dom-interface
2023-02-14
概述
DOM 规范
正如 W3C 所定义的,DOM 是独立于平台和语言的接口,该接口为程序和脚本提供了对文档的内容、结构和样式的动态获取和更新的功能。
DOM 的出现来自对动态页面的需求,先有 DOM 的实现(Netscape DOM0),再有各个厂商对 DOM 实现规范的需求,再有了 W3C Activity Statement 对于 DOM 发展的规范,然后才有了我们所说的“DOM”。
- DOM0:不是 W3C 规范。
- DOM1:开始是 W3C 规范。专注于 HTML 文档和 XML 文档。
- DOM2:对 DOM1 增加了样式表对象模型 (DOM2)
- DOM3:对 DOM2 增加了内容模型 (DTD 、Schemas) 和文档验证。
DOM0
DOM0 指的是 Necscape3.0 和 IE3.0 提供对于 HTML 文档功能,实现了包括元素 (HTML Element)、表单 (Form)、图像 (Image) 等的接口和方法。DOM0 虽然年代久远,某些实现并不符合新的 DOM 理念,但为了向后兼容,很多现代浏览器仍然支持 DOM0 的某些方法和属性。即便某些方法的实现原理有所不同,但提供了可用性。
DOM0 出现后,各厂商意识到 DOM 的前景,纷纷向 W3C 建议 DOM 的规范化。于是出现了 W3C DOM Activity Statement(DOM 的活动清单)以及 DOM1、DOM2、DOM3 规范 (Specification)
DOM1
DOM1 1.0 版本发布于 1998 年 10 月 1 日,是第一个 DOM 规范。
DOM1 包含两部分:
- DOM1 Core:定义了 DOM 最基本的接口,包括 Document,Node,NodeList 等等。
- DOM1 THML:HTML 文档是 DOM 的一种实现,该规范定义了基于 DOM1 Core 的 HTML 文档实现。
DOM2
DOM2 规范在 2000 年 11 月 13 日发布,主要包含 6 个模块,相比于 DOM1,DOM2 更加丰富,更加完善,目前主流浏览器对 DOM2 有着良好的支持。
DOM2 Core: 相比于 DOM1 Core,DOM2 丰富了 Document,Node 等接口的功能,
DOM2 View:View 提供的是 DOM 的表现形式,同一个文档源 (document source),可能有不同的表现形式,DOM2 View 引入了 Abstract View 和 Document View 接口。
DOM2 Event:DOM 事件处理系统规范,DOM1 中并未对 DOM 的事件模型进行定义,在 DOM2 中规范事件模型 (Event Model) 主要有两个目的:
- 设计一套通用的事件系统,实现事件处理程序的注册和注销,描述事件的流动 (Event Flow),事件的上下文信息 (Contextual Information ) 等;
- 提供一套规范子集兼容老版本浏览器 DOM0 的事件实现。
DOM2 Style:程序和脚本动态地获取和更新 DOM 的样式,提供包括 Style Sheet, Cascading Style Sheet, CSSRule, CSSStyleDeclaration, getComputedStyle 接口。DOM2 Style 的实现基于 DOM2 Core 和 DOM2 View。
DOM2 Traverse and Range:DOM2 Traverse 是关于文档节点遍历的规范,包括 Treewalker,NodeIterator 和 NodeFilter 等
DOM2 Range 是关于 DOM 片段 (Document Fragment) 操作的规范,譬如 DocumentFragment。
DOM2 HTML:在 DOM1 HTML 的基础上结合 DOM2 Core 推出了一些新的接口和属性
DOM3
DOM3 首次发布于 2004 年 4 月,主要包括 Core、Load and Save、Validation、XPath、View and Formatting、Events 和 Abstract Schemas7 个模块。目前主流浏览器对 DOM3 的支持比较有限
DOM IDL
interface description language
class 派生类名 : 继承方式 基类名
{
派生类的成员
};
继承方式:public、private和protected,默认处理是public。
DOM IDL DOM 的接口定义语言
定义了接口和结果,具体的实现由浏览器的厂商自己决定,但是结果必须符合规范,谁的方法性能更强,谁的浏览器就更好
DOM
DOM 是 JavaScript 操作网页的接口,全称为“文档对象模型”(Document Object Model)。它的作用是将网页转为一个 JavaScript 对象,从而可以用脚本进行各种操作(比如增删内容)。
浏览器会根据 DOM 模型,将结构化文档(比如 HTML 和 XML)解析成一系列的节点,再由这些节点组成一个树状结构(DOM Tree)。所有的节点和最终的树状结构,都有规范的对外接口。
DOM 只是一个接口规范,可以用各种语言实现。所以严格地说,DOM 不是 JavaScript 语法的一部分,但是 DOM 操作是 JavaScript 最常见的任务,离开了 DOM,JavaScript 就无法控制网页。另一方面,JavaScript 也是最常用于 DOM 操作的语言。后面介绍的就是 JavaScript 对 DOM 标准的实现和用法。
文档对象模型,通过 DOM 可以来任意来修改网页中各个内容
- 文档:文档指的是网页,一个网页就是一个文档
- 对象:对象指将网页中的每一个节点都转换为对象,转换完对象以后,就可以以一种纯面向对象的形式来操作网页了
- 模型:模型用来表示节点和节点之间的关系,方便操作页面
节点(Node)
DOM 的最小组成单位叫做节点(node)。文档的树形结构(DOM 树),就是由各种不同类型的节点组成。每个节点可以看作是文档树的一片叶子。
节点的类型有七种。
Document:整个文档树的顶层节点DocumentType:doctype标签(比如<!DOCTYPE html>)Element:网页的各种 HTML 标签(比如<body>、<a>等)- 只有元素节点才有子节点!!
Attribute:网页元素的属性(比如class="right")- 属性节点表示标签后中的一个个属性,要注意,属性节点并非元素节点的子节点,而是元素节点的一部分
- 元素节点.getAttributeNode(“属性名”);
- 但是我们一般不会使用该方法,因为直接访问元素的属性更加方便快捷
Text:标签之间或标签包含的文本Comment:注释DocumentFragment:文档的片段
浏览器提供一个原生的节点对象 Node,上面这七种节点都继承了 Node,因此具有一些共同的属性和方法。
节点树
一个文档的所有节点,按照所在的层级,可以抽象成一种树状结构。这种树状结构就是 DOM 树。它有一个顶层节点,下一层都是顶层节点的子节点,然后子节点又有自己的子节点,就这样层层衍生出一个金字塔结构,倒过来就像一棵树。
浏览器原生提供 document 节点,代表整个文档。
文档的第一层有两个节点,第一个是文档类型节点(<!doctype html>),第二个是 HTML 网页的顶层容器标签 <html>。后者构成了树结构的根节点(root node),其他 HTML 标签节点都是它的下级节点。
除了根节点,其他节点都有三种层级关系。
- 父节点关系(parentNode):直接的那个上级节点
- 子节点关系(childNodes):直接的下级节点
- 同级节点关系(sibling):拥有同一个父节点的节点
DOM 提供操作接口,用来获取这三种关系的节点。比如,子节点接口包括 firstChild(第一个子节点)和 lastChild(最后一个子节点)等属性,同级节点接口包括 nextSibling(紧邻在后的那个同级节点)和 previousSibling(紧邻在前的那个同级节点)属性。
Node 接口
所有 DOM 节点对象都继承了 Node 接口,拥有一些共同的属性和方法。这是 DOM 操作的基础。
属性
Node.prototype.nodeType
nodeType 属性返回一个整数值,表示节点的类型。
Node 对象定义了几个常量,对应这些类型值。
document.nodeType === Node.DOCUMENT_NODE // true
上面代码中,文档节点的 nodeType 属性等于常量 Node.DOCUMENT_NODE。
不同节点的 nodeType 属性值和对应的常量如下。
- 文档节点(document):9,对应常量
Node.DOCUMENT_NODE - 元素节点(element):1,对应常量
Node.ELEMENT_NODE - 属性节点(attr):2,对应常量
Node.ATTRIBUTE_NODE - 文本节点(text):3,对应常量
Node.TEXT_NODE - 文档片断节点(DocumentFragment):11,对应常量
Node.DOCUMENT_FRAGMENT_NODE - 文档类型节点(DocumentType):10,对应常量
Node.DOCUMENT_TYPE_NODE - 注释节点(Comment):8,对应常量
Node.COMMENT_NODE
确定节点类型时,使用 nodeType 属性是常用方法。
var node = document.documentElement.firstChild;
if (node.nodeType === Node.ELEMENT_NODE) {
console.log('该节点是元素节点');
}
nodeName
nodeName 属性返回节点的名称。
不同节点的 nodeName 属性值如下。
- 文档节点(document):
#document - 元素节点(element):大写 的标签名
- 属性节点(attr):属性的名称
- 文本节点(text):
#text - 文档片断节点(DocumentFragment):
#document-fragment - 文档类型节点(DocumentType):文档的类型
- 注释节点(Comment):
#comment
nodeValue
nodeValue 属性返回一个字符串,表示当前节点本身的文本值,该属性可读写。
只有文本节点(text)、注释节点(comment)和属性节点(attr)有文本值,因此这三类节点的 nodeValue 可以返回结果,其他类型的节点一律返回 null。
同样的,也只有这三类节点可以设置 nodeValue 属性的值,其他类型的节点设置无效。
如果 nodeValue的值为null,则对它赋值也不会有任何效果
input.value,本质:input 的 value 属性,读取 value 属性的属性值,所以前提是有 value 属性的标签
textContent
textContent 属性返回当前节点和它的 所有后代节点 的文本内容。
textContent 属性自动忽略当前节点内部的 HTML 标签,返回所有文本内容。
该属性是可读写的,设置该属性的值,会用一个新的文本节点,替换所有原来的子节点。它还有一个好处,就是自动对 HTML 标签转义。这很适合用于用户提供的内容。
document.getElementById('foo').textContent = '<p>GoodBye!</p>';
上面代码在插入文本时,会将 <p> 标签解释为文本,而不会当作标签处理。
对于文本节点(text)、注释节点(comment)和属性节点(attr),textContent 属性的值与 nodeValue 属性相同。对于其他类型的节点,该属性会将每个子节点(不包括注释节点)的内容连接在一起返回。如果一个节点没有子节点,则返回空字符串。
文档节点(document)和文档类型节点(doctype)的 textContent 属性为 null。如果要读取整个文档的内容,可以使用 document.documentElement.textContent。
baseURI
baseURI 属性返回一个字符串,表示当前网页的绝对路径。浏览器根据这个属性,计算网页上的相对路径的 URL。该属性为只读。
// 当前网页的网址为
// http://www.example.com/index.html
document.baseURI
// "http://www.example.com/index.html"
- 如果无法读到网页的 URL,
baseURI属性返回null。 - 该属性的值一般由当前网址的 URL(即
window.location属性)决定,但是可以使用 HTML 的<base>标签,改变该属性的值。
<base href="http://www.example.com/page.html">
设置了以后,baseURI 属性就返回 <base> 标签设置的值。
Node 间接查询属性
Node.nextSibling,Node.previousSibling
Node.nextSibling 属性返回紧跟在当前节点后面的第一个同级节点。如果当前节点后面没有同级节点,则返回 null。
注意,该属性还包括文本节点和注释节点(<!-- comment -->)。因此如果当前节点后面有空格,该属性会返回一个文本节点,内容为空格。
nextSibling 属性可以用来遍历所有子节点。
var el = document.getElementById('div1').firstChild;
while (el !== null) {
console.log(el.nodeName);
el = el.nextSibling;
}
上面代码遍历 div1 节点的所有子节点。
Node.parentNode
parentNode 属性返回当前节点的父节点。对于一个节点来说,它的父节点只可能是三种类型:元素节点(element)、文档节点(document)和文档片段节点(documentfragment)。 #
Node.parentElement
parentElement 属性返回当前节点的父元素节点。如果当前节点没有父节点,或者父节点类型不是元素节点,则返回 null。
由于父节点只可能是三种类型:元素节点、文档节点(document)和文档片段节点(documentfragment)。parentElement 属性相当于把后两种父节点都排除了。
node 上有一个返回 element 的方法, 感觉还是蛮奇怪的
Node.firstChild,lastChild
firstChild 属性返回当前节点的第一个子节点,如果当前节点没有子节点,则返回 null。
注意,firstChild 返回的除了元素节点,还可能是文本节点或注释节点。
Node.childNodes
childNodes 属性返回一个类似数组的对象(NodeList 集合),成员包括当前节点的所有子节点。
注意,除了元素节点,childNodes 属性的返回值还包括文本节点和注释节点。如果当前节点不包括任何子节点,则返回一个空的 NodeList 集合。
由于 NodeList 对象是一个动态集合,一旦子节点发生变化,立刻会反映在返回结果之中。
其他属性
Node.ownerDocument 属性返回当前节点所在的顶层文档对象,即 document 对象。
isConnected 属性返回一个布尔值,表示当前节点是否在文档之中。
var test = document.createElement('p');
test.isConnected // false
document.body.appendChild(test);
test.isConnected // true
上面代码中,test 节点是脚本生成的节点,没有插入文档之前,isConnected 属性返回 false,插入之后返回 true。
方法
normalize()
normalize 方法用于清理当前节点内部的所有文本节点(text)。它会去除空的文本节点,并且将毗邻的文本节点合并成一个,也就是说不存在空的文本节点,以及毗邻的文本节点。
var wrapper = document.createElement('div');
wrapper.appendChild(document.createTextNode('Part 1 '));
wrapper.appendChild(document.createTextNode('Part 2 '));
wrapper.Z.length // 2
wrapper.normalize();
wrapper.childNodes.length // 1
上面代码使用 normalize 方法之前,wrapper 节点有两个毗邻的文本子节点。使用 normalize 方法之后,两个文本子节点被合并成一个。
该方法是 Text.splitText 的逆方法,可以查看《Text 节点对象》一章,了解更多内容。
查看源代码时并不会捻成一坨
Node DOM 操作方法
Node.appendChild()
-
appendChild()方法接受一个节点对象作为参数,将其作为最后一个子节点,插入当前节点。该方法的返回值就是插入文档的子节点。 -
如果参数节点是 DOM 已经存在的节点,
appendChild()方法会将其从原来的位置,移动到新位置。 -
如果
appendChild()方法的参数是DocumentFragment节点,那么插入的是DocumentFragment的所有子节点,而不是DocumentFragment节点本身。返回值是一个空的DocumentFragment节点。 -
同一个 DOM 节点只能存在于一个父节点之下
var fragment = document.createDocumentFragment(), child; // 将原生节点拷贝到fragment while (child = root.firstChild) { fragment.appendChild(child); } console.log(fragment) console.log(root) // 没有子元素了
Node.insertBefore()
-
insertBefore方法用于将某个节点插入父节点内部的指定位置。var insertedNode = parentNode.insertBefore(newNode, referenceNode); -
insertBefore方法接受两个参数:- 第一个参数是所要插入的节点
newNode - 第二个参数是父节点
parentNode内部的一个子节点referenceNode。
- 第一个参数是所要插入的节点
-
newNode将插在referenceNode这个子节点的前面。返回值是插入的新节点newNode。 -
如果
insertBefore方法的第二个参数为null,则新节点将插在当前节点内部的最后位置,即变成最后一个子节点。var p = document.createElement('p'); document.body.insertBefore(p, null); -
上面代码中,
p将成为document.body的最后一个子节点。这也说明insertBefore的第二个参数不能省略。 -
注意,如果所要插入的节点是当前 DOM 现有的节点,则该节点将从原有的位置移除,插入新的位置。
-
由于不存在
insertAfter方法,如果新节点要插在父节点的某个子节点后面,可以用insertBefore方法结合nextSibling属性模拟。parent.insertBefore(s1, s2.nextSibling); -
上面代码中,
parent是父节点,s1是一个全新的节点,s2是可以将s1节点,插在s2节点的后面。如果s2是当前节点的最后一个子节点,则s2.nextSibling返回null,这时s1节点会插在当前节点的最后,变成当前节点的最后一个子节点,等于紧跟在s2的后面。 -
如果要插入的节点是
DocumentFragment类型,那么插入的将是DocumentFragment的所有子节点,而不是DocumentFragment节点本身。返回值将是一个空的DocumentFragment节点。
Node.removeChild()
removeChild方法接受一个子节点作为参数,用于从当前节点移除该子节点。返回值是移除的子节点。- 注意,这个方法是在
divA的父节点上调用的,不是在divA上调用的。 - 被移除的节点依然存在于内存之中,但不再是 DOM 的一部分。所以,一个节点移除以后,依然可以使用它,比如插入到另一个节点下面。
- 如果参数节点不是当前节点的子节点,
removeChild方法将报错。
Node.replaceChild()
-
replaceChild方法用于将一个新的节点,替换当前节点的某一个子节点。var replacedNode = parentNode.replaceChild(newChild, oldChild); -
上面代码中,
replaceChild方法接受两个参数,第一个参数newChild是用来替换的新节点,第二个参数oldChild是将要替换走的子节点。返回值是替换走的那个节点oldChild。
Node.hasChildNodes()
hasChildNodes方法返回一个布尔值,表示当前节点是否有子节点。- 注意,子节点包括所有类型的节点,并不仅仅是元素节点。哪怕节点只包含一个空格,
hasChildNodes方法也会返回true。 - 判断一个节点有没有子节点,有许多种方法,下面是其中的三种。
node.hasChildNodes()node.firstChild !== nullnode.childNodes && node.childNodes.length > 0
Node.cloneNode()
-
cloneNode方法用于克隆一个节点。它接受一个布尔值作为参数,表示是否同时克隆子节点。它的返回值是一个克隆出来的新节点。var cloneUL = document.querySelector('ul').cloneNode(true); -
该方法有一些使用注意点。
- 克隆一个节点,会拷贝该节点的所有属性,但是会丧失
addEventListener方法和on-属性(即node.onclick = fn),添加在这个节点上的事件回调函数。 - 该方法返回的节点不在文档之中,即没有任何父节点,必须使用诸如
Node.appendChild这样的方法添加到文档之中。 - 克隆一个节点之后,DOM 有可能出现两个有相同
id属性(即id="xxx")的网页元素,这时应该修改其中一个元素的id属性。如果原节点有name属性,可能也需要修改。
- 克隆一个节点,会拷贝该节点的所有属性,但是会丧失
其他方法
contains 方法返回一个布尔值,表示参数节点是否满足以下三个条件之一。
- 参数节点为当前节点。
- 参数节点为当前节点的子节点。
- 参数节点为当前节点的后代节点。
compareDocumentPosition 方法的用法,与 contains 方法完全一致,返回一个六个比特位的二进制值,表示参数节点与当前节点的关系。
isEqualNode 方法返回一个布尔值,用于检查两个节点是否相等。所谓相等的节点,指的是两个节点的类型相同、属性相同、子节点相同。
isSameNode 方法返回一个布尔值,表示两个节点是否为同一个节点。
getRootNode() 方法返回当前节点所在文档的根节点 document,与 ownerDocument 属性的作用相同。
注意
文本节点,CharacterData 抽象接口(abstract interface)代表 Node 对象包含的字符。这是一个抽象接口,意味着没有 CharacterData 类型的对象。 它是在其他接口中被实现的,如 Text、Comment 或 ProcessingInstruction 这些非抽象接口。
data 属性保存着文本值,没有 innerText 、 innerHTML 等属性
直接获取到文本节点,要想修改文本节点的值需要使用 data 属性
nodeValue 属性同样可以
NodeList 接口,HTMLCollection 接口
节点都是单个对象,有时需要一种数据结构,能够容纳多个节点。DOM 提供两种节点集合,用于容纳多个节点:NodeList 和 HTMLCollection。
这两种集合都属于接口规范。许多 DOM 属性和方法,返回的结果是 NodeList 实例或 HTMLCollection 实例。
主要区别是,NodeList 可以包含各种类型的节点,HTMLCollection 只能包含 HTML 元素节点。
NodeList 接口
NodeList 实例是一个类似数组的对象,它的成员是节点对象。通过以下方法可以得到 NodeList 实例。
Node.childNodesdocument.querySelectorAll()等节点搜索方法
NodeList 实例很像数组,可以使用 length 属性和 forEach 方法。但是,它不是数组,不能使用 pop 或 push 之类数组特有的方法。
forEach 方法是与普通类数组对象最大的不同
注意,NodeList 实例可能是动态集合,也可能是静态集合。所谓动态集合就是一个活的集合,DOM 删除或新增一个相关节点,都会立刻反映在 NodeList 实例。
目前,只有 Node.childNodes 返回的是一个动态集合,其他的 NodeList 都是静态集合
HTMLCollection 接口
HTMLCollection 是一个节点对象的集合,只能包含元素节点(element),不能包含其他类型的节点。它的返回值是一个类似数组的对象,但是与 NodeList 接口不同,HTMLCollection 没有 forEach 方法,只能使用 for 循环遍历。
返回 HTMLCollection 实例的,主要是一些 Document 对象的集合属性,比如
document.links、document.forms、document.images等ParentNode.children
HTMLCollection 实例都是动态集合,节点的变化会实时反映在集合中。
如果成员有 id 或 name 属性,还可以用这两个属性的值,在 HTMLCollection 实例上引用到这个成员。
ParentNode 接口,ChildNode 接口
节点对象除了继承 Node 接口以外,还会继承其他接口。ParentNode 接口表示当前节点是一个父节点,提供一些处理子节点的方法。ChildNode 接口表示当前节点是一个子节点,提供一些相关方法。
如果当前节点是父节点,就会继承 ParentNode 接口。由于只有元素节点(element)、文档节点(document)和文档片段节点(documentFragment)拥有子节点,因此只有这三类节点会继承 ParentNode 接口。
ParentNode 接口
Parent.children
children 属性返回一个 HTMLCollection 实例,成员是当前节点的所有 元素子节点。该属性只读。
注意,children 属性只包括元素子节点,不包括其他类型的子节点(比如文本子节点)。如果没有元素类型的子节点,返回值 HTMLCollection 实例的 length 属性为 0。
另外,HTMLCollection 是动态集合,会实时反映 DOM 的任何变化。
Element 接口也实现了该属性
Element.childElementCount 属性返回当前元素节点包含的子元素节点的个数,与 Element.children.length 的值相同。
Parent.firstElementChild,Parent.lastElementChild
firstElementChild 属性返回当前节点的第一个元素子节点。如果没有任何元素子节点,则返回 null。
Element 接口也实现了该属性
Parent.childElementCount
childElementCount 属性返回一个整数,表示当前节点的所有元素子节点的数目。如果不包含任何元素子节点,则返回 0。
Element 接口也实现了该属性
Parent.append(),Parent.prepend()
append 方法为当前节点追加一个或多个子节点,位置是最后一个元素子节点的后面。
该方法不仅可以添加元素子节点,还可以添加文本子节点。
注意,该方法没有返回值。
prepend 方法为当前节点追加一个或多个子节点,位置是第一个元素子节点的前面。它的用法与 append 方法完全一致,也是没有返回值。
与 Node.prototype.appendChild() 最大区别在于可以添加多个节点
ChildNode 接口
如果一个节点有父节点,那么该节点就继承了 ChildNode 接口。
ChildNode.remove()
remove 方法用于从父节点移除当前节点。
自杀
Element 接口也实现了该属性
推荐方式:子节点.parentNode.removeChild(子节点)
ChildNode.before(),ChildNode.after()
before 方法用于在当前节点的前面,插入一个或多个同级节点。两者拥有相同的父节点。
注意,该方法不仅可以插入元素节点,还可以插入文本节点。
ChildNode.replaceWith()
replaceWith 方法使用参数节点,替换当前节点。参数可以是元素节点,也可以是文本节点。
Document 节点
概述
document 节点对象代表整个文档,每张网页都有自己的 document 对象。window.document 属性就指向这个对象。只要浏览器开始载入 HTML 文档,该对象就存在了,可以直接使用。
document 对象有不同的办法可以获取。
- 正常的网页,直接使用
document或window.document。 iframe框架里面的网页,使用iframe节点的contentDocument属性。- Ajax 操作返回的文档,使用
XMLHttpRequest对象的responseXML属性。 - 内部节点的
ownerDocument属性。
document 对象继承了 EventTarget 接口、Node 接口、ParentNode 接口。这意味着,这些接口的方法都可以在 document 对象上调用。除此之外,document 对象还有很多自己的属性和方法。
属性
快捷方式属性
以下属性是指向文档内部的某个节点的快捷方式。
document.defaultView: document.defaultView 属性返回 document 对象所属的 window 对象。如果当前文档不属于 window 对象,该属性返回 null。
document.doctype:
- 对于 HTML 文档来说,
document对象一般有两个子节点。第一个子节点是document.doctype,指向<DOCTYPE>节点,即文档类型(Document Type Declaration,简写 DTD)节点。HTML 的文档类型节点,一般写成<!DOCTYPE html>。如果网页没有声明 DTD,该属性返回null。 document.firstChild通常就返回这个节点。
document.documentElement: document.documentElement 属性返回当前文档的根元素节点(root)。它通常是 document 节点的第二个子节点,紧跟在 document.doctype 节点后面。HTML 网页的该属性,一般是 <html> 节点。
document.body,document.head: document.body 属性指向 <body> 节点,document.head 属性指向 <head> 节点。这两个属性总是存在的,如果网页源码里面省略了 <head> 或 <body>,浏览器会自动创建。另外,这两个属性是可写的,如果改写它们的值,相当于移除所有子节点。
document.scrollingElement: document.scrollingElement 属性返回文档的滚动元素。也就是说,当文档整体滚动时,到底是哪个元素在滚动。 标准模式下,这个属性返回的文档的根元素 document.documentElement(即 <html>)。兼容(quirk)模式下,返回的是 <body> 元素,如果该元素不存在,返回 null。
document.activeElement: document.activeElement 属性返回获得当前焦点(focus)的 DOM 元素。通常,这个属性返回的是 <input>、<textarea>、<select> 等表单元素,如果当前没有焦点元素,返回 <body> 元素或 null。
document.fullscreenElement: document.fullscreenElement 属性返回当前以全屏状态展示的 DOM 元素。如果不是全屏状态,该属性返回 null。
if (document.fullscreenElement.nodeName == 'VIDEO') {
console.log('全屏播放视频');
}
上面代码中,通过 document.fullscreenElement 可以知道 <video> 元素有没有处在全屏状态,从而判断用户行为。
节点集合属性
DOM 直接查询, 以下属性返回一个 HTMLCollection 实例,表示文档内部特定元素的集合。这些集合都是动态的,原节点有任何变化,立刻会反映在集合中。
文档静态信息属性
document.documentURI,document.URL
document.documentURI 属性和 document.URL 属性都返回一个字符串,表示当前文档的网址。不同之处是它们继承自不同的接口,documentURI 继承自 Document 接口,可用于所有文档;URL 继承自 HTMLDocument 接口,只能用于 HTML 文档。
document.URL
// http://www.example.com/about
document.documentURI === document.URL
// true
如果文档的锚点(#anchor)变化,这两个属性都会跟着变化。
document.domain
document.domain 属性返回当前文档的域名,不包含协议和端口。比如,网页的网址是 http://www.example.com:80/hello.html,那么 document.domain 属性就等于 www.example.com。如果无法获取域名,该属性返回 null。
document.domain 基本上是一个只读属性,只有一种情况除外。次级域名的网页,可以把 document.domain 设为对应的上级域名。比如,当前域名是 a.sub.example.com,则 document.domain 属性可以设置为 sub.example.com,也可以设为 example.com。修改后,document.domain 相同的两个网页,可以读取对方的资源,比如设置的 Cookie。
另外,设置 document.domain 会导致端口被改成 null。因此,如果通过设置 document.domain 来进行通信,双方网页都必须设置这个值,才能保证端口相同。
document.location
Location 对象是浏览器提供的原生对象,提供 URL 相关的信息和操作方法。通过 window.location 和 document.location 属性,可以拿到这个对象。
document.lastModified
document.lastModified 属性返回一个字符串,表示当前文档最后修改的时间。不同浏览器的返回值,日期格式是不一样的。
注意,document.lastModified 属性的值是字符串,所以不能直接用来比较。Date.parse 方法将其转为 Date 实例,才能比较两个网页。
document.title
document.title 属性返回当前文档的标题。默认情况下,返回 <title> 节点的值。但是该属性是可写的,一旦被修改,就返回修改后的值。
document.characterSet
document.characterSet 属性返回当前文档的编码,比如 UTF-8、ISO-8859-1 等等。
document.referrer
document.referrer 属性返回一个字符串,表示当前文档的访问者来自哪里。
如果无法获取来源,或者用户直接键入网址而不是从其他网页点击进入,document.referrer 返回一个空字符串。
document.referrer 的值,总是与 HTTP 头信息的 Referer 字段保持一致。但是,document.referrer 的拼写有两个 r,而头信息的 Referer 字段只有一个 r。 #
document.dir
document.dir 返回一个字符串,表示文字方向。它只有两个可能的值:rtl 表示文字从右到左,阿拉伯文是这种方式;ltr 表示文字从左到右,包括英语和汉语在内的大多数文字采用这种方式。
document.compatMode
compatMode 属性返回浏览器处理文档的模式,可能的值为 BackCompat(向后兼容模式)和 CSS1Compat(严格模式)。
一般来说,如果网页代码的第一行设置了明确的 DOCTYPE(比如 <!doctype html>),document.compatMode 的值都为 CSS1Compat。
文档状态属性
document.hidden
document.hidden 属性返回一个布尔值,表示当前页面是否可见。如果窗口最小化、浏览器切换了 Tab,都会导致导致页面不可见,使得 document.hidden 返回 true。
这个属性是 Page Visibility API 引入的,一般都是配合这个 API 使用。
document.visibilityState
document.visibilityState 返回文档的可见状态。
visible:页面可见。注意,页面可能是部分可见,即不是焦点窗口,前面被其他窗口部分挡住了。hidden:页面不可见,有可能窗口最小化,或者浏览器切换到了另一个 Tab。prerender:页面处于正在渲染状态,对于用户来说,该页面不可见。unloaded:页面从内存里面卸载了。
这个属性可以用在页面加载时,防止加载某些资源;或者页面不可见时,停掉一些页面功能。
document.readyState
document.readyState 属性返回当前文档的状态,共有三种可能的值。
loading:加载 HTML 代码阶段(尚未完成解析)interactive:加载外部资源阶段complete:加载完成
这个属性变化的过程如下。
- 浏览器开始解析 HTML 文档,
document.readyState属性等于loading。 - 浏览器遇到 HTML 文档中的
<script>元素,并且没有async或defer属性,就暂停解析,开始执行脚本,这时document.readyState属性还是等于loading。 - HTML 文档解析完成,
document.readyState属性变成interactive。 - 浏览器等待图片、样式表、字体文件等外部资源加载完成,一旦全部加载完成,
document.readyState属性变成complete。
下面的代码用来检查网页是否加载成功。
// 基本检查
if (document.readyState === 'complete') {
// ...
}
// 轮询检查
var interval = setInterval(function() {
if (document.readyState === 'complete') {
clearInterval(interval);
// ...
}
}, 100);
另外,每次状态变化都会触发一个 readystatechange 事件。
document.cookie
document.cookie 属性用来操作浏览器 Cookie,详见《浏览器模型》部分的《Cookie》章节。
document.designMode
document.designMode 属性控制当前文档是否可编辑。该属性只有两个值 on 和 off,默认值为 off。一旦设为 on,用户就可以编辑整个文档的内容。
下面代码打开 iframe 元素内部文档的 designMode 属性,就能将其变为一个所见即所得的编辑器。
document.implementation
方法
document.open(),document.close()
document.open 方法清除当前文档所有内容,使得文档处于可写状态,供 document.write 方法写入内容。
document.close 方法用来关闭 document.open() 打开的文档。
document.open();
document.write('hello world');
document.close();
document.write(),document.writeln()
document.write 方法用于向当前文档写入内容。
在网页的首次渲染阶段,只要页面没有关闭写入(即没有执行 document.close()),document.write 写入的内容就会追加在已有内容的后面。
注意,document.write 会当作 HTML 代码解析,不会转义。
document.write('<p>hello world</p>');
如果页面已经解析完成(DOMContentLoaded 事件发生之后),再调用 write 方法,它会先调用 open 方法,擦除当前文档所有内容,然后再写入。
如果在页面渲染过程中调用 write 方法,并不会自动调用 open 方法。(可以理解成,open 方法已调用,但 close 方法还未调用。)
<html>
<body>
hello
<script type="text/javascript">
document.write("world")
</script>
</body>
</html>
document.write 是 JavaScript 语言标准化之前就存在的方法,现在完全有更符合标准的方法向文档写入内容(比如对 innerHTML 属性赋值)。所以,除了某些特殊情况,应该尽量避免使用 document.write 这个方法。
document.writeln 方法与 write 方法完全一致,除了会在输出内容的尾部添加换行符。
注意,writeln 方法添加的是 ASCII 码的换行符,渲染成 HTML 网页时不起作用,即在网页上显示不出换行。网页上的换行,必须显式写入 <br>。
elementFromPoint(),elementsFromPoint()
document.elementFromPoint 方法返回位于页面指定位置最上层的元素节点。
var element = document.elementFromPoint(50, 50);
上面代码选中在 (50, 50) 这个坐标位置的最上层的那个 HTML 元素。
elementFromPoint 方法的两个参数,依次是相对于当前视口左上角的横坐标和纵坐标,单位是像素。如果位于该位置的 HTML 元素不可返回(比如文本框的滚动条),则返回它的父元素(比如文本框)。如果坐标值无意义(比如负值或超过视口大小),则返回 null。
document.elementsFromPoint() 返回一个数组,成员是位于指定坐标(相对于视口)的所有元素。
caretPositionFromPoint()
createEvent()
document.createEvent 方法生成一个事件对象(Event 实例),该对象可以被 element.dispatchEvent 方法使用,触发指定事件。
var event = document.createEvent(type);
document.createEvent 方法的参数是事件类型,比如 UIEvents、MouseEvents、MutationEvents、HTMLEvents。
var event = document.createEvent('Event');
event.initEvent('build', true, true);
document.addEventListener('build', function (e) {
console.log(e.type); // "build"
}, false);
document.dispatchEvent(event);
上面代码新建了一个名为 build 的事件实例,然后触发该事件。
addEventListener(),removeEventListener(),dispatchEvent()
这三个方法用于处理 document 节点的事件。它们都继承自 EventTarget 接口,详细介绍参见《EventTarget 接口》一章。
hasFocus()
document.hasFocus 方法返回一个布尔值,表示当前文档之中是否有元素被激活或获得焦点。
var focused = document.hasFocus();
注意,有焦点的文档必定被激活(active),反之不成立,激活的文档未必有焦点。比如,用户点击按钮,从当前窗口跳出一个新窗口,该新窗口就是激活的,但是不拥有焦点。
Document DOM 操作方法
document.createElement()
document.createElement 方法用来生成元素节点,并返回该节点。
createElement 方法的参数为元素的标签名,即元素节点的 tagName 属性,对于 HTML 网页大小写不敏感,即参数为 div 或 DIV 返回的是同一种节点。
如果参数里面包含尖括号(即 < 和 >)会报错。
注意,document.createElement 的参数可以是自定义的标签名。
document.createTextNode()
document.createTextNode 方法用来生成文本节点(Text 实例),并返回该节点。它的参数是文本节点的内容。
这个方法可以确保返回的节点,被浏览器当作文本渲染,而不是当作 HTML 代码渲染。因此,可以用来展示用户的输入,避免 XSS 攻击。
var div = document.createElement('div');
div.appendChild(document.createTextNode('<span>Foo & bar</span>'));
console.log(div.innerHTML)
// <span>Foo & bar</span>
上面代码中,createTextNode 方法对大于号和小于号进行转义,从而保证即使用户输入的内容包含恶意代码,也能正确显示。
需要注意的是,该方法不对单引号和双引号转义,所以不能用来对 HTML 属性赋值。
function escapeHtml(str) {
var div = document.createElement('div');
div.appendChild(document.createTextNode(str));
return div.innerHTML;
};
var userWebsite = '" onmouseover="alert(\'derp\')" "';
var profileLink = '<a href="' + escapeHtml(userWebsite) + '">Bob</a>';
var div = document.getElementById('target');
div.innerHTML = profileLink;
// <a href="" onmouseover="alert('derp')" "">Bob</a>
上面代码中,由于 createTextNode 方法不转义双引号,导致 onmouseover 方法被注入了代码。
document.createAttribute()
document.createAttribute 方法生成一个新的属性节点(Attr 实例),并返回它。
var attribute = document.createAttribute(name);
document.createAttribute 方法的参数 name,是属性的名称。
document.createComment()
createComment() 方法用来创建并返回一个注释节点.
var commentNode = document.createComment(data)
参数: data 是一个字符串,包含了注释的内容.
document.createDocumentFragment()
document.createDocumentFragment 方法生成一个空的文档片段对象(DocumentFragment 实例)。
var docFragment = document.createDocumentFragment();
DocumentFragment 是一个存在于内存的 DOM 片段,不属于当前文档,常常用来生成一段较复杂的 DOM 结构,然后再插入当前文档。这样做的好处在于,因为 DocumentFragment 不属于当前文档,对它的任何改动,都不会引发网页的重新渲染,比直接修改当前文档的 DOM 有更好的性能表现。
其他方法
adoptNode(),importNode() #
createNodeIterator() #
createTreeWalker() #
execCommand(),queryCommandSupported(),queryCommandEnabled() #
getSelection() #
Element 节点
Element 节点对象对应网页的 HTML 元素。每一个 HTML 元素,在 DOM 树上都会转化成一个 Element 节点对象(以下简称元素节点)。
元素节点的 nodeType 属性都是 1。
Element 对象继承了 Node 接口,因此 Node 的属性和方法在 Element 对象都存在。此外,不同的 HTML 元素对应的元素节点是不一样的,浏览器使用不同的构造函数,生成不同的元素节点,比如 <a> 元素的节点对象由 HTMLAnchorElement 构造函数生成,<button> 元素的节点对象由 HTMLButtonElement 构造函数生成。因此,元素节点不是一种对象,而是一组对象,这些对象除了继承 Element 的属性和方法,还有各自构造函数的属性和方法。
实例属性
元素特性的相关属性
Element.id属性返回指定元素的id属性,该属性可读写。Element.tagName属性返回指定元素的大写标签名,与nodeName属性的值相等。Element.dir属性用于读写当前元素的文字方向,可能是从左到右("ltr"),也可能是从右到左("rtl")。Element.accessKey属性用于读写分配给当前元素的快捷键。Element.draggable属性返回一个布尔值,表示当前元素是否可拖动。该属性可读写。Element.lang属性返回当前元素的语言设置。该属性可读写。Element.title属性用来读写当前元素的 HTML 属性title。该属性通常用来指定,鼠标悬浮时弹出的文字提示框。
Element.tabIndex
Element.tabIndex属性返回一个整数,表示当前元素在 Tab 键遍历时的顺序。该属性可读写。tabIndex属性值如果是负值(通常是-1),则 Tab 键不会遍历到该元素。如果是正整数,则按照顺序,从小到大遍历。如果两个元素的tabIndex属性的正整数值相同,则按照出现的顺序遍历。遍历完所有tabIndex为正整数的元素以后,再遍历所有tabIndex等于0、或者属性值是非法值、或者没有tabIndex属性的元素,顺序为它们在网页中出现的顺序。
元素状态的相关属性
Element.contentEditable,Element.isContentEditable
Element.hidden
Element.hidden属性返回一个布尔值,表示当前元素的hidden属性,用来控制当前元素是否可见。该属性可读写。- 注意,该属性与 CSS 设置是互相独立的。CSS 对这个元素可见性的设置,
Element.hidden并不能反映出来。也就是说,这个属性并不能用来判断当前元素的实际可见性。 - CSS 的设置高于
Element.hidden。如果 CSS 指定了该元素不可见(display: none)或可见(display: hidden),那么Element.hidden并不能改变该元素实际的可见性。换言之,这个属性只在 CSS 没有明确设定当前元素的可见性时才有效。
className,classList
className 属性用来读写当前元素节点的 class 属性。它的值是一个字符串,每个 class 之间用空格分割。
classList 属性返回一个类似数组的对象,当前元素节点的每个 class 就是这个对象的一个成员。
classList 对象有下列方法
add():增加一个 class。remove():移除一个 class。contains():检查当前元素是否包含某个 class。toggle():将某个 class 移入或移出当前元素。item():返回指定索引位置的 class。toString():将 class 的列表转为字符串。
innerHTML
Element.innerHTML 属性返回一个字符串,等同于该元素 包含的 所有 HTML 代码。该属性可读写,常用来设置某个节点的内容。它能改写所有元素节点的内容,包括 <HTML> 和 <body> 元素。
- 如果将
innerHTML属性设为空,等于删除所有它包含的所有节点。 - 如果插入的文本包含 HTML 标签,会被解析成为节点对象插入 DOM。注意,如果文本之中含有
<script>标签,虽然可以生成script节点,但是插入的代码不会执行。
innerHTML 还是有安全风险的。
- 因此为了安全考虑,如果插入的是文本,最好用
textContent属性代替innerHTML。 - 使用
+=语法的时候,因为 innerHTML 会整个重写,会导致绑定的事件消失 @@@
这两个属性并没有在 DOM 标准定义,但是大部分浏览器都支持这两个属性
对于自结束标签,比如 <input/>,是没有办法获取到 值 的,这时 innerHTML 没有意义
innerText
只能获取文本,拿不到标签名
outerHTML
Element.outerHTML 属性返回一个字符串,表示当前元素节点的所有 HTML 代码,包括该元素本身和所有子元素。
outerHTML 属性是可读写的,对它进行赋值,等于替换掉当前元素。
注意,如果一个节点没有父节点,设置 outerHTML 属性会报错。
实例方法
Element.focus(),Element.blur()
Element.focus方法用于将当前页面的焦点,转移到指定元素上。Element.blur方法用于将焦点从当前元素移除。
Element.scrollIntoView()
事件相关方法
以下三个方法与 Element 节点的事件相关。这些方法都继承自 EventTarget 接口,详见相关章节。
Element.addEventListener():添加事件的回调函数Element.removeEventListener():移除事件监听函数Element.dispatchEvent():触发事件
element.addEventListener('click', listener, false);
element.removeEventListener('click', listener, false);
var event = new Event('click');
element.dispatchEvent(event);
Element.click()
Element 节点 Attr 操作
HTML 元素包括标签名和若干个键值对,这个键值对就称为“属性”(attribute)。
<a id="test" href="http://www.example.com">
链接
</a>
上面代码中,a 元素包括两个属性:id 属性和 href 属性。
属性本身是一个对象(Attr 对象),但是实际上,这个对象极少使用。一般都是通过元素节点对象(HTMlElement 对象)来操作属性。本章介绍如何操作这些属性。
Element.attributes
元素对象有一个 attributes 属性,返回一个类似数组的动态对象,成员是该元素标签的所有属性节点对象,属性的实时变化都会反映在这个节点对象上。其他类型的节点对象,虽然也有 attributes 属性,但返回的都是 null,因此可以把这个属性视为元素对象独有的。
单个属性可以通过序号引用,也可以通过属性名引用。
document.body.attributes[0]
document.body.attributes.bgcolor
document.body.attributes['ONLOAD']
注意,上面代码的三种方法,返回的都是属性节点对象,而不是属性值。
属性节点对象有 name 和 value 属性,对应该属性的属性名和属性值,等同于 nodeName 属性和 nodeValue 属性。
// HTML代码为
// <div id="mydiv">
var n = document.getElementById('mydiv');
n.attributes[0].name // "id"
n.attributes[0].nodeName // "id"
n.attributes[0].value // "mydiv"
n.attributes[0].nodeValue // "mydiv"
元素的标准属性
HTML 元素的标准属性(即在标准中定义的属性),会自动成为元素节点对象的属性。
HTML 元素的属性名是大小写不敏感的,但是 JavaScript 对象的属性名是大小写敏感的。转换规则是,转为 JavaScript 属性名时,一律采用小写。如果属性名包括多个单词,则采用骆驼拼写法,即从第二个单词开始,每个单词的首字母采用大写,比如 onClick。
有些 HTML 属性名是 JavaScript 的保留字,转为 JavaScript 属性时,必须改名。主要是以下两个。
for属性改为htmlForclass属性改为className
另外,HTML 属性值一般都是字符串,但是 JavaScript 属性会自动转换类型。比如,将字符串 true 转为布尔值,将 onClick 的值转为一个函数,将 style 属性的值转为一个 CSSStyleDeclaration 对象。因此,可以对这些属性赋予各种类型的值。
属性操作的标准方法
概述
元素节点提供六个方法,用来操作属性。
getAttribute():读取某个属性的值getAttributeNames():返回当前元素的所有属性名setAttribute():写入属性值hasAttribute():某个属性是否存在hasAttributes():当前元素是否有属性removeAttribute():删除属性
注意
- 适用性:这六个方法对所有属性(包括用户自定义的属性)都适用。
- 返回值:
getAttribute()只返回字符串,不会返回其他类型的值。 - 属性名:这些方法只接受属性的标准名称,不用改写保留字,比如
for和class都可以直接使用。另外,这些方法对于属性名是大小写不敏感的。
Element.getAttribute()
Element.getAttribute 方法返回当前元素节点的指定属性。如果指定属性不存在,则返回 null。
Element.getAttributeNames()
Element.getAttributeNames() 返回一个数组,成员是当前元素的所有属性的名字。如果当前元素没有任何属性,则返回一个空数组。使用 Element.attributes 属性,也可以拿到同样的结果,唯一的区别是它返回的是类似数组的对象。
setAttribute()
Element.setAttribute 方法用于为当前元素节点新增属性。如果同名属性已存在,则相当于编辑已存在的属性。该方法没有返回值。
这里有两个地方需要注意,首先,属性值总是字符串,其他类型的值会自动转成字符串,比如布尔值 true 就会变成字符串 true;其次,上例的 disable 属性是一个布尔属性,对于 <button> 元素来说,这个属性不需要属性值,只要设置了就总是会生效,因此 setAttribute 方法里面可以将 disabled 属性设成任意值。
hasAttribute()
Element.hasAttribute 方法返回一个布尔值,表示当前元素节点是否包含指定属性。
hasAttributes()
Element.hasAttributes 方法返回一个布尔值,表示当前元素是否有属性,如果没有任何属性,就返回 false,否则返回 true。
removeAttribute()
Element.removeAttribute 方法移除指定属性。该方法没有返回值。
Dataset 属性
有时,需要在 HTML 元素上附加数据,供 JavaScript 脚本使用。一种解决方法是自定义属性。
这种方法虽然可以达到目的,但是会使得 HTML 元素的属性不符合标准,导致网页代码通不过校验。
更好的解决方法是,使用标准提供的 data-* 属性。
<div id="mydiv" data-foo="bar">
然后,使用元素节点对象的 dataset 属性,它指向一个对象,可以用来操作 HTML 元素标签的 data-* 属性。
var n = document.getElementById('mydiv');
n.dataset.foo // bar
n.dataset.foo = 'baz'
上面代码中,通过 dataset.foo 读写 data-foo 属性。
删除一个 data-* 属性,可以直接使用 delete 命令。
delete document.getElementById('myDiv').dataset.foo;
除了 dataset 属性,也可以用 getAttribute('data-foo')、removeAttribute('data-foo')、setAttribute('data-foo')、hasAttribute('data-foo') 等方法操作 data-* 属性。
dataset 上面的各个属性返回都是字符串。
HTML 代码中,data- 属性的属性名,只能包含英文字母、数字、连词线(-)、点(.)、冒号(:)和下划线(_)。它们转成 JavaScript 对应的 dataset 属性名,规则如下:
- 开头的
data-会省略。 - 如果连词线后面跟了一个英文字母,那么连词线会取消,该字母变成大写。
- 其他字符不变。
因此,data-abc-def 对应 dataset.abcDef,data-abc-1 对应 dataset["abc-1"]。
除了使用 dataset 读写 data- 属性,也可以使用 Element.getAttribute() 和 Element.setAttribute(),通过完整的属性名读写这些属性。
注意,data- 后面的属性名有限制,只能包含字母、数字、连词线(-)、点(.)、冒号(:)和下划线(_)。而且,属性名不应该使用 A 到 Z 的大写字母,比如不能有 data-helloWorld 这样的属性名,而要写成 data-hello-world。
转成 dataset 的键名时,连词线后面如果跟着一个小写字母,那么连词线会被移除,该小写字母转为大写字母,其他字符不变。反过来,dataset 的键名转成属性名时,所有大写字母都会被转成连词线 + 该字母的小写形式,其他字符不变。比如,dataset.helloWorld 会转成 data-hello-world。
Attribute & Property
Demo
<input type="checkbox" checked="checked" qhf="qhf"/>
<input type="checkbox" checked="true" />
<input type="checkbox" checked="false" />
<input type="checkbox" checked="" />
<input type="checkbox" checked=null />
<input type="checkbox" checked=undefined />
<input type="checkbox" checked=0 />
<input type="checkbox" checked />
<input type="checkbox" checked="daudhauikdhiuawshd" />
<input type="checkbox" />
结果:
原因:
- html 有自己的渲染规则(浏览器决定),它既不是 css 也不是 js,本身就是一套技术
- 只要写了
checked无论如何都会被选中 - html 预定义属性: checked
- html 自定义属性:qhf
Attribute 和 Property
html 标签的预定义和自定义属性我们统称为 attribute
attributes 属性下,有着所有的预定义和自定义属性
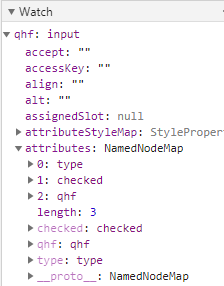
js 原生对象的直接属性,我们统称为 property
布尔值属性和非布尔值属性
property 的属性值为布尔类型的 我们统称为布尔值属性
property 的属性值为非布尔类型的 我们统称为非布尔值属性
Attribute 和 Property 的同步关系
非布尔值属性: 实时同步
//修改attribute
qhf.setAttribute("name","qhf1")
qhf.setAttribute("name","qhf2")
qhf.setAttribute("name","qhf3")
//修改property
qhf.name="qhf4";
qhf.name="qhf5";
qhf.name="qhf6";
布尔值属性:
- 修改 property,attribute 不会同步,
- 在没有动过 property 的情况下,修改 attribute,property 会同步
- 在动过 property 的情况下 ,修改 attribute,property 不会同步
用户操作的是 Property
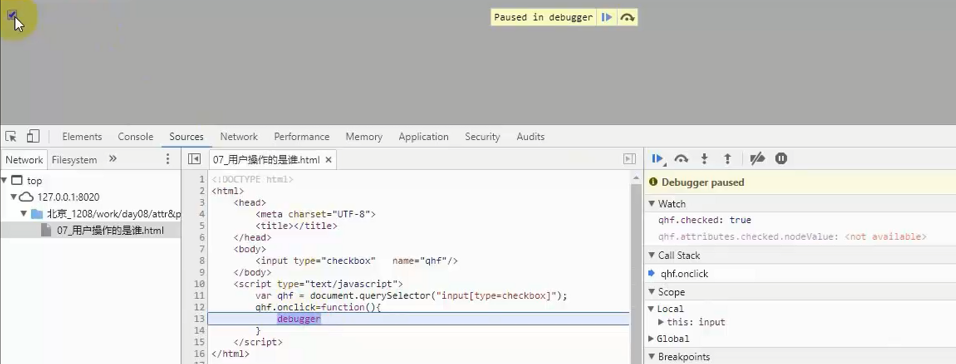
点击打钩之后,只有 property 改变了
浏览器认的是 Property
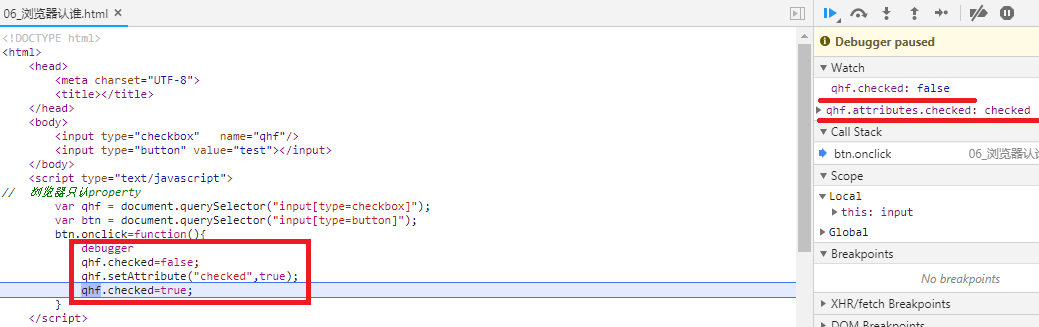
先设置一下 property,确保修改 attribute 时,property 不会同步,然后设置 attribute,发现 input 的勾,没有打上,说明浏览器判断 true or false ,跟的是 property
结论
在原生 JS 中,别用setAttribute() 即可,直接读取 prop
想要控制 attr 直接使用 prop 不用理会 html 的属性,比如控制 input 的 disabled
input.disabled = !disabled
DOM 查询
直接查询
主要是 Document 节点的方法,都是 只读 的
querySelector(),querySelectorAll()
document.querySelector 方法接受一个 CSS 选择器作为参数,返回匹配该选择器的元素节点。如果有多个节点满足匹配条件,则返回第一个匹配的节点。如果没有发现匹配的节点,则返回 null。
document.querySelectorAll 方法与 querySelector 用法类似,区别是返回一个 NodeList 对象,包含所有匹配给定选择器的节点。
但是,它们不支持 CSS 伪元素的选择器(比如 :first-line 和 :first-letter)和伪类的选择器(比如 :link 和 :visited),即无法选中伪元素和伪类。
最后,这两个方法除了定义在 document 对象上,还定义在元素节点上,即在元素节点上也可以调用。
getElementsByTagName()
document.getElementsByTagName 方法搜索 HTML 标签名,返回符合条件的元素。它的返回值是一个类似数组对象(HTMLCollection 实例),可以实时反映 HTML 文档的变化。如果没有任何匹配的元素,就返回一个空集。
HTML 标签名是大小写不敏感的,因此 getElementsByTagName 方法也是大小写不敏感的。另外,返回结果中,各个成员的顺序就是它们在文档中出现的顺序。
注意,元素节点本身也定义了 getElementsByTagName 方法,返回该元素的后代元素中符合条件的元素。也就是说,这个方法不仅可以在 document 对象上调用,也可以在任何元素节点上调用。
getElementsByClassName()
document.getElementsByClassName 方法返回一个类似数组的对象(HTMLCollection 实例),包括了所有 class 名字符合指定条件的元素,元素的变化实时反映在返回结果中。
由于 class 是保留字,所以 JavaScript 一律使用 className 表示 CSS 的 class。
参数可以是多个 class,它们之间使用空格分隔。
var elements = document.getElementsByClassName('foo bar');
注意,正常模式下,CSS 的 class 是大小写敏感的。(quirks mode 下,大小写不敏感。)
与 getElementsByTagName 方法一样,getElementsByClassName 方法不仅可以在 document 对象上调用,也可以在任何元素节点上调用。
getElementsByName()
document.getElementsByName 方法用于选择拥有 name 属性的 HTML 元素(比如 <form>、<radio>、<img>、<frame>、<embed> 和 <object> 等),返回一个类似数组的的对象(NodeList 实例),因为 name 属性相同的元素可能不止一个。
注意:同辈分的兄弟中,唯一一个 NodeList 实例
getElementById()
document.getElementById 方法返回匹配指定 id 属性的元素节点。如果没有发现匹配的节点,则返回 null。
注意,该方法的参数是大小写敏感的。比如,如果某个节点的 id 属性是 main,那么 document.getElementById('Main') 将返回 null。
另外,这个方法只能在 document 对象上使用,不能在其他元素节点上使用。 #
Document 节点集合属性
以下属性返回一个 HTMLCollection 实例,表示文档内部特定元素的集合。这些集合都是动态的,原节点有任何变化,立刻会反映在集合中。
document.all
-
document.all,获取页面中的所有元素,类似于document.getElementsByTagName("*")var all = document.getElementsByTagName("*") var ALL = document.all console.log(all) console.log(ALL) console.log(typeof all) //object console.log(typeof ALL) //underfine
document.links
document.links属性返回当前文档所有设定了href属性的<a>及<area>节点。
document.forms
-
document.forms属性返回所有<form>表单节点。var selectForm = document.forms[0]; -
上面代码获取文档第一个表单。
-
除了使用位置序号,
id属性和name属性也可以用来引用表单。/* HTML 代码如下 <form name="foo" id="bar"></form> */ document.forms[0] === document.forms.foo // true document.forms.bar === document.forms.foo // true
document.images
document.images属性返回页面所有<img>图片节点。
document.embeds,document.plugins
document.embeds属性和document.plugins属性,都返回所有<embed>节点。
document.scripts
document.scripts属性返回所有<script>节点。
document.styleSheets
document.styleSheets属性返回文档内嵌或引入的样式表集合,详细介绍请看《CSS 对象模型》一章。
小结
- 除了
document.styleSheets,以上的集合属性返回的都是HTMLCollection实例。
Element.closest()
Element.closest 方法接受一个 CSS 选择器作为参数,返回匹配该选择器的、最接近当前节点的一个祖先节点(包括当前节点本身)。如果没有任何节点匹配 CSS 选择器,则返回 null。
// HTML 代码如下
// <article>
// <div id="div-01">Here is div-01
// <div id="div-02">Here is div-02
// <div id="div-03">Here is div-03</div>
// </div>
// </div>
// </article>
var div03 = document.getElementById('div-03');
// div-03 最近的祖先节点
div03.closest("#div-02") // div-02
div03.closest("div div") // div-03
div03.closest("article > div") //div-01
div03.closest(":not(div)") // article
上面代码中,由于 closest 方法将当前节点也考虑在内,所以第二个 closest 方法返回 div-03。
间接查询
Element.nextElementSibling,Element.previousElementSibling
DOM 操作
DOM 读写标签属性
Node.className,因为 class 是关键字
Text 节点
概念
文本节点(Text)代表元素节点(Element)和属性节点(Attribute)的文本内容。如果一个节点只包含一段文本,那么它就有一个文本子节点,代表该节点的文本内容。
通常我们使用父节点的 firstChild、nextSibling 等属性获取文本节点,或者使用 Document 节点的 createTextNode 方法创造一个文本节点。
// 获取文本节点
var textNode = document.querySelector('p').firstChild;
// 创造文本节点
var textNode = document.createTextNode('Hi');
document.querySelector('div').appendChild(textNode);
浏览器原生提供一个 Text 构造函数。它返回一个文本节点实例。它的参数就是该文本节点的文本内容。
// 空字符串
var text1 = new Text();
// 非空字符串
var text2 = new Text('This is a text node');
注意,由于空格也是一个字符,所以哪怕只有一个空格,也会形成文本节点。比如,<p> </p> 包含一个空格,它的子节点就是一个文本节点。
文本节点除了继承 Node 接口,还继承了 CharacterData 接口。Node 接口的属性和方法请参考《Node 接口》一章,这里不再重复介绍了,以下的属性和方法大部分来自 CharacterData 接口。
Text 节点的属性
Data
data 属性等同于 nodeValue 属性,用来设置或读取文本节点的内容。
// 读取文本内容
document.querySelector('p').firstChild.data
// 等同于
document.querySelector('p').firstChild.nodeValue
// 设置文本内容
document.querySelector('p').firstChild.data = 'Hello World';
注意:文本节点没有 innerText 或者 innerHTML 属性,因为这是 Elment 接口的属性
wholeText
wholeText 属性将当前文本节点与毗邻的文本节点,作为一个整体返回。大多数情况下,wholeText 属性的返回值,与 data 属性和 textContent 属性相同。但是,某些特殊情况会有差异。
Length
length 属性返回当前文本节点的文本长度。
nextElementSibling,previousElementSibling
Element 接口也有同名属性,但是注意 Text 接口并没有继承 Element 接口
Text 节点的方法
appendData(),deleteData(),insertData(),replaceData(),subStringData()
以下 5 个方法都是编辑 Text 节点文本内容的方法。
appendData():在Text节点尾部追加字符串。deleteData():删除Text节点内部的子字符串,第一个参数为子字符串开始位置,第二个参数为子字符串长度。insertData():在Text节点插入字符串,第一个参数为插入位置,第二个参数为插入的子字符串。replaceData():用于替换文本,第一个参数为替换开始位置,第二个参数为需要被替换掉的长度,第三个参数为新加入的字符串。subStringData():用于获取子字符串,第一个参数为子字符串在Text节点中的开始位置,第二个参数为子字符串长度。
// HTML 代码为
// <p>Hello World</p>
var pElementText = document.querySelector('p').firstChild;
pElementText.appendData('!');
// 页面显示 Hello World!
pElementText.deleteData(7, 5);
// 页面显示 Hello W
pElementText.insertData(7, 'Hello ');
// 页面显示 Hello WHello
pElementText.replaceData(7, 5, 'World');
// 页面显示 Hello WWorld
pElementText.substringData(7, 10);
// 页面显示不变,返回"World "
remove()
ChildNode 接口有同名方法,但是 Text 接口并没有继承
splitText()
splitText 方法将 Text 节点一分为二,变成两个毗邻的 Text 节点。它的参数就是分割位置(从零开始),分割到该位置的字符前结束。如果分割位置不存在,将报错。
分割后,该方法返回分割位置后方的字符串,而原 Text 节点变成只包含分割位置前方的字符串。
// html 代码为 <p id="p">foobar</p>
var p = document.getElementById('p');
var textnode = p.firstChild;
var newText = textnode.splitText(3);
newText // "bar"
textnode // "foo"
父元素节点的 normalize 方法可以将毗邻的两个 Text 节点合并。
接上面的例子,文本节点的 splitText 方法将一个 Text 节点分割成两个,父元素的 normalize 方法可以实现逆操作,将它们合并。
p.childNodes.length // 2
// 将毗邻的两个 Text 节点合并
p.normalize();
p.childNodes.length // 1
DocumentFragment 节点
概述
DocumentFragment 节点代表一个文档的片段,本身就是一个完整的 DOM 树形结构。它没有父节点,parentNode 返回 null,但是可以插入任意数量的子节点。它不属于当前文档,操作 DocumentFragment 节点,要比直接操作 DOM 树快得多。
它一般用于构建一个 DOM 结构,然后插入当前文档。document.createDocumentFragment 方法,以及浏览器原生的 DocumentFragment 构造函数,可以创建一个空的 DocumentFragment 节点。然后再使用其他 DOM 方法,向其添加子节点。
var docFrag = document.createDocumentFragment();
// 等同于
var docFrag = new DocumentFragment();
var li = document.createElement('li');
li.textContent = 'Hello World';
docFrag.appendChild(li);
document.querySelector('ul').appendChild(docFrag);
上面代码创建了一个 DocumentFragment 节点,然后将一个 li 节点添加在它里面,最后将 DocumentFragment 节点移动到原文档。
注意,DocumentFragment 节点本身不能被插入当前文档。当它作为 appendChild()、insertBefore()、replaceChild() 等方法的参数时,是它的所有子节点插入当前文档,而不是它自身。一旦 DocumentFragment 节点被添加进当前文档,它自身就变成了空节点(textContent 属性为空字符串),可以被再次使用。如果想要保存 DocumentFragment 节点的内容,可以使用 cloneNode 方法。
document
.querySelector('ul')
.appendChild(docFrag.cloneNode(true));
上面这样添加 DocumentFragment 节点进入当前文档,不会清空 DocumentFragment 节点。
下面是一个例子,使用 DocumentFragment 反转一个指定节点的所有子节点的顺序。
function reverse(n) {
var f = document.createDocumentFragment();
while(n.lastChild) f.appendChild(n.lastChild);
n.appendChild(f);
}
DocumentFragment 节点对象没有自己的属性和方法,全部继承自 Node 节点和 ParentNode 接口。也就是说,DocumentFragment 节点比 Node 节点多出以下四个属性。
children:返回一个动态的HTMLCollection集合对象,包括当前DocumentFragment对象的所有子元素节点。firstElementChild:返回当前DocumentFragment对象的第一个子元素节点,如果没有则返回null。lastElementChild:返回当前DocumentFragment对象的最后一个子元素节点,如果没有则返回null。childElementCount:返回当前DocumentFragment对象的所有子元素数量。
Image
**Image()**函数将会创建一个新的 HTMLImageElement 实例。
它的功能等价于 document.createElement('img')
语法
Image(width, height)
参数
- width 图片的宽度 (即
width属性). - height 图片的高度 (即
height属性).
示例
var myImage = new Image(100, 200);
myImage.src = 'picture.jpg';
document.body.appendChild(myImage);
// 相当于
<img width="100" height="200" src="picture.jpg">
https://developer.mozilla.org/zh-CN/docs/Web/API/HTMLImageElement/Image
注意
- 无论构造函数中指定的大小是多少,都会加载整个位图. 如果在构造时指定了尺寸信息,那么将会反应在实例的
HTMLImageElement.width和HTMLImageElement.height属性上。图像自身的 CSS 像素值将会反应在HTMLImageElement.naturalWidth和HTMLImageElement.naturalHeight属性。如果没有指定值,那么两个属性的值相同
FAQ
innerHTML、innerText、textContent
innerText & textContent
innerText 是 Element 接口, textContent 是 Node 接口
实际上是 innerText 会保留块级元素的换行特性,以换行符形式呈现。在 HTML 中,如果 white-space 不是 pre 或 pre-wrap 则会表现为空格。
display:none 元素是无法使用 innerText 获取的,但是 textContent 却可以,无论元素隐藏与否。
此外,由于 innerText 属性值的获取会考虑 CSS 样式,因此读取 innerText 的值将触发回流以确保计算出的样式是最新的,而回流在计算上很昂贵,会降低性能,因此应尽可能避免回流。而 textContent 只是单纯读取文本内容,因此性能更高。
innerText 由于存在诸多特别的特性、以及兼容性差异,以及性能方面问题,以及实际开发的需求的考量,不推荐使用,推荐使用 textContent 获取文本内容。
另外,如果你要在一个 DOM 元素中改变文字内容,推荐使用 textContent,而不是 innerHTML,性能会更高一点。
小tips: JS DOM innerText和textContent的区别 « 张鑫旭-鑫空间-鑫生活