san-advanced
方法论
https://gitissue.com/issues/5b44f7bb9906f66a9d9b23fe
https://zhuanlan.zhihu.com/p/36996225
San - 一个传统的 MVVM 组件框架
https://efe.baidu.com/blog/san-a-traditional-mvvm-component-framework/
的目标,提供 CDN、支持 AMD 和 Global Object、npm publish 也都是很简单的事情,更难抉择的是 “你们怎么解决兼容性问题”。
通过方法操作组件数据,解决兼容性
- 用最简单的形式,解决兼容性问题
- San 的开发体验不可能做的比 Vue 更好
- 数据操作的过程可控。实际上,从 3.1.0 开始,数据变更在内部是 Immutable 的
- change tracking 好做了。我们并不认为 v-dom 是万金油,并且 San 是面向 Web 设计的,我们并没期望它跨平台。所以少掉 v-dom 这一层是一件好事
但是,把数据封起来意味着获取数据成本也变高了,特别是想一次获取多个数据的时候。所以我们把获取数据的 get 方法实现为,无参的时候返回整个数据对象,如果你用 ESNext 开发可以方便的使用解构。但是,操作数据还是要通过 set 或 splice 等方法的。
10K
- 其实这也不是什么很有技术含量的事情,为此我们直接手写 ES5 代码而不是 ESNext + Babel,在很多人看来还是挺 low B 的。具体是不是 10k 也没什么意义,只是态度而已。我们希望 San 的使用者不会受到体积的困扰,我们也希望体积强迫症患者能有更多的选择。
San 为什么会这么快
https://efe.baidu.com/blog/san-perf/
引用 API
ExprType
表达式类型
var ExprType = {
STRING: 1,
NUMBER: 2,
BOOL: 3,
ACCESSOR: 4, // 表达式对象, create-accessor()
INTERP: 5, // 插值替换
CALL: 6, // 函数调用
TEXT: 7,
BINARY: 8, // 二元表达式,包括
UNARY: 9, // 一元表达式
TERTIARY: 10, // 三元表达式
OBJECT: 11,
ARRAY: 12,
NULL: 13
};
type 4 1
function readAccessor(){
// ...
var result = createAccessor([
{
type: 1,
value: firstSeg
}
]);
// ...
}
function createAccessor(paths) {
return {
type: 4,
paths: paths
};
}
NodeType
节点类型
var NodeType = {
TEXT: 1,
IF: 2,
FOR: 3,
ELEM: 4,
CMPT: 5, // component
SLOT: 6,
TPL: 7,
LOADER: 8
};
LifeCycle
节点生命周期信息
var LifeCycle = {
// ...start,compiled,inited,created,attached
leaving: {
is: lifeCycleOwnIs,
compiled: true,
inited: true,
created: true,
attached: true,
leaving: true
},
detached: {
is: lifeCycleOwnIs,
compiled: true,
inited: true,
created: true,
detached: true
},
disposed: {
is: lifeCycleOwnIs,
disposed: true
}
};
视图创建
考虑下面这个还算简单的组件:
const MyApp = san.defineComponent({
template: `
<div>
<h3>{{title}}</h3>
<ul>
<li s-for="item,i in list">{{item}} <a on-click="removeItem(i)">x</a></li>
</ul>
<h4>Operation</h4>
<div>
Name:
<input type="text" value="{=value=}">
<button on-click="addItem">add</button>
</div>
<div>
<button on-click="reset">reset</button>
</div>
</div>
`,
initData() {
return {
title: 'List',
list: []
};
},
addItem() {
this.data.push('list', this.data.get('value'));
this.data.set('value', '');
},
removeItem(index) {
this.data.removeAt('list', index);
},
reset() {
this.data.set('list', []);
}
});
在视图初次渲染完成后,San 会生成一棵这样子的树:
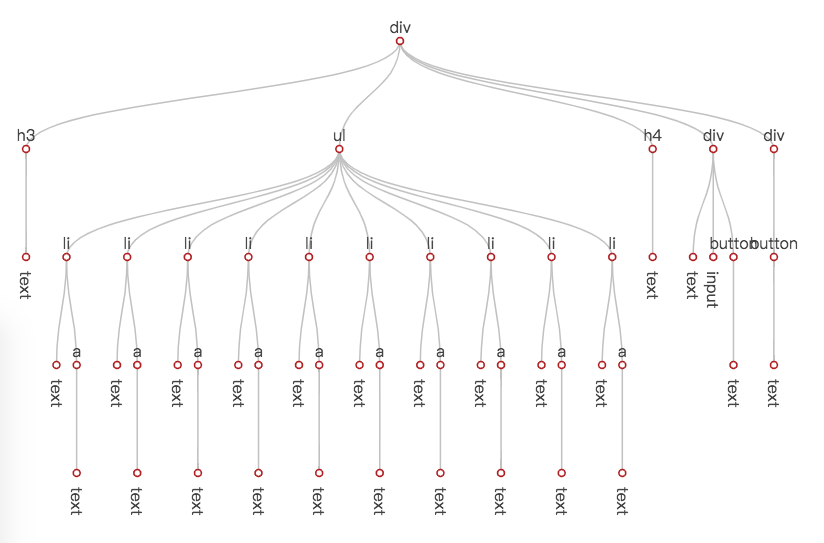
那么,在这个过程里,San 都做了哪些事情呢?
模板解析
概述
在组件第一个实例被创建时,template 属性会被解析成 ANode。
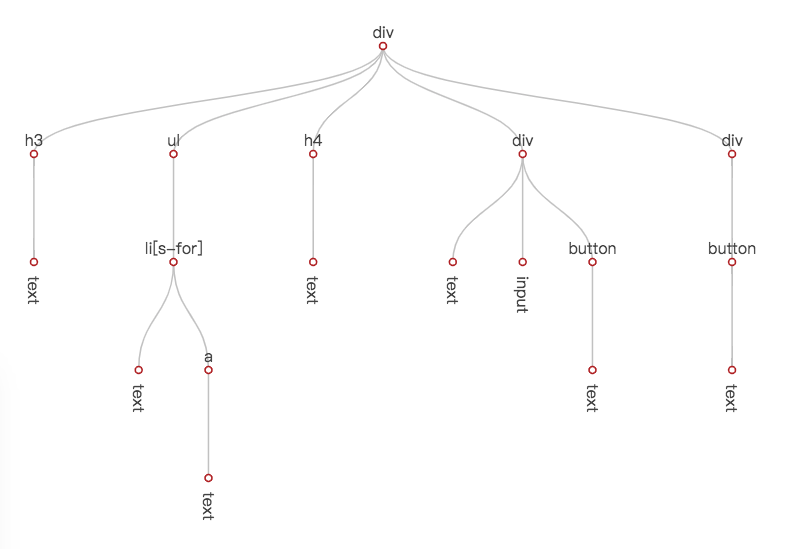
ANode 的含义是抽象节点树,包含了模板声明的所有信息,包括标签、文本、插值、数据绑定、条件、循环、事件等信息。对每个数据引用的声明,也会解析出具体的表达式对象。
// "tagName": "ul"
{
"directives": {},
"props": [],
"events": [],
"children": [
{
"directives": {
"for": {
"item": "item",
"value": {
"type": 4,
"paths": [
{
"type": 1,
"value": "list"
}
]
},
"index": "i",
"raw": "item,i in list"
}
},
"props": [],
"events": [],
"children": [
{
"textExpr": {
"type": 7,
"segs": [
{
"type": 5,
"expr": {
"type": 4,
"paths": [
{
"type": 1,
"value": "item"
}
]
},
"filters": [],
"raw": "item"
}
]
}
},
{
"directives": {},
"props": [],
"events": [
{
"name": "click",
"modifier": {},
"expr": {
"type": 6,
"name": {
"type": 4,
"paths": [
{
"type": 1,
"value": "removeItem"
}
]
},
"args": [
{
"type": 4,
"paths": [
{
"type": 1,
"value": "i"
}
]
}
],
"raw": "removeItem(i)"
}
}
],
"children": [
{
"textExpr": {
"type": 7,
"segs": [
{
"type": 1,
"literal": "x",
"value": "x"
}
],
"value": "x"
}
}
],
"tagName": "a"
}
],
"tagName": "li"
}
],
"tagName": "ul"
}
ANode 保存着视图声明的数据引用与事件绑定信息,在视图的初次渲染与后续的视图更新中,都扮演着不可或缺的作用。
无论一个组件被创建了多少个实例,template 的解析都只会进行一次。当然,预编译是可以做的。但因为 template 是用才解析,没有被使用的组件不会解析,所以就看实际使用中值不值,有没有必要了。
Pending
模板解析的主要代码位于:src/parser/parse-template
深度优先,通过 while 循环实现
svgTags
数据环境是如何约束的?如何做到约束 item 和 i
li> {{item}} \<a on-click="removeItem(i)">x\</a>
API
匹配标签的正则
// 用于匹配html标签,包括开标签和闭标签,标签允许用-连接,允许接空格
// 第一个捕获组是 /
// 第二个捕获组是 标签名,标签必须以字母开头,忽略大小写
var tagReg = /<(\/)?([a-z][a-z0-9-]*)\s*/ig;
\s* 会匹配标签名之后 到 > 或者 attr 之间的空格
通过捕获组判断是否是闭标签
通过捕获组获取标签名
匹配属性的正则
// 用于匹配属性的正则
// 第一个捕获组 =之前的内容
// 第二个捕获组 =及之后的内容,反向引用了第三个捕获组,进行引号匹配
// 第三个捕获组 引号
// 第四个捕获组 =之后的内容,反向引用了第三个捕获组,提高匹配效率
var attrReg = /([-:0-9a-z\[\]_]+)(\s*=\s*(['"])([^\3]*?)\3)?\s*/ig;
walker 类
包含一系列文本操作的方法,用 index 属性标记处理位置,逐个处理
根据 lastIndex 的定义,lastIndex 代表着下一次匹配开始的索引位置
因此有 nextCharCode = walker.currentCode()
pushTextNode(text)
pushTextNode(source.slice(beforeLastIndex, tagMatchStart));
因为每次 tagMatch 都只能匹配标签,因此 beforeLastIndex 和 tagMatchStart 可以截取相邻标签的纯文本。包括:
- 父开标签和子开标签之前的内容
li>{{item}}<a - 开标签和闭标签之前的内容
h3>{{title}}</h3
在读取栈中添加文本节点
if (text) {
currentNode.children.push({
textExpr: parseText(text, options.delimiters)
});
}
parseText()
动态构建正则,读取插值
默认正则:/\{\{\s*([\s\S]+?)\s*\}\}/g,匹配双花括号内的全部内容
parseInterp()
解析插值替换
循环解析 Template
根标签 div
从 walker.index:0 开始解析
tagMatch = walker.match(tagReg)
// tagMatch: <div (undefined) (div) index=0
// walker.index = reg.lastIndex = 4
是开标签
-
根据标签名判定不是自闭合标签
-
while 循环读取属性
nextCharCode为 62>,开标签结束,walker.go(1),break
-
pushTextNode('')
-
不是if/else 指令
- 不是table 标签
-
currentNode.children.push(aElement); // rootNode.children --- divNode
-
if (!tagClose) { currentNode = aElement; stack[++stackIndex] = aElement; }
beforeLastIndex = walker.index; // 5
div>h3
从 walker.index:5 开始解析
// tagMatch: <h3 (undefined) (h3) index=5
// walker.index = reg.lastIndex = 8
是开标签
- 不是自闭合标签
- while 循环读取属性,
walker.go(1),break - pushTextNode('')
- 不是if/else 指令
- 不是table 标签
-
currentNode.children.push(aElement); // divNode.children --- h3Node
- 同上
beforeLastIndex = walker.index; // 9
<h3>{{title}}</h3>
从 walker.index:9 开始解析
// tagMatch: </h3 (/) (h3) index=18
// walker.index = reg.lastIndex = 22
是闭标签
walker.currentCode===62,关闭标签,向上查找到对应标签,找不到时忽略关闭stack[stackIndex].tagName === tagName-
pushTextNode(source.slice(beforeLastIndex, tagMatchStart)); // pushTextNode(source.slice(9, 18)); // pushTextNode('{{text}}') // currentNode { "directives":{}, "props":[], "events":[], "children":[{ "textExpr":{ "type":7, "segs":[{ "type":5, "expr":{ "type":4, "paths":[{ "type":1, "value":"title" }] }, "filters":[], "raw":"title" }] } }], "tagName":"h3"} -
// 关闭标签 if (closeIndex > 0) { stackIndex = closeIndex - 1; currentNode = stack[stackIndex]; // currentNode === divNode } walker.go(1); // 23
ul>li
ul 从 walker.index:23 开始解析,解析过程与根标签类似,解析结束时 walker.index:27
li 从 walker.index:23 开始解析
是开标签
- 不是自闭合标签
- while 循环读取属性
-
var attrMatch = walker.match(attrReg);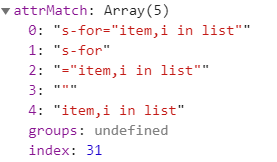
-
integrateAttr(aNode,"s-for'","item,i in list")parseDirective(aNode,"for","item,i in list")
-
nextCharCode为 62>,开标签结束,walker.go(1),break
-
- 剩余同 div
li> {{item}} <a on-click="removeItem(i)">x</a>
从 walker.index:54 开始解析
// tagMatch: <a (undefined) (a) index=63
// walker.index = reg.lastIndex = 66
是开标签
-
不是自闭合标签
-
while 循环读取属性
var attrMatch = walker.match(attrReg);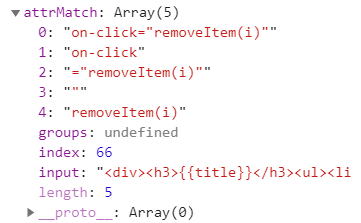
integrateAttr(aNode,"on-click'","removeItem(i)")
-
pushTextNode(source.slice(beforeLastIndex, tagMatchStart));pushTextNode(source.slice(54,63));pushTextNode('{{item}}'); -
同
{{title}}
Preheat
概述
在组件第一个实例被创建时,ANode 会进行一个 预热 操作。看起来, 预热 和 template 解析 都是发生在第一个实例创建时,那他们有什么区别呢?
- template 解析 生成的 ANode 是一个可以被 JSON stringify 的对象。
- 由于 1,所以 ANode 可以进行预编译。这种情况下,template 解析 过程会被省略。而 预热 是必然会发生的。
接下来,让我们看看预热到底生成了什么?
aNode.hotspot = {
data: {}, // recordHotspotData()
dynamicProps: [],
xProps: [],
props: {},
sourceNode: sourceNode,
// binds? binds仅在处理 aNode.props的时候有
};
上面这个来自 preheat-a-node.js 的简单代码节选不包含细节,但是可以看出, 预热 过程生成了一个 hotspot 对象,其包含这样的一些属性:
- data - 节点数据引用的摘要信息
- dynamicProps - 节点上的动态属性
- xProps - 节点上的双向绑定属性
- props - 节点的属性索引
- sourceNode - 用于节点生成的 HTMLElement
预热 的主要目的非常简单,就是把在模板信息中就能确定的事情提前,只做一遍,避免在 渲染/更新 过程中重复去做,从而节省时间。预热 过程更多的细节见 preheat-a-node.js。在接下来的部分,对 hotspot 发挥作用的地方也会进行详细说明。
this.source = typeof options.source === 'string'
? parseTemplate(options.source).children[0]
: options.source;
preheatANode(this.source);
Pending
深度优先,通过递归实现
究竟什么是可以确定的?为什么?
data - 节点数据引用的摘要信息 是在哪里生成/确定的呢?# data start #data end
根标签 div 在模板解析的过程中添加了 calss style id 三个属性,明明模板上是没有的,猜测是用于默认类名?
哪些是动态的?哪些不是?class style id 都成了动态属性了,是什么时候设置的呢?等子孙遍历完了就到 div 了
prop.expr.value == null
- 是双向绑定的属性
- 要 push 到
hotstop.xPropsaNode.hotspot.dynamicProps.push(prop);因为 value 为 null,说明是现在无法确定的,也就是动态的
静态属性是在哪里设置的呢?h3 之下的 title 属于插值,所以没有被提前设置,为什么呢?
else if (prop.expr.value != null) {
if (sourceNode) {
prop.handler(sourceNode, prop.expr.value, prop.name, aNode);
}
}
isDynamic 为什么没起作用 @@@
因为 accessorMeanDynamic 影响的是下一层的 isDynamic,暂时没有遇到这样的案例
API
Preheat
主要逻辑全在这个函数里面,只要 ANode!==null
analyseANodeHotspot()
遍历 aNode 所有的属性数组,调用**recordHotspotData()**进行记录
分析完自身的属性之后,会遍历子孙调用analyseANodeHotspot()
recordHotspotData()
被前者调用,调用analyseExprDataHotspot,生成数据引用摘要
生成的摘要是有规律的,取决于 expr.type 的顺序
为什么会把子元素的引用摘要也添加到父元素上呢?会和 s-for 的数据环境有关吗 item i
analyseExprDataHotspot
是一个递归函数,分析好数据会被记录
switch 不同的 expr.type,做不同的处理
主要作用是生成 data 摘要?同时判断是否是动态的
analyseExprs()
遍历表达式数组,递归调用analyseExprDataHotspot
返回值会并入 refs
同时判断是否是动态的,动态的肯定是不能提前确定的
预热
根标签 Div
在模板解析的过程中添加了 calss style id 三个属性,明明模板上是没有的
preheatANode(aNode)
analyseANodeHotspot(aNode);aNode.textExpr为undefined,- 根据
tagName创建sourceNode。 - 初始化
hotspot属性 - 分析
hotstop data,节点数据引用的摘要信息aNode.vars,undefinedaNode.props- 在
aNode.hotspot.binds记录prop.expr recordHotspotData(prop.expr),name为classanalyseExprDataHotspot(expr)expr.type为 7analyseExprs(expr.segments)- 遍历调用
analyseExprDataHotspot(expr[i])expr.type为 5analyseExprDataHotspot(expr.expr)expr.type为 4- 直接获取访问表达式的路径,
value为class analyseExprs(paths.slice(1),1),undefined,是动态的refs=['class']
- 处理过滤器
analyseExprs(filter.name.paths);- 遍历调用父函数,type 为 1,string,没有做任何处理
analyseExprs(filter.args:null);
- 返回
refs=['class']
- 返回
refs
- 遍历调用
- 返回
refs
data[ref] = 1;
recordHotspotData(prop.expr),name为style- expr.type 依次为 7 5 4,
refs=['style']
- expr.type 依次为 7 5 4,
recordHotspotData(prop.expr),name为id- expr.type 依次为 4 1 ,
refs=['id']
- expr.type 依次为 4 1 ,
- 在
aNode.directivesaNode.elsesaNode.children- 遍历 递归调用
analyseANodeHotspot
- 遍历 递归调用

div>h3
作为根标签 div 的第一个子元素,analyseANodeHotspot(h3Node);
aNode.textExpr为undefined,- 根据
tagName创建sourceNode,h3 - 初始化
hotspot属性 - 分析
hotstop data,节点数据引用的摘要信息aNode.vars,undefinedaNode.props,[]aNode.directives,[]aNode.elses,[]aNode.children,遍历 递归调用analyseANodeHotspot
<h3>{{title}}</h3>
作为 h3 的第一个子元素,analyseANodeHotspot(titleANode);
aNode.textExpr有值- 初始化
hotspot属性为空对象aNode.hotspot = {}; - 设置类型为 TextNode,
aNode.Clazz = TextNode; recordHotspotData(aNode.textExpr);expr.type为 7 5 4 ,refs=['title']- 遍历了
stack所有的data,因此包括父元素的 data,包括h3.hotstop.data和div.hotstop.data - 给父元素和自身添加了:
data[title] = 1;
ul>li
ul 的预热过程与 h3 类似,因为相关的属性都没有值
li 作为 ul 的第一个子元素在 ul 的预热阶段 expr.children 被传入 analyseANodeHotspot(liNode)
- 需要预热的仅有
directives recordHotspotData(aNode.directives['for'].value)expr.type依次是 4 1 ,返回refs=['list']- 栈内的节点
hotstop.data增加list字段,即divNode ulNode liNode
- 没有
trackBy标记 expr.children()
li> {{item}} <a>...</a>
{{item}}作为 li 的第一个子元素,在 li 的预热阶段 expr.children 被传入 analyseANodeHotspot()
- aNode.textExpr
- Expr.type 依次为 7 5 4 1, 返回
refs = [item]
a 标签作为 li 的第二个子元素,被传入 analyseANodeHotspot()
- aNode.events 有值,但是预热阶段不会处理
- aNode.children
<a on-click="removeItem(i)">x</a>
a 标签只有一个子元素,即纯文本 x,textExpr 有值,expr.type 依次为 7 1,refs=[]
Li
子孙遍历完成之后,继续处理 for 指令
if (aNode.directives['for']) { // eslint-disable-line dot-notation
aNode.forRinsed = {
children: aNode.children,
props: aNode.props,
events: aNode.events,
tagName: aNode.tagName,
vars: aNode.vars,
hotspot: aNode.hotspot,
directives: extend({}, aNode.directives)
};
aNode.hotspot.hasRootNode = true;
aNode.Clazz = ForNode;
aNode.forRinsed.directives['for'] = null; // @@@ eslint-disable-line dot-notation
aNode = aNode.forRinsed; // @@@ 同样意义不明,ClaZZ属性丢失了吗?没有 stack里面还保存着
}
<input type="text" value="{=value=}">
input 类型不会创建 sourceNode
需要预热的只有 props,其中一个是双向绑定
感觉 div 会有类似的处理,但是没什么没有注意到呢?因为需要子孙全部递归完之后,才会处理 div 的 props
- 分析
hotstop datainputNode.props- 在
inputNode.hotspot.binds记录prop.exprexpr.raw有值,引用原值
recordHotspotData(prop.expr),name为typeexpr.type为 1,返回refs=[]
recordHotspotData(prop.expr),name为valueexpr.type依次为 4 1,返回refs=['value']- stack 记录摘要
- 在
- 分析
hotstop props,name 为 typeaNode.hotspot.props[prop.name] = index;prop.handler = getPropHandler(aNode.tagName, prop.name);- 不是 svg 相关标签名
tagPropHandlers = elementPropHandlers[tagName];- 赋值了预设好的处理函数
propHandler = tagPropHandlers[attrName];- undefined,不是预设的几个属性之一
- 获取默认的属性处理函数
- 返回
propHandler
prop.expr.value != null- 没有 sourceNode
- 分析
hotstop props,name 为 value- 与 type 类似
prop.expr.value == null- 是双向绑定的属性
- 要 push 到
hotstop.xProps
- 要 push 到
aNode.hotspot.dynamicProps.push(prop);
- 是双向绑定的属性
预热阶段设置静态属性
each(aNode.props, function (prop, index) {
aNode.hotspot.props[prop.name] = index;
prop.handler = getPropHandler(aNode.tagName, prop.name);
// ......
if (prop.expr.value != null) {
if (sourceNode) {
prop.handler(sourceNode, prop.expr.value, prop.name, aNode);
}
}
else {
if (prop.x) {
aNode.hotspot.xProps.push(prop);
}
aNode.hotspot.dynamicProps.push(prop);
}
});
使用以下模板进行测试
template: `<div><a name='title'></a></div>`
需要预热的只有静态属性 name

在 div 的 expr.children 被传入 analyseANodeHotspot
- 分析
hotstop dataexpr.props- 在
atNode.hotspot.binds记录prop.exprexpr.raw有值title,引用原值
recordHotspotData(prop.expr)expr.type为 1 ,返回refs=[]
- 在
- 分析
hotstop props- 设置 index
- 获取属性的 handler
- a 标签没有预设的
tagHandler,设置为空对象 propHandler自然也为空,没有name属性的预设propHandler,因此获取默认 handler
- a 标签没有预设的
prop.expr.value != null- 存在
sourceNodeprop.handler(sourceNode, prop.expr.value, prop.name, aNode);-
设置属性名为
name -
属性值不为空
-
在预热阶段就设置了静态属性 @@@
if (propName in el) { el[propName] = valueNotNull ? value : ''; } else if (valueNotNull) { el.setAttribute(name, value); } if (!valueNotNull) { el.removeAttribute(name); }
-
- 存在
初始化数据
// init data
var initData = extend(
// initData 是一个函数
typeof this.initData === 'function' && this.initData() || {},
options.data || this._srcSbindData
);
视图创建过程
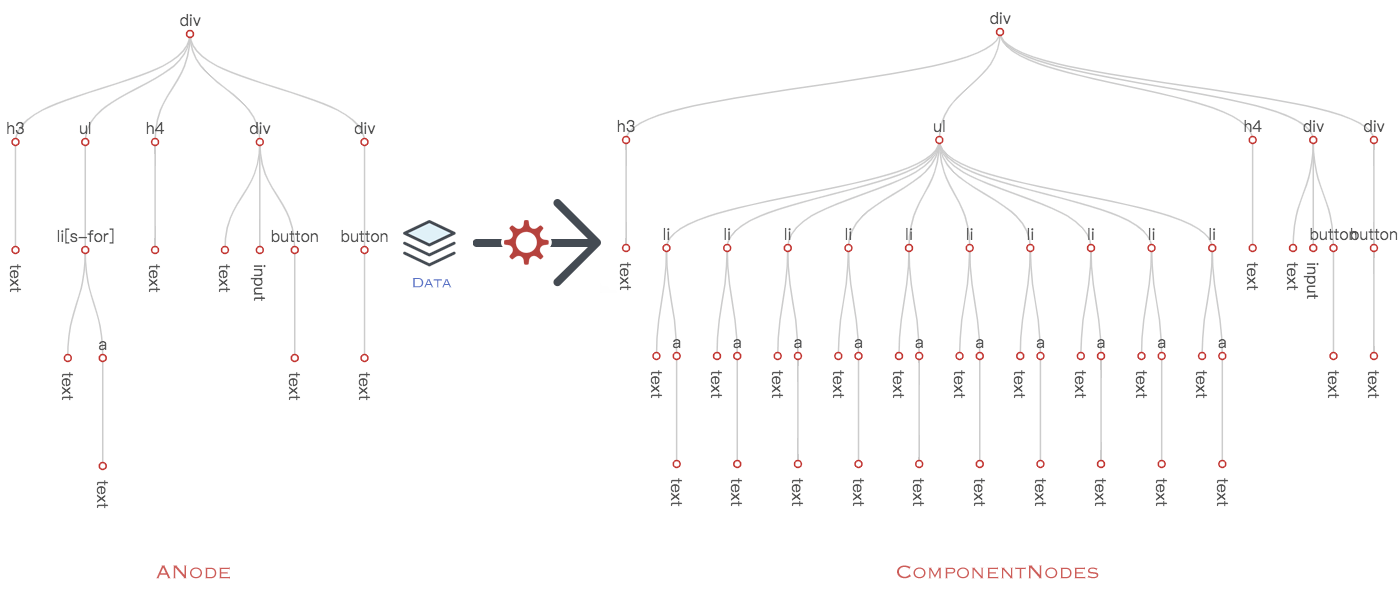
视图创建是个很常规的过程:基于初始的 数据 和 ANode,创建一棵对象树,树中的每个节点负责自身在 DOM 树上节点的操作(创建、更新、删除)行为。对一个组件框架来说,创建对象树的操作无法省略,所以这个过程一定比原始地 createElement + appendChild 慢。
因为这个过程比较常规,所以接下来不会描述整个过程,而是提一些有价值的优化点。
cloneNode
在 预热 阶段,我们根据 tagName 创建了 sourceNode。
if (isBrowser && aNode.tagName
&& !/^(template|slot|select|input|option|button)$/i.test(aNode.tagName)
) {
sourceNode = createEl(aNode.tagName);
}
ANode 中包含了所有的属性声明,我们知道哪些属性是动态的,哪些属性是静态的。对于静态属性,我们可以在 预热 阶段就直接设置好。
在 视图创建过程 中,就可以从 sourceNode clone,并且只对动态属性进行设置。See element.js#L115-L150
var sourceNode = this.aNode.hotspot.sourceNode;
var props = this.aNode.props;
if (sourceNode) {
this.el = sourceNode.cloneNode(false);
props = this.aNode.hotspot.dynamicProps;
}
else {
this.el = createEl(this.tagName);
}
// ...
for (var i = 0, l = props.length; i < l; i++) {
var prop = props[i];
var propName = prop.name;
var value = isComponent
? evalExpr(prop.expr, this.data, this)
: evalExpr(prop.expr, this.scope, this.owner);
// ...
prop.handler(this.el, value, propName, this, prop);
// ...
}
属性操作
不同属性对应 DOM 的操作方式是不同的,属性的 预热 提前保存了属性操作函数(preheat-a-node.js#L133),属性初始化或更新时就无需每次都重复获取。
prop.handler = getPropHandler(aNode.tagName, prop.name);
对于 s-bind,对应的数据是 预热 阶段无法预知的,所以属性操作函数只能在具体操作时决定。See element.js#L128-L137
for (var key in this._sbindData) {
if (this._sbindData.hasOwnProperty(key)) {
getPropHandler(this.tagName, key)( // 看这里看这里
this.el,
this._sbindData[key],
key,
this
);
}
}
所以,getPropHandler 函数的实现也进行了相应的结果缓存。See get-prop-handler.js
var tagPropHandlers = elementPropHandlers[tagName];
if (!tagPropHandlers) {
tagPropHandlers = elementPropHandlers[tagName] = {};
}
var propHandler = tagPropHandlers[attrName];
if (!propHandler) {
propHandler = defaultElementPropHandlers[attrName] || defaultElementPropHandler;
tagPropHandlers[attrName] = propHandler;
}
return propHandler;
创建节点
视图创建过程中,San 通过 createNode 工厂方法,根据 ANode 上每个节点的信息,创建组件的每个节点。
ANode 上与节点创建相关的信息有:
- if 声明
- for 声明
- 标签名
- 文本表达式
节点类型有:
- IfNode
- ForNode
- TextNode
- Element
- Component
- SlotNode
- TemplateNode
因为每个节点都通过 createNode 方法创建,所以它的性能是极其重要的。那这个过程的实现,有哪些性能相关的考虑呢?
首先,预热 过程提前选择好 ANode 节点对应的实际类型。See preheat-a-node.js#L58 preheat-a-node.js#L170 preheat-a-node.jsL185 preheat-a-node.jsL190
在 createNode 一开始就可以直接知道对应的节点类型。See create-node.js#L24-L26
if (aNode.Clazz) {
return new aNode.Clazz(aNode, parent, scope, owner);
}
另外,我们可以看到,除了 Component 之外,其他节点类型的构造函数参数签名都是 (aNode, parent, scope, owner, reverseWalker),并没有使用一个 Object 包起来,就是为了在节点创建过程避免创建无用的中间对象,浪费创建和回收的时间。
function IfNode(aNode, parent, scope, owner, reverseWalker) {}
function ForNode(aNode, parent, scope, owner, reverseWalker) {}
function TextNode(aNode, parent, scope, owner, reverseWalker) {}
function Element(aNode, parent, scope, owner, reverseWalker) {}
function SlotNode(aNode, parent, scope, owner, reverseWalker) {}
function TemplateNode(aNode, parent, scope, owner, reverseWalker) {}
function Component(options) {}
而 Component 由于使用者可直接接触到,初始化参数的便利性就更重要些,所以初始化参数是一个 options 对象。
Pending
ComponentClass 的 attach 方法是在哪里定义的?和 Element 类的 attach 方法有什么不同?
- 定义在原型上
初始的主节点是怎么完成 aNode 到真实 node 的转变的?后续子节点又是怎么完成的?
this.el=sourceNode.cloneNode(false)两者相同
初始节点的 attach 和 Element 节点的 attach 有什么不同?
- 初始节点一定是一个组件节点,问题转换为组件和 Element 的区别
Element的attach逻辑与Component._attach类似
this.nodeType 为 4 ,但是 this.el.nodeType 却是 1,说明 sourceNode.nodeType 就一直是 1。document.createElement() 的返回值,nodeType 全都是 1
- 为什么这个 api 会这样设计,因为
Node.prototype.nodeType,DOM 中元素节点的 nodeType 是 1,而 San 中元素节点的 nodeType 是 4,1 是 textNode
guid 是干啥的
- 用来生成全局唯一的 id,初始为 1
- component 初始化的时候第一次引用,被赋值为 1,然后自增了
- 在 forNode 中被再次引用了,被赋值为 2,然后自增了
API
evalExpr(expr,data)
计算表达式的值,依据 exprType,层层 switch,进行处理,最终返回表达式的值
通过 data 可以指定数据环境
insertBefore
纯粹的 parentNode.appenChild() 或者 parentNode.insertBefore()
sourceNode.cloneNode()
同 DOM
Attach
第一步从 aNode 中 cloneNode
视图创建的起点
const MyApp = san.defineComponent({...});
var myApp = new MyApp(); // 构造函数
myApp.attach(document.body);
在我们编写的 san 文件中,调用了 defineComponent
function defineComponent(proto, SuperComponent) {
// ...异常处理
function ComponentClass(option) { // eslint-disable-line
Component.call(this, option);
}
ComponentClass.prototype = proto;
inherits(ComponentClass, SuperComponent || Component);
return ComponentClass;
}
当我们调用返回的函数的时候,其会执行组件类 Component 函数,对组件进行初始化,其中就包括了模板解析,预热,初始化数据等
compileComponent(clazz);
var protoANode = clazz.prototype.aNode;
preheatANode(protoANode);
等组件类初始化完成之后,就会被 attach 到页面上,这就是视图创建的起点。具体可以查看 component.js
组件 Attach
sourceNode:div
直接调用了内部的 _attach
判断 if 指令
- cloneNode 操作
- 给
this.el赋值为当前 node - 复制动态
props - 处理
this._sbindData - 处理动态
props- 调用
evalExpr(prop.expr,this.data,this) - 依据
expr.type处理,有点类似于,type 依次为 7 5 4 1- type 4 最后
class值为undefined - type 5 处理默认的过滤器
- type 7 拼接,返回值为空字符串
- type 4 最后
- 调用
this._toPhase('created');,调用一波生命周期insertBefore(divNode,body,beforeEl)- 通过
this.__contentReady判断是否append完成- 通过
aNode遍历child调用attach方法
- 通过
H3
无有 clazz 属性
creatNode(),指定了this.data为scope,即数据环境- 不是
ComponentOrLoader - 普通 DOM 元素,
aNode.clazz = Element, return new Element(aNode,parent,scope,owner)- 创建 Element 对象,赋值
aNode,owner,scope,parent,lifeCycle,tagName - 判断 parent 是否是组件节点,
parent.__proto__.__proto__为 5,是什么时候定义的呢?Component 类的原型上定义的,类似的 Element 的原型上定义了 nodeType 为 4
- 创建 Element 对象,赋值
this.children.push(child);child.attach(this.el);等价于Element.attach与Component._attach逻辑类似cloneNode操作- 处理动态 props,本元素为空
- 没有调用 this._toPhase,因为不是组件,相应的指定了对应的生命周期,
this.lifeCycle = LifeCycle.created; insertBefore(h3Node,parentNode,beforeEl)- 通过
this.__contentReady判断是否append完成- 通过
aNode遍历child调用attach方法 - 参考
{{title}}
- 通过
this._contentReady = 1;- 明明前面已经
insertBefore了,还是再次调用了_attach,执行完成 attached 状态的行为-
this.nodeType 为 4 ,但是 this.el.nodeType 却是 1,说明 sourceNode.nodeType 就一直是 1。document.createElement() 的返回值,nodeType 全都是 1
以 sam-master 为准,dev 未必最新的
-
处理自身变化时双向绑定的逻辑
-
事件绑定逻辑
-
transition,出入场逻辑
-
this.lifeCycle = LifeCycle.attached;
- 不是
{{title}}
有 clazz 属性,为 TextNode
TextNode()构造函数this.children.push(child);child.attach(this.el);等价于TextNode.attach,逻辑独立- 通过 evalExpr() 获取文本内容
- exprType 依次是 7 5 4 1,type 4 需要从数据环境中获取值
- 最终返回
List
this.aNode.textExpr.originalthis.el = document.createTextNode(this.content);insertBefore
- 通过 evalExpr() 获取文本内容
ul>li
ul 的创建过程比较常规,关键是 li
liNode.clazz 为 forNode,ForNode()
- 构造函数,修饰对象
-
this.id = guid++; // 有什么用呢? this.children = []; // attach 时通过 this.param.value this.param = aNode.directives['for']; // eslint-disable-line dot-notation this.itemPaths = [ { type: ExprType.STRING, value: this.param.item } ]; this.itemExpr = { type: ExprType.ACCESSOR, paths: this.itemPaths, raw: this.param.item }; if (this.param.index) { this.indexExpr = createAccessor([{ type: ExprType.STRING, value: '' + this.param.index }]); }
ForNode.attach()
this.create()document.createComment(this.id)this.id 为 2,生成了一个注释节点
insertBefore(this.el)- 获取
listData,evalExpr(this.param.value, this.scope, this.owner)exprType依次为 4 1,list 初始值为空this._createChildren(),专门创建子元素的函数
div>input
在创建 input 元素的时候
this._sbindData = nodeSBindInit(aNode.directives.bind, this.scope, this.owner);directives为空,为什么呢?因为是Init,value是没有初始值的
input 元素 attach
- cloneNode
- sbind 初始化???@@@
- 处理 props,有 type 和 value,静态属性 type 之前应该已经设置好了
-
因此
type,evalExpr,直接就可以拿到text -
prop.handler,defaultElementPropHandler(el, value, name),设置属性 -
value,双向绑定,虽然是双向绑定,但是一路看下来也没有什么特殊的处理,绑定的handler也是默认的原来是放到 elementOwnAttached 里了
-
elementOwnAttached
双向绑定的相关
视图更新
从数据变更到遍历更新
Data
我们可以很容易的发现,data 是:
- 组件上的一个属性,组件的数据状态容器
- 一个对象,提供了数据读取和操作的方法。See 数据操作文档
- Observable。每次数据的变更都会
fire,可以通过listen方法监听数据变更。See data.js
data 是变化可监听的,所以组件的视图变更就有了基础出发点。
/**
* 触发数据变更
*
* @param {Object} change 变更信息对象
*/
Data.prototype.fire = function (change) {
if (change.option.silent || change.option.silence || change.option.quiet) {
return;
}
for (var i = 0; i < this.listeners.length; i++) {
this.listeners[i].call(this, change);
}
};
视图更新过程
San 最初设计的时候想法很简单:模板声明包含了对数据的引用,当数据变更时可以精准地只更新需要更新的节点,性能应该是很高的。从上面组件例子的模板中,一眼就能看出,title 数据的修改,只需要更新一个节点。但是,我们如何去找到它并执行视图更新动作呢?这就是组件的视图更新机制了。其中,有几个关键的要素:
- 组件在初始化的过程中,创建了
data实例并监听其数据变化。See component.js#L255 - 视图更新是异步的。数据变化会被保存在一个数组里,在
nextTick时批量更新。See component.js#L782
this._initDataChanger();
Component.prototype._initDataChanger = function (change) {
var me = this;
this._dataChanger = function (change) {
if (me._afterLife.created) {
if (!me._dataChanges) {
nextTick(me._update, me);
me._dataChanges = [];
}
me._dataChanges.push(change);
}
else if (me.lifeCycle.inited && me.owner) {
me._updateBindxOwner([change]);
}
};
this.data.listen(this._dataChanger);
};
- 组件是个
children属性串联的节点树,视图更新是个自上而下遍历的过程。
在节点树更新的遍历过程中,每个节点通过 _update({Array}changes) 方法接收数据变化信息,更新自身的视图,并向子节点传递数据变化信息。component.js#L688 是组件向下遍历的起始,但从最典型的 Element的_update方法 可以看得更清晰些:
- 先看自身的属性有没有需要更新的
- 然后把数据变化信息通过
children往下传递。
// 节选
Element.prototype._update = function (changes) {
// ......
// 先看自身的属性有没有需要更新的
var dynamicProps = this.aNode.hotspot.dynamicProps;
for (var i = 0, l = dynamicProps.length; i < l; i++) {
var prop = dynamicProps[i];
var propName = prop.name;
for (var j = 0, changeLen = changes.length; j < changeLen; j++) {
var change = changes[j];
if (!isDataChangeByElement(change, this, propName)
&& changeExprCompare(change.expr, prop.hintExpr, this.scope)
) {
prop.handler(this.el, evalExpr(prop.expr, this.scope, this.owner), propName, this, prop);
break;
}
}
}
// ......
// 然后把数据变化信息通过 children 往下传递
for (var i = 0, l = this.children.length; i < l; i++) {
this.children[i]._update(changes);
}
};
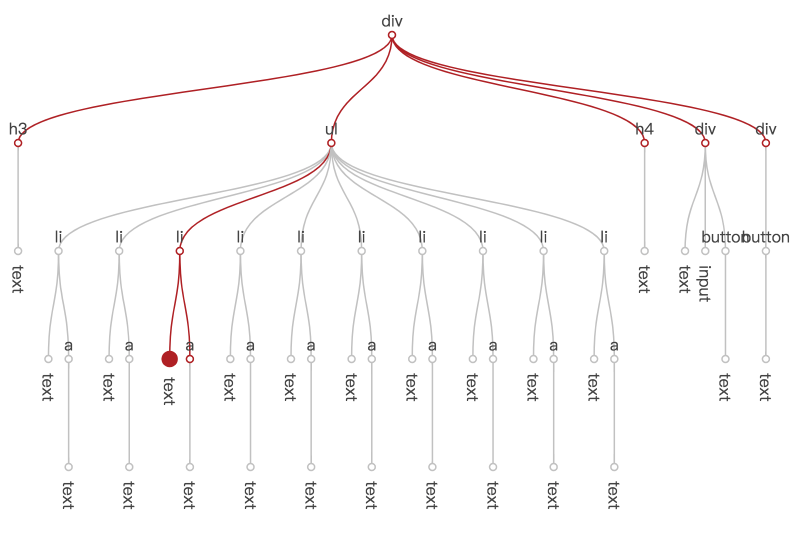
下面这张图说明了在节点树中,this.data.set('title', 'hello') 带来的视图刷新,遍历过程与数据变化信息的传递经过了哪些节点。左侧最大的点是实际需要更新的节点,红色的线代表遍历过程经过的路径,红色的小圆点代表遍历到的节点。可以看出,虽然需要进行视图更新的节点只有一个,但所有的节点都被遍历到了。
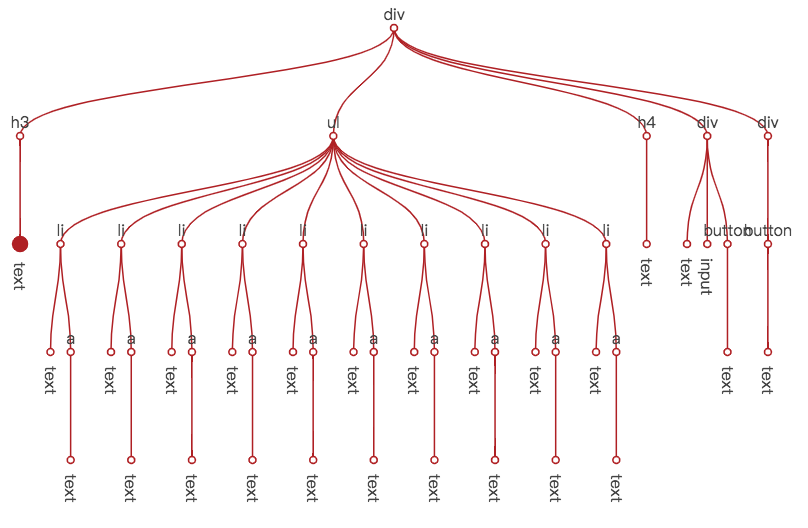
节点遍历中断
从上图中不难发现,与实际的更新行为相比,遍历确定更新节点的消耗要大得多。所以为遍历过程减负,是一个必要的事情。San 在这方面是怎么做的呢?
首先,预热 过程生成的 hotspot 对象中,有一项 data,包含了节点及其子节点对数据引用的摘要信息。See preheat-a-node.js
然后,在视图更新的节点树遍历过程中,使用 hotspot.data 与数据变化信息进行比对。结果为 false 时意味着数据的变化不会影响当前节点及其子节点的视图,就不会执行自身属性的更新,也不会继续向下遍历。遍历过程在更高层的节点被中断,节省了下层子树的遍历开销。See element.js#241 changes-is-in-data-ref.js
Element.prototype._update = function (changes) {
var dataHotspot = this.aNode.hotspot.data;
if (dataHotspot && changesIsInDataRef(changes, dataHotspot)) {
// ...
}
};
有了节点遍历中断的机制,title 数据修改引起视图变更的遍历过程如下。可以看到,灰色的部分都是由于中断,无需到达的节点。
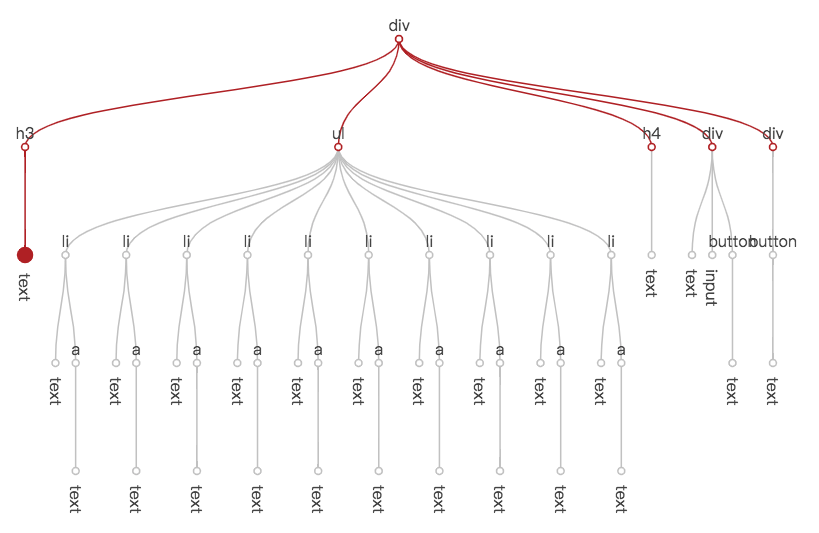
有没有似曾相识的感觉?是不是很像 React 中的 shouldComponentUpdate?不过不同的是,由于模板声明包含了对数据的引用,San 可以在框架层面自动做到这一点,组件开发者不需要人工去干这件事了。
Immutable
Immutable 在视图更新中最大的意义是,可以无脑认为 === 时,数据是没有变化的。在很多场景下,对视图是否需要更新的判断变得简单很多。否则判断的成本对应用来说是不可接受的。
但是,Immutable 可能会导致开发过程的更多成本。如果开发者不借助任何库,只使用原始的 JavaScript,一个对象的赋值会写的有些麻烦。
var obj = {
a: 1,
b: {
b1: 2,
b2: 3
},
c: 2
};
// mutable
obj.b.b1 = 5;
// immutable
obj = Object.assign({}, obj, {b: Object.assign({}, obj.b, {b1: 5})});
San 的 数据操作 是通过 data 上的方法提供的,所以内部实现可以天然 immutable,这利于视图更新操作中的一些判断。See data.js#L209
由于视图刷新是根据数据变化信息进行的,所以判断当数据没有变化时,不产生数据变化信息就行了。See data.js#L204 for-node.jsL570 L595 L679 L731
San 期望开发者对数据操作细粒度的使用 数据操作方法。否则,不熟悉 immutable 的开发者可能会碰到如下情况。
// 假设初始数据如下
/*
{
a: 1,
b: {
b1: 2,
b2: 3
}
}
*/
var b = this.data.get('b');
b.b1 = 5;
// 由于 b 对象引用不变,会导致视图不刷新
this.data.set('b', b);
// 正确做法。set 操作在 san 内部是 immutable 的
this.data.set('b.b1', 5);
Pending
对 expr 进行浅复制
API
_initDataChanger
在 nextTick 执行 me._update,但是没有传递 changeobj
parseExpr()
解析表达式,与上一个 parserInterp 类似
data.fire
传递 changeObj,遍历执行 listener
nextTick
在下一个时间周期运行任务
bind(fn,thisArg)
nextHandler,取出 tasks 队列里所有的任务执行
setImmediate
或者
MessageChannel
或者
Promise.resolve().then(nextHandler)
最次
setTimeout(fn,0)
具体过程
TextExpr-changeTitle()
新增了一个按钮,当点击该按钮时触发属性更新
changeTitle() {
this.data.set('title', 'new Title')
}
通过 parseExpr() 解析 'title',转换成 expr 对象
this.get(expr) 判断 data 是否和原值相等,如果相等直接 return
对 expr 进行浅复制
immutableSet
fire
this.fire({
type: DataChangeType.SET,
expr: expr,
value: value,
option: option
});
_initDataChanger
nextTick(me._update,me)me._dataChanges.push(change)
nextTick 之后执行 me._update
不知道为什么 changes 是空的,明明 fire 接受的参数就是 changeobj
因为 _initChange,没有继续传递 changeobj
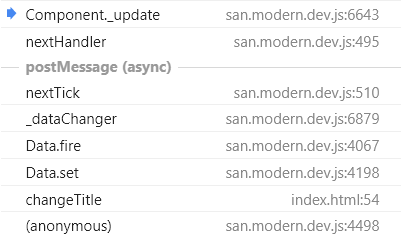
changes 为空,从 this._dataChanges 中取出 datachange
this._dataChanges 是什么时候赋值的呢?_initDataChanger 的时候
- 双向绑定处理
- 仅对动态属性进行判断,
this.aNode.hotspot.dynamicProps;changeExprCompare,比对动态属性和改变的属性- 遍历子孙调用
_update,传递 changeobjh3Element._update- 影响到了引用摘要,不中断
- 双向绑定处理
- 仅对动态属性进行处理,h3 动态属性为空
- 遍历子孙调用
_update,传递 changeobjTextNode._updatechangeExprCompareevalExprthis.content=text
- 遍历子孙调用
双向绑定更新
通过复制一段文本到 value 中触发
触发的起点是哪里呢?双绑输入框 CompositionStart 事件监听函数,在之前就被绑定好了函数,是什么时候绑定的呢?elementOwnAttached
xPropOutput(element,bindInfo,data)
- 不是 checked 类型的 input
- data.set(bindInfo.expr,el[bindInfo.name],options)
- 过程与 Text 的处理类似,直到 Conpoment._update 双向绑定部分
- this._sbindData = nodeSBindUpdate()。sbind 是 undefined,也就没有啥区别了
- 没有元素是依赖于 value 的,data 本身已经更新过了,因此后面都是一样的
属性更新
在视图创建过程的章节中,提到过在 预热 过程中,我们得到了:
- dynamicProps:哪些属性是动态的。See preheat-a-node.js#L117
- prop.handler:属性的设置操作函数。See preheat-a-node.jsL119
<input type="text" value="{=value=}">
在上面这个例子中,dynamicProps 只包含 value,不包含 type。
所以在节点的属性更新时,我们只需要遍历 hotspot.dynamicProps,并且直接使用 prop.handler 来执行属性更新。See element.js#L259-L277
Element.prototype._update = function (changes) {
// ......
// 先看自身的属性有没有需要更新的
var dynamicProps = this.aNode.hotspot.dynamicProps;
for (var i = 0, l = dynamicProps.length; i < l; i++) {
var prop = dynamicProps[i];
var propName = prop.name;
for (var j = 0, changeLen = changes.length; j < changeLen; j++) {
var change = changes[j];
if (!isDataChangeByElement(change, this, propName)
&& changeExprCompare(change.expr, prop.hintExpr, this.scope)
) {
prop.handler(this.el, evalExpr(prop.expr, this.scope, this.owner), propName, this, prop);
break;
}
}
}
// ......
};
列表更新
列表数据操作方法
上文中我们提到,San 的视图更新机制是基于数据变化信息的。数据操作方法 提供了一系列方法,会 fire changeObj。changeObj 只有两种类型: SET 和 SPLICE。See data-change-type.js data.js#L211 data.js#L352
// SET
changeObj = {
type: DataChangeType.SET,
expr,
value,
option
};
// SPLICE
changeObj = {
type: DataChangeType.SPLICE,
expr,
index,
deleteCount,
value,
insertions,
option
};
San 提供的 数据操作方法 里,很多是针对数组的,并且大部分与 JavaScript 原生的数组方法是一致的。从 changeObj 的类型可以容易看出,最基础的方法只有 splice 一个,其他方法都是 splice 之上的封装。
- push
- pop
- shift
- unshift
- remove
- removeAt
- splice
基于数据变化信息的视图更新机制,意味着数据操作的粒度越细越精准,视图更新的负担越小性能越高。
// bad performance
this.data.set('list[0]', {
name: 'san',
id: this.data.get('list[0].id')
});
// good performance
this.data.set('list[0].name', 'san');
更新过程
我们看个简单的例子:下图中,我们要把第一行的列表更新成第二行,需要插入绿色部分,更新黄色部分,删除红色部分。
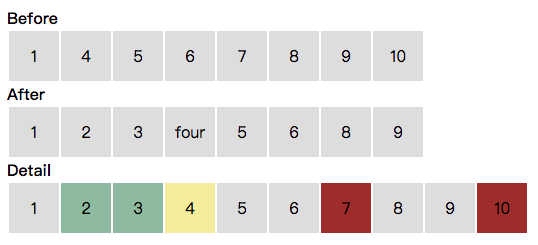
San 的 ForNode 负责列表的渲染和更新。在更新过程里:
- _update 方法接收数据变化信息后,根据类型进行分发
- _updateArray 负责处理数组类型的更新。其遍历数据变化信息,计算得到更新动作,最后执行更新行为。
假设数据变化信息为:
[
// insert [2, 3], pos 1
// update 4
// remove 7
// remove 10
]
在遍历数据变化信息前,我们先初始化一个和当前 children 等长的数组:childrenChanges。其用于存储 children 里每个子节点的数据变化信息。See for-node.js#L352
同时,我们初始化一个 disposeChildren 数组,用于存储需要被删除的节点。See for-node.js#L362
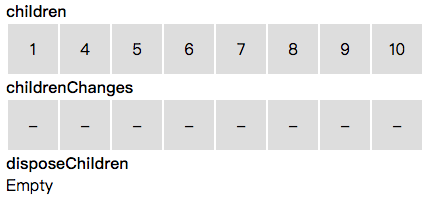
接下来,_updateArray 循环处理数据变化信息。当遇到插入时,同时扩充 children 和 childrenChanges 数组。
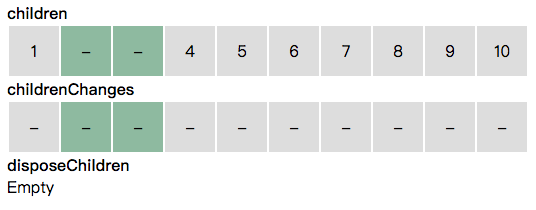
当遇到更新时,如果更新对应的是某一项,则对应该项的 childrenChanges 添加更新信息。
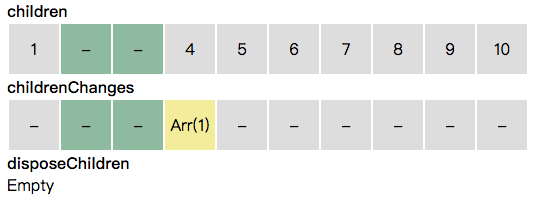
当遇到删除时,我们把要删除的子节点从 children 移除,放入 disposeChildren。同时,childrenChanges 里相应位置的项也被移除。
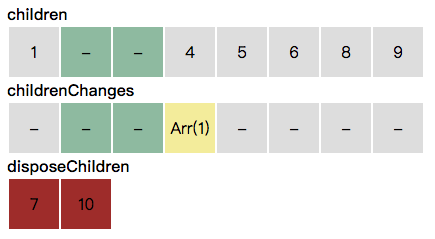
遍历数据变化信息结束后,执行更新行为分成两步:See for-node.js#L772-L823
- 先执行删除 disposeChildren
- 遍历 children,对标记全新的子节点执行创建与插入,对存在的节点根据 childrenChanges 相应位置的信息执行更新
this._disposeChildren(disposeChildren, function () {
doCreateAndUpdate();
});
下面,我们看看常见的列表更新场景下, San 都有哪些性能优化的手段。
添加项
在遍历数据变化信息时,遇到添加项,往 children 和 childrenChanges 中填充的只是 undefined 或 0 的占位值,不初始化新节点。See for-node.js#L518-L520
var spliceArgs = [changeStart + deleteCount, 0].concat(new Array(newCount));
this.children.splice.apply(this.children, spliceArgs);
childrenChanges.splice.apply(childrenChanges, spliceArgs);
由于 San 的视图是异步更新的,当前更新周期可能包含多个数据操作。如果这些数据操作中创建了一个项又删除了的话,在遍历数据变化信息过程中初始化新节点就是没有必要的浪费。所以创建节点的操作放到后面 执行更新 的阶段。
删除项
前文中提过,视图创建的过程,对于 DOM 的创建是挨个 createElement 并 appendChild 到 parentNode 中的。但是在删除的时候,我们并不需要把整棵子树上的节点都挨个删除,只需要把要删除子树的根元素从 parentNode 中 removeChild。
所以,对于 Element、TextNode、ForNode、IfNode 等节点的 dispose 方法,都包含一个隐藏参数:noDetach。当接收到的值为 true 时,节点只做必要的清除操作(移除 DOM 上挂载的事件、清理节点树的引用关系),不执行其对应 DOM 元素的删除操作。See text-node.js#L118 node-own-simple-dispose.js#L22 element.js#L211 etc...
if (!noDetach) {
removeEl(this.el);
}
另外,在很多情况下,一次视图更新周期中如果有数组项的删除,是不会有对其他项的更新操作的。所以我们增加了 isOnlyDispose 变量用于记录是否只包含数组项删除操作。在 执行更新 阶段,如果该项为 true,则完成删除动作后不再遍历 children 进行子项更新。See for-node.js#L787
if (isOnlyDispose) {
return;
}
// 对相应的项进行更新
// 如果不attached则直接创建,如果存在则调用更新函数
for (var i = 0; i < newLen; i++) {
}
Length
数据变化(添加项、删除项等)可能会导致数组长度变化,数组长度也可能会被数据引用。
<li s-for="item, index in list">{{index + 1}}/{{list.length}} item</li>
在这种场景下,即使只添加或删除一项,整个列表视图都需要被刷新。由于子节点的更新是在 执行更新 阶段通过 _update 方法传递数据变化信息的,所以在 执行更新 前,我们根据以下两个条件,判断是否需要为子节点增加 length 变更信息。See for-node.js#L752-L767
- 数组长度是否发生变化
- 通过数据摘要判断子项视图是否依赖 length 数据。这个判断逻辑上是多余的,但是可以减少子项更新的成本
清空
首先,当数组长度为 0 时,显然整个列表项直接清空就行了,数据变化信息可以完全忽略,不需要进行多余的遍历。See for-node.js#L248-L251
其次,如果一个元素里的所有元素都是由列表项组成的,那么元素的删除可以暴力清除:通过一次 parentNode.textContent = '' 完成,无需逐项从父元素中移除。See for-node.js#L316-L332
// 代码节选
var violentClear = !this.aNode.directives.transition
&& !children
// 是否 parent 的唯一 child
&& len && parentFirstChild === this.children[0].el && parentLastChild === this.el
;
// ......
if (violentClear) {
parentEl.textContent = '';
}
子项更新
想象下面这个列表数据子项的变更:
myApp.data.set('list[2]', 'two');
对于 ForNode 的更新:
-
首先使用 changeExprCompare 方法判断数据变化对象与列表引用数据声明之间的关系。See change-expr-compare.js
-
如果属于子项更新,则转换成对应子项的数据变更信息,其他子项对该信息无感知。See for-node.js#L426
从上图的更新过程可以看出,子项更新的更新过程能精确处理最少的节点。数据变更时精准地更新节点是 San 的优势。
整列表变更
对于整列表变更,San 的处理原则是:尽可能重用当前存在的节点。原列表与新列表数据相比:
- 原列表项更多
- 新列表项更多
- 一样多
我们采用了如下的处理过程,保证原列表与新列表重叠部分节点执行更新操作,无需删除再创建:
- 如果原列表项更多,从尾部开始把多余的部分标记清除。See for-node.js#L717-L721
- 从起始遍历新列表。如果在旧列表长度范围内,标记更新 (See for-node.js#L730-L740);如果是新列表多出的部分,标记新建 (See for-node.js#L742)。
San 鼓励开发者细粒度的使用 数据操作方法,但总有无法精准进行数据操作,只能直接 set 整个数组。举一个最常见的例子:数据是从服务端返回的 JSON。在这种场景下,就是 trackBy 发挥作用的时候了。
trackBy
<ul>
<li s-for="p in persons trackBy p.name">{{p.name}} - {{p.email}}</li>
</ul>
trackBy 也叫 keyed,其作用就是当列表数据 无法进行引用比较 时,告诉框架一个依据,框架就可以判断出新列表中的项是原列表中的哪一项。上文提到的:服务端返回的数据,是 无法进行引用比较 的典型例子。
这里我们不说 trackBy 的整个更新细节,只提一个优化手段。这个优化手段不是 San 独有的,而是经典的优化手段。
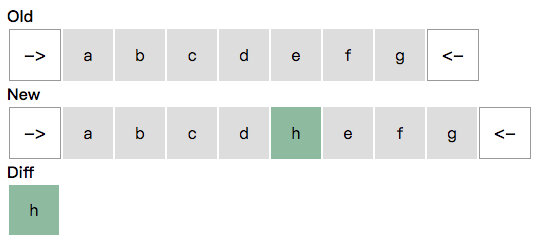
可以看到,我们从新老列表的头部和尾部进行分别遍历,找出新老列表头部和尾部的相同项,并把他们排除。这样剩下需要进行 trackBy 的项可能就少多了。对应到常见的视图变更场景,该优化手段都能发挥较好的作用。
- 添加:无论在什么位置添加几项,该优化都能发挥较大作用
- 删除:无论在什么位置删除几项,该优化都能发挥较大作用
- 更新部分项:头尾都有更新时,该优化无法发挥作用。也就是说,对于长度固定的列表有少量新增项时,该优化无用。不过 trackBy 过程在该场景下,性能消耗不高
- 更新全部项:trackBy 过程在该场景下,性能消耗很低
- 交换:相邻元素的交换,该优化都能发挥较大作用。交换的元素间隔越小,该优化发挥作用越大
优化手段
在这个部分,我会列举一些大多数人觉得知道、但又不会这么去做的优化写法。这些优化写法貌似对性能没什么帮助,但是积少成多,带来的性能增益还是不可忽略的。
避免 Call 和 Apply
call 和 apply 是 JavaScript 中的魔法,也是性能的大包袱。在 San 中,我们尽可能减少 call 和 apply 的使用。下面列两个点:
比如,对 filter 的处理中,内置的 filter 由于都是 pure function,我们明确知道运行结果不依赖 this,并且参数个数都是确定的,所以无需使用 call。See eval-expr.js#L164-L172
if (owner.filters[filterName]) {
value = owner.filters[filterName].apply(
owner,
[value].concat(evalArgs(filter.args, data, owner))
);
}
else if (DEFAULT_FILTERS[filterName]) {
value = DEFAULT_FILTERS[filterName](value);
}
再比如,Component 和 Element 之间应该是继承关系,create、attach、dispose、toPhase 等方法有很多可以复用的逻辑。基于性能的考虑,实现中并没有让 Component 和 Element 发生关系。对于复用的部分:
- 复用逻辑较少的直接再写一遍(See component.js#L355)
- 复用逻辑多的,部分通过函数直接调用的形式复用(See element-get-transition.js etc...),部分通过函数挂载到 prototype 成为实例方法的形式复用(See element-own-dispose.js etc...)。场景和例子比较多,就不一一列举了。
减少中间对象
看到这里的你不知是否记得,在 创建节点 章节中,提到节点的函数签名不合并成一个数组,就是为了防止中间对象的创建。中间对象不止是创建时有开销,触发 GC 回收内存也是有开销的。在 San 的实现中,我们尽可能避免中间对象的创建。下面列两个点:
数据操作的过程,直接传递表达式层级数组,以及当前指针位置。不使用 slice 创建表达式子层级数组。See data.js#L138
function immutableSet(source, exprPaths, pathsStart, pathsLen, value, data) {
if (pathsStart >= pathsLen) {
return value;
}
// ......
}
data 创建时如果传入初始数据对象,以此为准,避免 extend 使初始数据对象变成中间对象。See data.js#L23
function Data(data, parent) {
this.parent = parent;
this.raw = data || {};
this.listeners = [];
}
减少函数调用
函数调用本身的开销是很小的,但是调用本身也会初始化环境对象,调用结束后环境对象也需要被回收。San 对函数调用较为频繁的地方,做了避免调用的条件判断。下面列两个点:
element 在创建子元素时,判断子元素构造器是否存在,如果存在则无需调用 createNode 函数。See element.js#L167-L169
var child = childANode.Clazz
? new childANode.Clazz(childANode, this, this.scope, this.owner)
: createNode(childANode, this, this.scope, this.owner);
ANode 中对定值表达式(数字、bool、字符串字面量)的值保存在对象的 value 属性中。evalExpr 方法开始时根据 expr.value != null 返回。不过在调用频繁的场景(比如文本的拼接、表达式变化比对、等等),会提前进行一次判断,减少 evalExpr 的调用。See eval-expr.js#L203 change-expr-compare.js#L77
buf += seg.value || evalExpr(seg, data, owner);
另外,还有很重要的一点:San 里虽然实现了 each 方法,但是在视图创建、视图更新、变更判断、表达式取值等关键性的过程中,还是直接使用 for 进行遍历,就是为了减少不必要的函数调用开销。See each.js eval-expr.js etc...
// bad performance
each(expr.segs.length, function (seg) {
buf += seg.value || evalExpr(seg, data, owner);
});
// good performance
for (var i = 0, l = expr.segs.length; i < l; i++) {
var seg = expr.segs[i];
buf += seg.value || evalExpr(seg, data, owner);
}
减少对象遍历
使用 for...in 进行对象的遍历是非常耗时的操作,San 在视图创建、视图更新等过程中,当运行过程明确时,尽可能不使用 for...in 进行对象的遍历。一个比较容易被忽略的场景是对象的 extend,其隐藏了 for...in 遍历过程。
function extend(target, source) {
for (var key in source) {
if (source.hasOwnProperty(key)) {
var value = source[key];
if (typeof value !== 'undefined') {
target[key] = value;
}
}
}
return target;
}
从一个对象创建一个大部分成员都一样的新对象时,避免使用 extend。See for-node.jsL404
// bad performance
change = extend(
extend({}, change),
{
expr: createAccessor(this.itemPaths.concat(changePaths.slice(forLen + 1)))
}
);
// good performance
change = change.type === DataChangeType.SET
? {
type: change.type,
expr: createAccessor(
this.itemPaths.concat(changePaths.slice(forLen + 1))
),
value: change.value,
option: change.option
}
: {
index: change.index,
deleteCount: change.deleteCount,
insertions: change.insertions,
type: change.type,
expr: createAccessor(
this.itemPaths.concat(changePaths.slice(forLen + 1))
),
value: change.value,
option: change.option
};
将一个对象的成员赋予另一个对象时,避免使用 extend。See component.jsL113
// bad performance
extend(this, options);
// good performance
this.owner = options.owner;
this.scope = options.scope;
this.el = options.el;
生命周期
消息和自定义事件的区别
San 是如何渲染一个组件的
var MyApp = san.defineComponent({
template: '<p>Hello {{name}}!</p>',
initData: function () {
return {
name: 'San'
};
}
});
var myApp = new MyApp();
myApp.attach(document.body);
defineComponent 和 new MyApp() 这一步只是创建了空壳,传入的对象都在 component.prototype.option 上,component 本身是空的。因为此时还没有创建 el,没有真正的 children
这部分 san-native 和 san 是差不多的