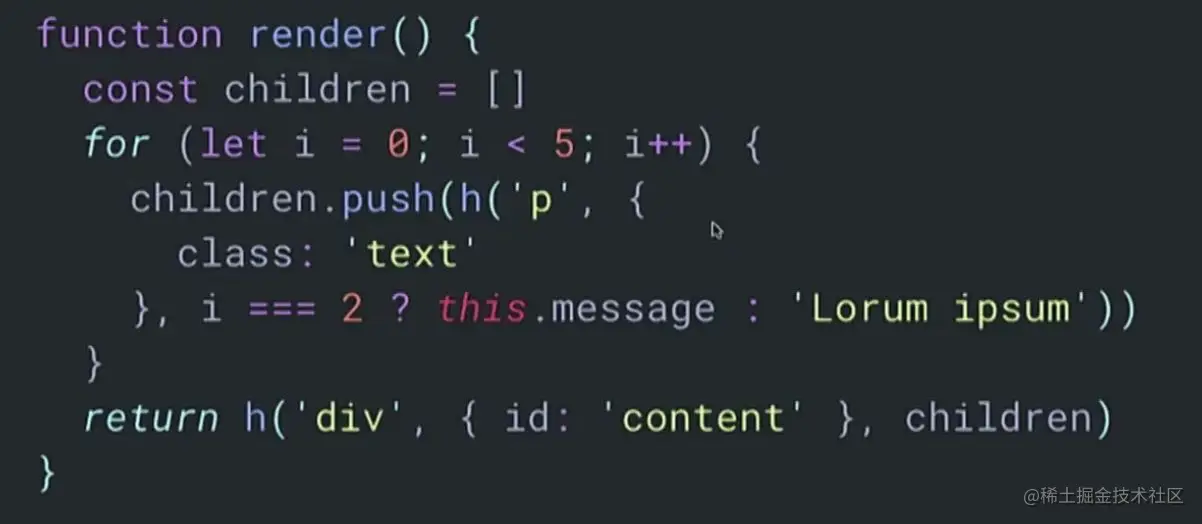
在使用 JavaScript 的时候,编译器不可能 hold 住所有可能发生的事情,因为 JavaScript 太过于动态化使得很难做意图分析。也有人对这块做了很多尝试,但从本质上来说很难提供安全的优化。
Template 优缺点
Template 模板是一种非常有约束的语言,你只能以某种方式去编写模板。
例如,当你写出这样的代码的时候,编译器可以立刻明白: ”哦!这些 p 标签的顺序是不会变的,这个 id 是不会变的,这些 class 也不会变的,唯一会变的就是这个“ 。
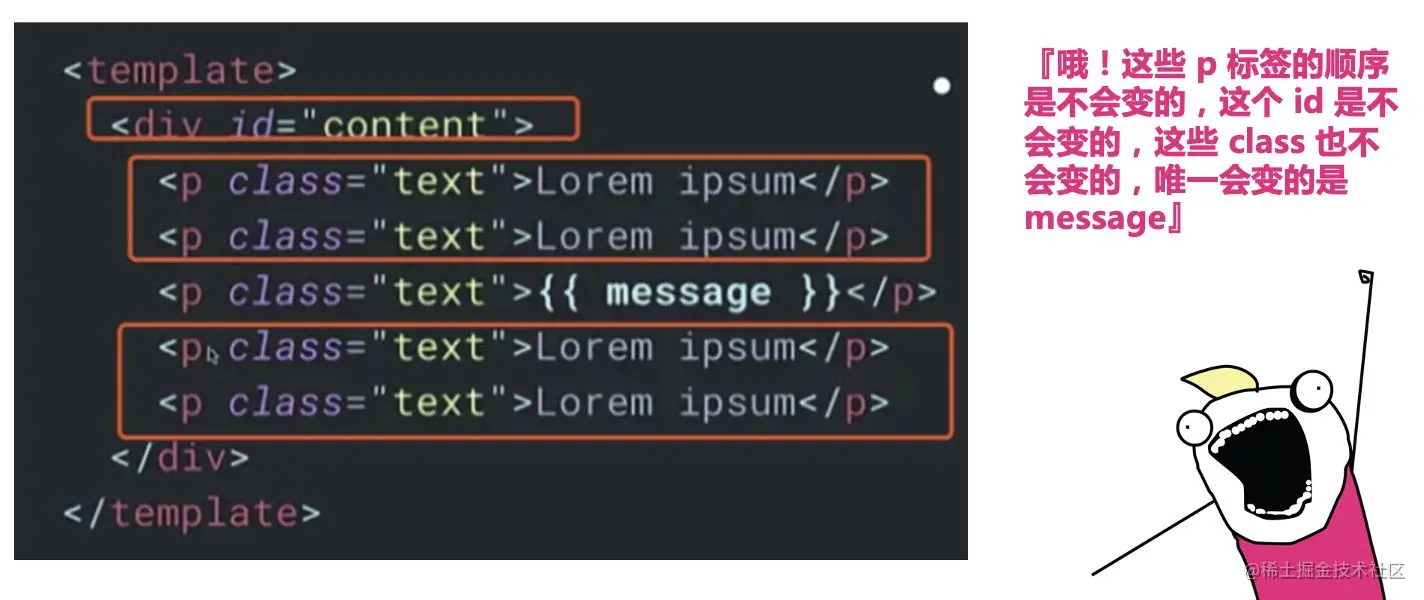
在编译时,编译器对你的意图可以做更多的预判,从而给它更多的空间去做执行优化。左侧 template 中,其他所有内容都是静态的,只有 name 可能会发生改变。
SolidJS 的优化
SolidJS 采用的方案是:在 JSX 的基础上做了一层规范,中文译名为 控制流,避免了编译器难以理解的代码。这样即借鉴了 template 更容易做编译阶段优化的优势,又保留了 JSX 的灵活性,以 For 为例
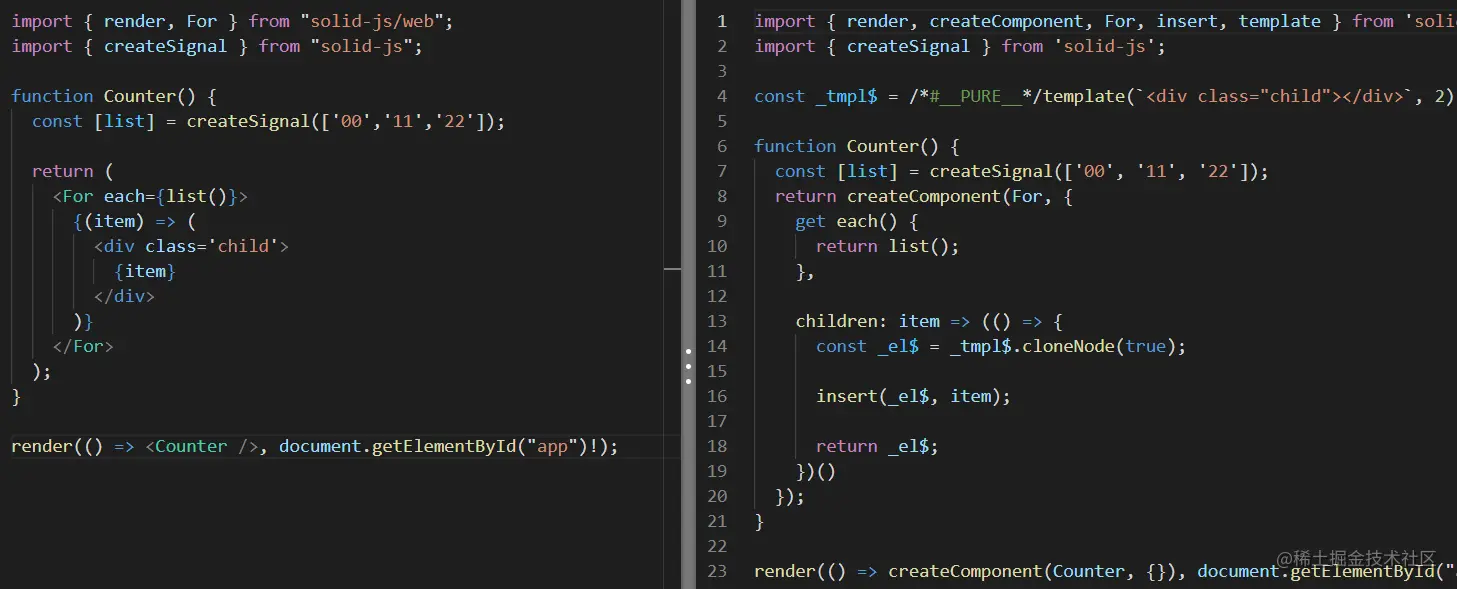
如果不使用推荐的控制流语句
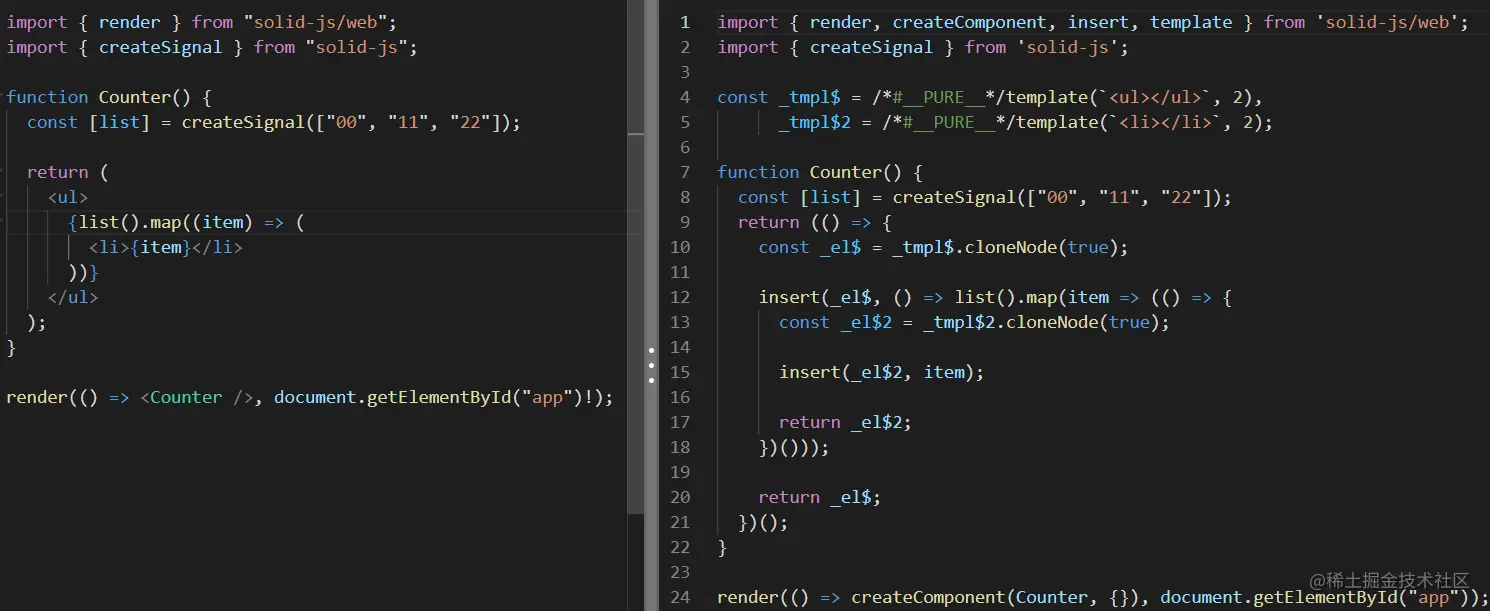
可以看到,不使用推荐的控制流语句时,SolidJS 将流大括号内的流程语句编译为了一整个变量,每次 list 改变时会导致整个列表重新渲染,性能低下
那么 For 内部做了什么呢,我们打开源码看看
export function For<T, U extends JSX.Element>(props: {
each: readonly T[] | undefined | null | false;
fallback?: JSX.Element;
children: (item: T, index: Accessor<number>) => U;
}) {
const fallback = "fallback" in props && { fallback: () => props.fallback };
return createMemo(
mapArray<T, U>(() => props.each, props.children, fallback ? fallback : undefined)
);
}
可以看到 For 的返回是 createMemo 包裹的 mapArray 方法,createMemo 类似 React 的 useMemo,mapArray 中做的事情就是会比较新老数组,仅更新变化的节点,并尽可能的从旧节点中复用,和 Diff 的思路很像。
Diff 算法
Diff 算法的核心思想是通过对比新旧虚拟 DOM 树的节点,识别出需要更新的部分,并将这些更新应用到实际 DOM 中。其规则包括:
- 当节点类型不同时,直接替换整个节点。
- 当节点类型相同时,比较节点的属性,更新变化的属性。
- 当节点为文本节点时,直接替换文本内容。
- 针对列表节点,React 会使用 "key" 属性来识别列表中的每个元素,以避免不必要的重新排序。
SSR
- 相比于 SSR,我们平时开发的基于 Vue 的单页应用叫 CSR。
- SSR 的优点:更好的 SEO、优化首屏加载。
- SSR 缺点:学习开发成本高,运维成本高,需要额外部署,踩坑较多。
- SSR 的方案:Vue 有 Nuxt 框架,React 有 Next 框架,当然也可以根据公司项目需求自研。
- SSR 的核心概念包括:同构、数据脱水注水、服务端请求、跨平台 API、服务端生命周期等等。因为篇幅限制,具体的细节和原理,之后我会出专栏讲解。
至于需不需要使用 SSR,具体项目要具体对待,如果是对 SEO 要求特别高,且交互并不复杂的内容站,可以考虑使用 SEO。
SSG
SSG 是 "Static Site Generation"(静态网站生成)的缩写。它表示网页被预先渲染成静态的 HTML,然后直接提供给客户端,而不需要服务器实时生成 HTML。
在传统的 SSR 中,每当用户请求一个页面时,服务器就会实时生成 HTML。有了 SSG,HTML 可以在构建过程中被提前生成,并被托管在 CDN 或其他静态资源服务中。
与传统的 SSR 相比,SSG 可以提供更快的加载速度以及更少的服务端开销,因为不需要维护一个服务器来实时生成 HTML。然而,SSG 不适合需要动态内容的网站,因为 HTML 是在构建过程中生成的,不支持实时更新。
A 架构组织 和 B 视图方案 的关系
作者:beeplin
链接:https://www.zhihu.com/question/468249924/answer/1968728853
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
题主觉得“从代码组织上看,最起码 HOC 可以降低对 React 组件的入侵程度,而 Hooks 要求写在组件或自定义 Hooks 内部”,所以觉得在架构层面 class 组件比 hooks 好。之所以很在意这个问题,很有可能是因为架构里面“业务逻辑”和“UI”分离得还不够,依然还有大量的具体业务逻辑需要写在 class 组件里或者 hook 函数里。
比较好的做法是从 react 组件中彻底分离出业务逻辑。业务逻辑的代码是 UI 无关的, 它就是一组纯粹简单的 class 或者函数, 除了 lodash 之类的工具包(相当于扩展语言能力)之外,几乎不 import 任何其他东西。这就是所谓的数据模型,model。它仅描述核心的业务规则,和你用 react 还是 vue 还是 ng 都没有任何关系,可以对接各种框架,甚至还可以跑在后端 node 里
这时候 react 或 vue 部分就剩下薄薄的一层,最多只需要负责三件事:
- 把 model 实例化并和 dom 联动: 通过 new 或者工厂,构造出 model 数据,把这些数据响应式地映射到 dom;根据 dom 事件,调用 model 里的函数或方法,来更新 model 数据。
- (可选)集中维护 model 数据的缓存:以前大家用 redux 或 mobx,大部分代码量都是在处理这个问题。现在有了 react-query 或 swr 这样的东西,这个工作已经大大简化了。
- 处理纯页面状态: dom 上有些状态不是从 model 数据里来的,是纯粹的页面状态,比如主题颜色啊、数据正在加载的标志啊,抽屉或手风琴的展开折叠啊,等等。这些和 model 无关,可能从桌面浏览器变到 手机浏览器,或者变到 electron 本地程序
一个常见的误区是在 react、vue 组件或 redux、mobx 里直接调用 fetch、axios 来存取数据,然后再把数据喂给 model。这不是一个理想的架构。UI 和数据持久化是两个独立的东西,最好是在 UI 里调用 model 提供的存取函数,然后在 model 的存取函数里调用 fetch、axios:
[ui 事件处理函数] -- 调用 --> [user.save 方法] -- 调用 --> [fetch 函数]
这样,我们在前端的部分就做到了 model、UI 和持久化这三个东西的分离。这就是所谓六边形架构、洋葱架构、整洁架构的核心套路,无论是前端还是后端开发中,思想都是一样的。(详见 clean architecture 一书,强烈推荐)
回到 A 和 B 关系的问题。在这个架构下,你用 vue 的 optional api, composition api,或者 react class 组件,react hooks 函数,有啥特别大的区别呢?其实没有。都是一层薄薄的壳子而已,主要就根据第三方组件库的丰富适用程度、团队的能力经验偏好等因素来选择了。理论上来说,vue composable 和 react hooks 的可组合能力是有一定优势的。
B 视图方案 和 C 响应原理 的关系
题主提到“不觉得 Hooks 像 Mobx,而 Mobx 没有 Hooks 这些使用限制”,这是关公战秦琼了。
hooks 是视图方案层面的东西,是改进 class 组件的,它们背后用的都是 react 原生的响应方案,也就是监测变量引用(reference)的变化,然后整个子树去协调更新。
而 mobx 呢,大家喜欢把它和 redux、vuex 做对比,看作是一个集中管理状态的工具。但其实这个看法不准确,矮化了 mobx。mobx 也可以用于管理组件的局部状态,它本质是一个替代性的响应方案,类似 vue 基于 proxy 的响应系统,并且提供了一些更丰富的微调选项。
视图和响应,是两个相互独立的维度。mobx 作为一个响应方案,既可以和 class 组件一起用,也可以和 hooks 函数组件一起用,甚至还可以跟 ng 或 vue 一起用。**事实上 mobx 本身就提供了一个用来代替 useState 的 hook:MobX API Reference · MobX
react、vue、ng 这些框架的功能其实可以分为两个部分,一个是 UI 视图的部分,负责对接 dom,另一个是响应系统的部分,负责实现数据联动。这两部分理论上不是耦合的,是可以相互组合的。
如果非要比较的话,视图的部分,其实各框架也没啥本质区别,模板和 jsx 的区别也很小,都好用,jsx 的类型支持可能目前更好些。至于数据响应联动的部分,个人认为还是 vue、mobx 这种基于 proxy 的用起来简单,比起 react 原生方案来,具有本质性的优势。
为什么这么说呢?当然一方面是因为 react 原生的方案乍看简单直接,稍微用起来就会发现各种无效协调、无效更新爆表,要控制好性能的话,无论 class 组件还是 hooks 方案都需要注意很多事情,心智负担比较重。但更重要的原因是,vue、mobx 的响应方案,对接主流 model 风格比较方便。下面详细解释
C 响应原理 和 D 模型风格 的关系 (这是重点!!!)
上文谈到,健康的架构,最好把业务逻辑写在完全独立于 UI 视图的 model 模型里,然后由前端框架来响应式地连接 UI 和 model。这就需要一个响应方案,把原来 vanilla js/ts 写成的 model 变成响应化的 model。响应原理的不同,就造成两大模型风格 OOP 和 FP 的分野
vue 和 mobx 这类基于 proxy 的响应方案,核心依赖的就是“容器对象引用不变,内部属性状态发生改变”,而面向对象的 class 实例的本质,就是一个引用不变的对象,里面有一些可变的状态,还有一些用来改变这些状态的动作。完美配合
但如果配合 react 原生响应系统,用 class 来写 model 就比较麻烦。react 原生响应方案最怕的就是“容器引用不变、内部变”这种东西,它反而要求“内部不要变,容器整体引用要变”,也就是你每一个动作都必须生成一个新的实例,这样它才能检测到状态的变化。刚好和对象的特性是反的。这就天然切合声明式编程、FP 的特质
甲风格:class + 可变数据
举个例子。假如我们要写一个 user 模型,支持 hash 密码。先看第一种风格,最常见的 class 写法:
// 甲风格:class + 可变数据:
class User {
public hashedPassword // 属性可变
public constructor(
public name: string,
password: string,
private readonly crypt: Crypt, // 通过Crypt接口注入一个加密用的工具,这就是上文提到的依赖反转
) {
this.changePassword(password)
}
public changePassword(password) {
// 方法里直接修改属性
this.hashedPassword = this.crypt.hash(password)
}
}
如果你用 vue 来对接这个 user model,那就很简单,你 new 出一个 user 实例来,然后用 reactive 套一下,就直接可以在组件里用了:
import { reactive } from 'vue'
setup() {
// 用reactive包装user实例
const user = reactive(new User('name', 'password', new Crypt()) as User
return () => (
// click时user本身的引用没变,只是内部状态发生了变化,vue可以检测到变化并更新界面
<button onClick={() => user.changePassword('new password')}>
{user.hashedPassword}
</button>
)
}
mobx 配合 react 呢,也很简单,和上面 vue 类似,大部分时候用 makeAutoObservable 替换 vue 的 reactive 就可以了。有些情况下 makeObservable 不能用,比如 model 是个有基类的子类等等,那就用 makeObservable 手动逐字段处理一下,这时候还可以对不同的字段做不同的响应式细节的区分:
const user = new User('name', 'password', new Crypt())
makeObservable(user, {
name: observable,
hashedPassword: observable,
changePassword: action,
another_attr: observable.shallow, // 指定更细致的响应层次
yet_another_attr: computed,
})
乙风格:函数 + 不可变数据
但是非要用 react 原生方案的话,写 model 的时候,可以不写成 class,而写成一组独立的无行为的数据类型,加上用来操作这些数据类型的一组独立函数。所有函数都需要是纯的,类似于 redux reducer 的概念,接受一个旧 state 对象,返回一个全新的 state 对象:
// 乙风格:函数 + 不可变数据:
// 不可变的数据类型
type User = Readonly<{ name: string; hashedPassword: string }>
function createUser(name: string, password: string, crypt: Ctrypt): User {
return { name: name, hashedPassword: crypt.hash(password) }
}
// 返回一个新的User对象
function changeUserPassword(user: User, pasword: string, crypt: Crypt): User {
return { ...user, hashedPassword: crypt.hash(password) }
}
const crypt = new Crypt()
let user = createUser('name', 'password', crypt)
// 重新给user赋值,react才能检测到变化
user = changeUserPassword(user, 'new password', crypt)
对大部分业务来说,这种写法的确不太自然,很多参数需要传来传去,最好有类型系统配合,否则写起来很痛苦,而且要实现私有属性访问控制和继承的时候比较麻烦。
丙风格:class + 不可变数据
当然你也可以在形式上写成 class,但是要注意 class 的所有属性都应该是 deep readonly 的,所有方法都不能修改属性,而是返回一个 new 出来的新实例:
// 丙风格:class + 不可变数据:
class User {
readonly public hashedPassword // 和甲风格对比:注意属性都是readonly的
public constructor(
readonly public name: string, // 和甲风格对比:注意属性都是readonly的
password: string,
private readonly crypt: Crypt,
) {
this.hashedPassword = crypt.hash(password)
}
// 和甲风格对比:返回一个新 User 实例,而不是就地修改属性
public changePassword(password): User {
return new User(this.name, password, this.crypt)
}
}
let user = new User('name', 'password', new Crypt())
// 重新给user赋值,react才能检测到变化
user = user.changePassword('new password')
这样比上面那个函数的写法好像强点儿,但是那个 changePassword 方法的写法还是很不自然,使用起来也很不方便。如果你写的时候在哪里忘记了规矩,那 react 就失去响应了。
这还不算最严重的,最大的问题是,你费这么大劲构造了一组另类的不可变 model,结果它只适合配合 react、react-native 的响应系统使用,也就是说它的风格侵入性比较强,万一以后要切换到 mobx 上、vue 上,很多地方必须修改。
丁风格:函数 + 可变数据:
而反过来呢,如果你写了一组可变风格的 model,如果想要用于 react 响应系统,那么可以用 immer 给它所有的方法包装一下,把可变方法变成不可变方法。immer 官方提供了这个 hook 可以做到这一点:immerjs/use-immer: Use immer to drive state with a React hooks (github.com)
(巧的是,mobx 和 immer 这两个 proxy 库,是同一个人写的。。此人叫做 Michel Weststrate)
所以,为了支持 immer,折衷一下,你还可以把你的 model 写成独立函数 + 可变数据对象的形式:
// 丁风格:函数 + 可变数据:
type User = { name: string; hashedPassword: string } // 和乙风格对比:可变的User类型
function createUser(name: string, password: string, crypt: Ctrypt): User {
return { name: name, hashedPassword: crypt.hash(password) }
}
// 和乙风格对比:非纯函数,直接修改了user参数的状态
function changeUserPassword(user: User, pasword: string, crypt: Crypt): void {
user.hashedPassword = crypt.hash(password)
}
const user = createUser('name', 'password', crypt)
// 直接调用的话,会修改user内部属性
changeUserPassword(user, 'new password', crypt)
// 通过immer调用的话,会创建一个新user实例,然后把修改逻辑应用到新user上
import produce from 'immer'
const user1 = produce(user, (draft) => changeUserPassword(draft, 'new password', crypt) )
这个模型风格,和最上面的甲风格对比,都是可变数据,只是把 class 语法变成了函数语法。class 是用方法操作内部数据,而这里是用独立函数操作外部数据。在这个例子上,其实两种做法是差不多的。很大程度上,user.changePassord(pw),就是 saveUserPassword(user, pw) 的语法糖,就是把第一个参数写到最前面了而已。
当然,class 语法不仅仅是语法糖。class 还可以提供方便的公私访问控制,而函数可以用闭包实现初步的访问控制,但语法没那么直观。class 还可以通过继承提供方便的方法多态功能,这一点函数做起来也比较麻烦。
四种风格的对比
那么我们现在就有四种模型风格,列个表看一下:
| 数据可变 | 数据不可变 | |
|---|---|---|
| class | 甲风格 典型 OOP,适合对接 vue、mobx;通过 immer 对接 react 不成熟 |
丙风格 非典型 FP,class 外表下所有方法都是纯函数,适合对接 react,包括 class 和 hooks |
| 函数 | 丁风格 非典型 OOP,相当于把 class 的方法外置了,适合对接 vue、mobx 也可以通过 immer 对接 react |
乙风格 典型 FP,适合对接 react,包括 class 和 hooks |
仔细品味一下上面的表格,可以发现,如果你在考虑响应方案的对接问题,那么很大程度上,表格两行之间对比,语法上是 class 还是函数,不太重要(class 只是多了方便的访问控制和继承,和响应方案没有直接关系)。表格两列之间对比,数据可变与否才是最关键的区别
所以这里题主讲的也有点偏差。他说团队有人“对访问限定,封装、隔离、多态这些东西不了解,习惯了函数是 JavaScript 中的一等公民”,因此倾向于选择 react hooks,反对 react class 组件。但实际上我们可以看到,react class 组件是“面向对象”的吗?根本不是!一个不允许你修改 this.state 属性、只能通过 this.setState() 间接修改属性的 class,本质上,类似上述的“丙风格”,是一种非典型的 FP
react 原生的响应式方案是非常依赖数据不可变性的。自从 react 最开始采用这种响应式方案的那一天起,它根子上就是对 FP 模型友好的,哪怕把组件包装成 class,也不能使它更接近 OOP
而题主之所以误认为 react class 组件是 OOP,很可能是因为他用了 mobx 代替 react 原生响应系统。这时候 react 就只剩下一个 UI dom 对接的功能了,FP 的核就被抽掉了,变成了表格中的甲方案,这就是典型的 OOP。可实际上这个 OOP 不是因为用了 class 组件,而是因为用了 mobx。如果题主不用 mobx,而是 redux,那么哪怕你完全不用 hooks,都用 class 组件,你的 redux 里面也全是 FP 纯函数
还要澄清一点,我们讨论 react class 组件是 FP 还是 OOP,其实不是讨论 class 组件 API 本身的风格,而是讨论“它作为 UI 库,更容易和 FP/OOP 哪种风格的 model 模型相对接”。如果讨论组件 API 本身的风格,意义不是很大,参见这个回答:为什么Vue和React都抛弃了面向对象写法 ? - 知乎 (zhihu.com)
为什么 React 特别热爱函数式?
React 的核心理念之一就是,界面应当是数据的不同形式的简单投影。相同的输入应该产生相同的输出。而函数式组件的写法,使用闭包的特性,显然符合这一理念:每个闭包里保存在父函数的当前形参(props)和局部变量。而类组件里,由于,每次读取数据,要根据 this 指针去读取,那必然不会读取到属于自己当前状态的值。而是更新后的最新的值。
Hooks 数据更新
当您在函数组件中使用 useState 来创建状态变量时,如果您直接对该状态变量进行赋值而不是使用 setState 函数,即使其他状态通过 setState 更新了,该状态变量也不会自动更新。
例如:
const [count, setCount] = useState(0);
const [otherState, setOtherState] = useState('some value');
// 直接赋值,而不是使用 setCount
count = 10;
// 更新 otherState 会触发组件重新渲染
setOtherState('new value');
// 此时 count 仍然是 10,并不会自动更新
在上述代码中,count 的值被直接赋值为 10,即使 otherState 更新也不会自动更新 count。为了正确更新 count,您应该使用 setCount 函数:
setCount(10); // 此时 count 将会被正确更新
对不起对之前的回答造成了混淆,感谢您的指正。在 React 中,要更新状态,应该使用相应的 setState 函数,以确保状态变化被正确跟踪并触发组件重新渲染。
Class 数据更新
可以直接改 state , 然后通过一个空的 setState 来触发数据更新
定时器里的表现
D 模型风格 和 E 类型系统 的关系
很简单,没关系。
题主认为“Typescript 是针对 JavaScript 不能胜任大型应用而开发的一门语言,它带来了两个新特性:一是类型系统,二是面向对象”。这里面也有误解。TS 的核心价值是类型系统,而不是什么“面向对象”。JS 本身就是面向对象的。题主提到的“访问限定,封装、隔离、多态这些东西”,哪怕在 JS 没有 class 的年代,也都能做。
函数一等公民,也和面向对象不矛盾。在没有 class 的年代,js 的函数一等公民加上词法作用域,带来的闭包特性,也是一种经典的面向对象的手段,所谓“闭包是穷人的对象”嘛。访问限定、封装、隔离,都可以用闭包搞定。而多态这种特性。。。JS 这种 鸭子类型 的 动态语言 难道不是天然支持多态吗?多态搞起来比 TS 方便多了。
更何况现在 JS 有了 class 语法糖,有了私域,面向对象就更用不着 TS 了。即使我们不使用私域,就用类似 python 的下划线约定私有属性,也可以啊,也没有人说 python 不是面向对象的吧?
好的语言可以用于不同的模型风格,当业务模型适合 FP 时候就 FP,适合 OOP 的时候就 OOP。class 和函数都应该是一等公民。差的语言,虽然声称什么“一切皆对象”,其实 class 和 class 的方法都不是对象,都不是一等公民,写起来烦死。。。
这里可能需要补充界定一下术语。根据 CTM(concepts, techniques and models)书中的讲法,常见的单线程模型风格,有三种递进关系:
第一,最基础的是声明式编程,或者说函数式编程。这个风格最大的特点就“数据不可变”,变量和属性都只能赋值一次,不能重新赋值。如果一个 class 内部属性不可变、方法都是纯函数,那么它虽然看起来像是对象,但其实属于 FP。
第二,在声明式编程的基础上,加上可变状态,也就是允许变量和属性重新赋值,就变成了“基于对象的编程”,Object-based Programing。所谓“对象”,就是可变的数据的组合。比如丁风格里的那个 User,里面只有可变数据,没有方法,也属于对象。对象可以内置方法,来修改内部数据,也可以不内置方法,通过把自己作为参数传递给外部函数,来修改内部数据。是否具有内部方法,这不是“对象”概念的本质。(顺便说一句,DDD 里面大家争论的贫血对象、充血对象,其实就是在争论方法内置还是外置的问题,其实,实质区别不大。参见我这个回答 关于 贫血模型 与 函数式编程 的疑问? - 知乎 (zhihu.com))
第三,**在此基础上,再加上对象之间的继承关系,就从 OBP 变成了 OOP,“面向对象的编程”。**通过 class 父类子类来继承,或者通过 prototype 原型链来继承,各种不同的继承方案,都可以。但是继承是很容易误用的,组合优于继承,所以至少在前端开发中,实际上真正的 OOP 比较少,大部分是 OBP。
所以,根据以上面向对象的定义,TS 和 JS 都支持可变数据,都支持继承,所以都是面向对象,TS 并不比 JS 更“面向对象”。TS 的价值还是在于类型系统,这一个价值就足足足足够了。
BTW,现在有些框架和库真是把 TS 的类型系统玩得了不得了,非常值得期待。参见 下一代前端框架会去解决什么问题? - 知乎 (zhihu.com)
Minireact 和 Minivue
总结
- A 架构组织:一锅粥 vs. 业务逻辑和 UI 分离
- B 视图方案:react class 组件 vs. hooks 函数组件
- C 响应原理:react 原生 vs. mobx 代理
- D 模型风格:面向对象 OOP vs. 函数式 FP
- E 类型系统:javascript vs. typescript
A 和 B 没关系。架构上需要把 model 独立出去,剩下一个薄薄的 UI 层,UI 层本身区别不大。如果你感觉 class 组件和 hook 组件的业务逻辑侵入性不同,那很可能是 model 没有足够地抽离出去,ui 和逻辑没分开。
B 和 C 也没关系。这是两个独立正交的维度,不存在耦合,mobx 和 hooks 不是替代关系。
C 和 D 关系很大,vue/mobx 的响应原理天然适合对接 OOP 模型,react 响应原理天然适合对接 FP 模型。
D 和 E 也没关系。类型的动静强弱是独立问题,ts 和 js 一样都可以开发 oop 风格模型,当然也一样都可以开发偏向 fp 风格的模型。
总之,**这五个东西里面,只有 C 和 D 之间有强相关性,其他两两之间其实都没啥关系。对于前端开发,真正需要讨论的重大的技术方案决策,其实就是选择 proxy 响应式 +OOP 模型,还是选择 react 响应式 +FP 模型。**其他问题都不太需要讨论,要不就是已经有普遍优势的选项,要不就是根本无所谓。
最后再附赠一个讲测试的回答吧~~当你把 model 从 ui 框架里分离出去以后,测试 model 就简单了,这时候就可能用的上 tdd 了:Test Driven Development 一定要用单元测试来实现吗?单元测试是否会影响工作效率? - 知乎 (zhihu.com)
FAQ
组件通信方式
老生常谈的题了,背答案不是目的,好的回答是对于每种场景能举出自己在实际项目中的应用。
React 组件通信方式有哪些
- Props: 父组件可以通过 props 将数据传递给子组件。子组件可以通过 this.props 访问这些数据
- Callback: 父组件可以通过回调函数将函数传递给子组件。子组件可以在适当的时候调用这些回调函数,以便与父组件通信
- Context: 上下文是一种在组件树中共享数据的方法。通过 context,可以在组件树中传递数据,而不需要在每个级别显式地将 props 传递给所有组件
- Redux: 复杂应用全局状态管理可以使用 Redux、Mobx 等状态管理库,项目里一般使用 React Redux 或者 RTK 工具包
- Pub/Sub: 发布/订阅模式是一种通过事件来进行任意组件间通信的方法,和 Vue 里的事件总线原理一样
- Hooks 里也可以通过 useReducer 和 useContext 来实现全局组件通信
Vue 组件通信有哪些方式,适用场景分别是什么
- 父 -> 子:props
- 子 -> 父:自定义事件
- provie/inject:父级组件 -> 子孙组件
- Event Bus:适用于任意组件之间通信,利用
emit 通过事件传递数据,也常用于封装组件库时的组件通信 - 通过组件实例,比如通过 $children 获取子组件实例,然后就可以在父组件中调用子组件的方法
- Vuex:适用于复杂应用的全局状态管理
在哪个生命周期发送数据请求
React
useEffect
Vue
- created:发送请求时机通常越早越好,beforeCreate 最早,但是很多时候我们发送请求需要依赖 data 和 props 中的数据或者调用 methods 里的方法,而这些是在 created 实例创建之后才有的,所以一般发送请求会放在 created。
- mounted:除了 created 之外,mounted 也常用来发送请求,其实这两者区别通常不大。因为生命周期是同步的,而请求是异步的。不管在 created 还是 mounted 里发请求,都不会阻塞页面渲染,请求都是在下一次事件循环才完成的。
isShow 是否要放到全局 Store?
loading、succ、fail 三种状态, 取决于 action 的执行结果, 要把 ui 上升到全局的 store 上去
如何把业务逻辑和 UI 分离?
学习一下 angluar 是怎么用 service 做业务逻辑抽离的
好像把 fetch 和 业务数据的处理都放在 action 就已经是分离了. 更进一步就是把 action 的 处理抽到 model 层, action 也只是直接调用 model 层暴露的接口而已.
子问题: 优雅的处理 Fetch Loading Succ Fail
17 年的问题: 如何优雅地结合类 Redux 处理异步通信的中间状态? - 知乎
就比如上面那个问题, 业务逻辑是在 UI 组件里面发起请求的. 由 UI 组件触发历史加载的请求, 然后由无组件做加载, 这样就不用把 loading、succ、fail 上升到 store 了.
但是这样其实和直接在 UI 组件里请求是一样的, 得把历史数据共享出去. 关键是只要是通过 action fetch 的话就会出去了. 所以还是要把 fetch 留在组件内部, action 用来更新数据就可以了
那为什么会有异步 action 呢? 看了下网上的讨论, 很多 redux 时代的做法都是派发一类 action 的三种结果, 类似于:
// Action
const getData = (url, params) => {
return {
types: ['PENDING', 'SUCCESS', 'ERROR'],
url,
params
}
}
// 异步 action
import {
LOADING_TODOS,
LOAD_TODOS_SUCCESS,
LOAD_TODOS_ERROR,
} from '../constant'
export function fetchTodos() {
return dispatch => {
dispatch({ type: LOADING_TODOS })
return fetch('https://jsonplaceholder.typicode.com/todo')
.then(response => response.json())
.then(todos => {
dispatch({
type: LOAD_TODOS_SUCCESS,
todos,
})
})
.catch(error => {
dispatch({
type: LOAD_TODOS_ERROR,
error,
})
})
}
}
// Reducer
switch (action.type) {
case 'PENDING': {
return {
...StaticRange,
pending: true,
data: [],
hasError: false,
}
}
case 'SUCCESS': {
return {
...state,
pending: false,
data: action.payload,
hasError: false,
}
}
case 'ERROR': {
return {
...state,
pending: false,
data: [],
hasError: true,
}
}
}
领域状态和用户状态
可以参考 mobx 里面提到的概念
React Vs Vue
这是个开放题,不建议背答案,可以从生态、语法、性能、原理、开发体验等方面去试着比较一下。
-
vue 和 react:https://www.zhihu.com/question/301860721/answer/535585130
-
如何理解 React Fiber 架构https://www.zhihu.com/question/49496872/answer/2400650069
-
为什么 react 和 vue 都抛弃了 oop:https://www.zhihu.com/question/451424245
-
react 和 vue 的本质不同:数据是否可变
- vue 希望数据是可变的,做了 proxy 代理
- react 希望数据是不可变的,所以永远是纯函数返回一个新的实例,只能通过 setState 去更新数据
todo: vue2-mvvm
比较适合测试驱动实现, 每一步都写好对应的单元测试, 来逐步实现 feature, 弄一个云 vscode 来编写简易的代码仓库
有没有能代替 git 的版本管理工具呢? 能逐步体现代码的添加功能的, 管理起来要方便的点 , 方便对比每个版本的差异, 修改低版本不能整天 rebase
React 从诞生之日的设计哲学就是,当状态发生变化时,重新创建所有视图。
即使你只是修改了组件树最深处的一个小小的状态,React 仍然需要自顶重新创建整个 vdom 树并且 Diff
如今的前端应用越来越复杂,屏幕刷新率也都越来越高。对于一个复杂的前端项目来说,组件的数量和组件树的层级都非常深。重新创建整个树的开销也会变大,如果超过了 16.7ms(刷新率 120hz 的话就是 8.4ms)就会导致掉帧、用户交互响应延迟。引入 fiber 机制后使得 React 的渲染过程可以中断,让出主线程响应用户事件,或者允许插入更高优先级的更新。
而 Vue 有一套细粒度的响应式机制,框架的更新粒度是组件级别,除此之外还有 Block Tree 等分离静态/动态模板的优化手段,更新的效率是足够高的,也就没有必要引入 fiber 这样的机制
其实设计哲学的优劣并不重要, 重要的是我们去理解他的设计思想, 更好的使用他, 以及相应的生态. react 和 vue 究竟哪个更优秀, 时间自然会给出他的答案. 也许胜者会出现在他们两个之外也说不定呢? 就算是 jQuery 也要把他用好才行
https://www.zhihu.com/question/468249924/answer/1965942197
https://zhuanlan.zhihu.com/p/133819602
https://zhuanlan.zhihu.com/p/139548169
https://zhuanlan.zhihu.com/p/158734246
https://www.zhihu.com/question/301860721/answer/545031906
为什么 vue 需要组合 api 呢?composite api solve what kind of problem . hook solve what kind of problem it is that i need to care?
TODO: 完善, react vs vue, 逐步引导
React Api. 和 Vue Api
有了解过哪些类 React 框架,谈谈你对它们的看法
Preact:可以理解为简易版 React,但是和 React 有一样的 API,性能比 React 还好,甚至也实现了并发模式,对于想要阅读 React 源码又觉得难的同学,可以看一看 Preact 的源码。
Svelte:无虚拟 Dom,依靠编译器和纯响应式的轻量级框架,然而性能却非常好。
SolidJS:和 Svelte 类似,但是 SolidJS 的语法更接近于 React,Svelte 的语法接近 Vue。
总结一下:
- 这些类 React 或者类 Vue 框架,可能在某一方面或者某些方面表现很出色。
- 在开发成熟项目时,还是尽量选择 Vue 和 React,因为毕竟生态和解决方案更多。
- 时间允许的话推荐阅读这些框架的源码,它们的代码量相对少,容易阅读,能让你有一个更广的视野来看待前端框架的原理和设计思路。