gpt-plugin
其实最重要的还是看官方的文档, 以及自己上手制作
简单理解
ChatGPT 的每个插件都包含一个 manifest 文件,除了插件开发者提供的各类 meta 信息,这个文件中还包含了 OpenAI 官方嵌入的一段面向 GPT 模型的描述
就是这段描述让 ChatGPT 知道什么时候该使用插件,它对用户是不可见的,作用在于告诉模型如何根据用户的输入/问题判断何时调用该插件,并且把 API 的返回结果整合到 ChatGPT 的回答中。
Speak 插件
比如,一个叫做 Speak 的插件,这是一款用于学习多种外语口语的应用(有同名软件)。
Learn how to say anything in another language with Speak, your AI-powered language tutor.
(跟着 Speak 学习如何使用另外一种语言说你想说。)
小哥破解了它在 ChatGPT 中的描述文件
仔细看能发现这段描述其实就是写给 ChatGPT 的 prompt,通过详细的 prompt 告诉模型什么时候调用这个插件,比如
“当用户要求语言导师或外语对话伙伴时,立即调用 Speak 插件”;
“当用户提出关于如何使用另一种语言说某个东西时的问题时,使用“translate”API 来回答。只有当用户提供了要翻译的具体短语或单词时,才使用此端点。如果问题可以更通俗或更高级的解答,则使用“explainTask”API 来回答。“
此外,prompt 还通过提供具体的例子说明什么场合应该使用哪些特定的 API。
FAQ
目前的 Ai 伙伴是怎么实现召回功能的?
之前准备写一篇专门介绍上述工具类的原理介绍(其实 ChatGPT 的 插件——chatgpt-retrieval-plugin),但是后来查看了几个项目的源码之后发现,这类工具的主要原理其实比较直观:
- 解析相关输入为文本
- 将文本分句后获取句子的 embedding(这一步目前处理的处理方式大都是根据长度截断)并存储至数据库
- 用户输入转换为 embedding,并在数据库中召回相关性最高的句子集合
- 将召回的句子与用户输入句子组装为 ChaptGPT 的输入,获取输出
上述思路虽然直观,但要获取更好的结果,其实除了第三步,其余每一步都有优化的空间:
- 文本解析可以针对不同类型的数据针对性解析
- 文本分句方式可以采取特殊标点进行分句,同时句子 embedding 也有很多可选生成方法
- 召回的句子与用户输入句子组装为 ChaptGPT 的输入,结合任务特定的 prompt,获取更适合任务的输出
具体流程图可以参考 gpt-langchain-pdf[7]:
gpt-langchain-pdf
查看@madawei2699 大佬写的 ChatGPT 应用开发小记
简单理解二
作者:天地会珠海分舵
链接:https://www.zhihu.com/question/594369824/answer/3027479751
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
先抄题吧,ChatGPT plugin 的插件功能是如何实现的?
从官方文档可以看到,插件其实说白了就是个远程 api 调用。
我们都知道 ChatGPT 是个 语言模型,擅长的是根据前文的输入来预测下一个字应该输出什么,但是无法联网,也不擅长数学等。而插件的作用就是去补全 ChatGPT 的这些短板
比如用户给 ChatGPT 一个 Prompt
今天 500 美元可以换多少人民币?
如果没有插件的话,ChatGPT 大概率会告诉你它无法联网之类云云,以下是 gpt-3.5 的一个回复
由于 外汇汇率 会不断波动,因此我无法提供一个准确的答案,但您可以使用 搜索引擎 来查找最新的汇率转换器来进行计算。例如,您可以在搜索引擎中输入“500 美元兑换人民币”来获取最新的汇率转换结果。
那这时候就需要 ChatGPT Plugin 登场了。
假如我们有个算汇率的 ChatGPT Plugin,比如就叫做 Currency Converter,那么上面的问题丢给 ChatGPT 后,它大概会这样去做:
- 要去算汇率? 这不是我我擅长的,我需要找个人来帮我干这事情才行
- 当前发送请求这个账号是否有启用任何插件?我看下有哪些插件有声称能处理汇率的
- 哦,找到了一个叫做 Currency Converter 的,它注册的时候提供的 manifest 清单说它能做汇率转换的事情
- 那好,那我们看下这个插件 manifest 记录下 api 这一项指定的 openapi definition 的 yaml 文档,看下该调用哪个 api 来实现该功能,以及应该传入什么参数
- 进行远程 api 调用,获取到插件转换后的答案
- 将答案整理后返回给用户
那么回到题主副标题里问的:ChatGPT 怎么知道什么时候该使用插件呢?
其实就是上面列表中的第三点,每个插件注册的时候都必须提供一个 manifest 清单文件,其中有一项叫做 description_for_model,其功能就是要搞我们得大语言模型 ChatGPT 什么时候该调用该插件
The
description_for_modelattribute gives you the freedom to instruct the model on how to use your plugin generally.
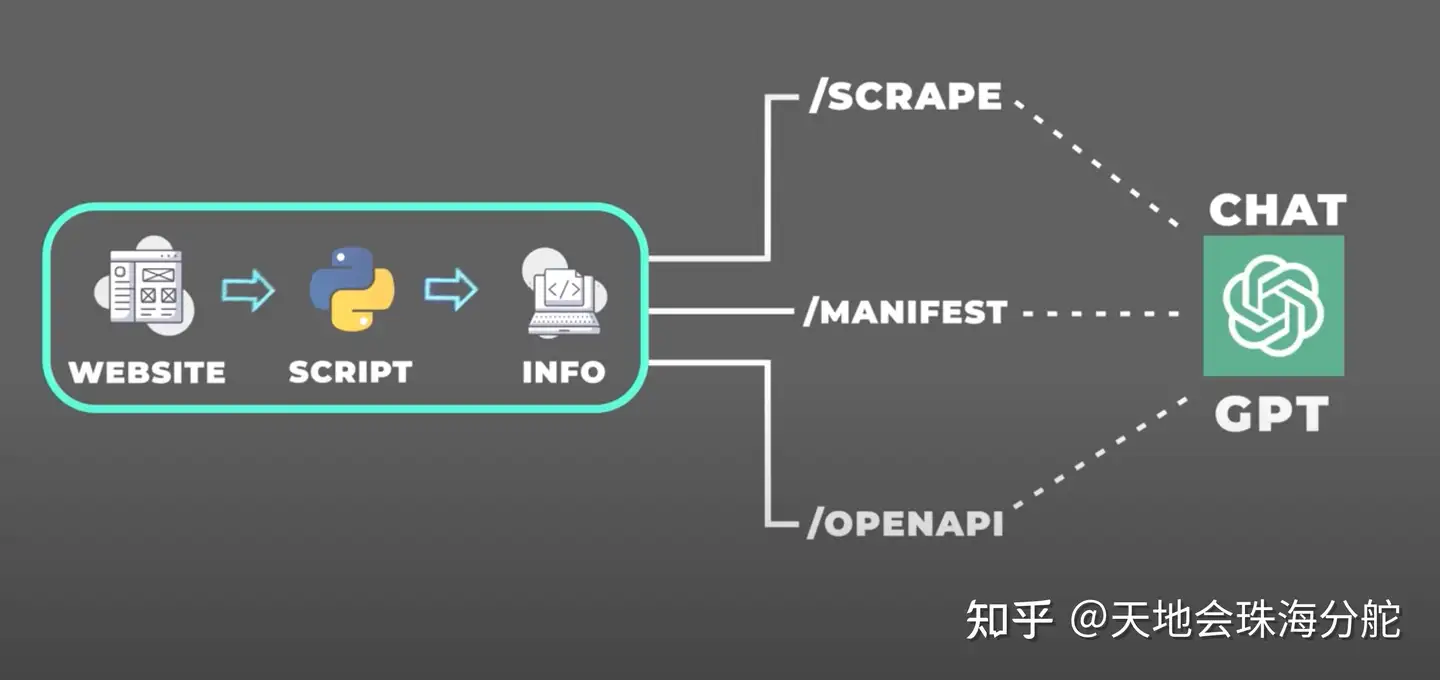
在上图中,左边显示的就是我们 远程web服务器 上实现的插件功能,中间部分就是我们要暴露出去的内容
- SCRAPE:就是我们要暴露出去给 ChatGPT 调用的 API 接口,可以是任意名字,和你 openapi 定义文件一致就行
- MANIFEST:清单文件,告诉 ChatGPT 在什么情况下需要调用我们这个插件
- OPENAPI:插件 API定义文件,告诉 ChatGPT 插件的 APIu 应该怎么调用,比如入口名称,输入参数等
如果你感兴趣自己去实现一个插件的,那可能就更加清楚了,可以参考我此前分享的一个教程
chatgpt开发入门(八)-实战如何开发一个chatgpt插件 - 知乎
我是 @天地会珠海分舵,持续关注和分享 ChatGPT | LLM | Diffusion Model 等 AI 领域资讯和编程知识,喜欢的请点个赞并关注我,谢谢!
增强类 chatGPT 应用
由于 chatGPT 本身不是联网的,无法获取最新的数据,且输入的 Token 也是有最大限制的,因此这类应用主要是为 chatGPT 突破这些限制而设计的,比如通过爬虫获取最新的数据,然后通过 chatGPT 来生成新的文本或总结这些文字,或者通过 Embedding 的方式将大量的文本向量化,然后把文本节点与向量化的组合存储到特殊设计的索引中,然后把用户输入的 Token 向量化后,通过词向量检索寻找相关的上下文,然后把这些上下文与用户输入的 Prompt 一同提交给 chatGPT 来获取答案。
要应用自己去处理这么多繁琐的工作显然是没有必要的,因为已经有非常好的开源项目去实现这些功能了,代表就是 jerryjliu/llama_index,使用这个库可以很容易实现这些增强功能,比如给 chatGPT 提供外部数据源,从而可以让它帮助我们分析网页、文档、新闻等等任务。
一些相关的应用:
- myGPTReader:myGPTReader 是 Slack 上的一个机器人,可以阅读和总结任何网页、文档(包括电子书)甚至来自 YouTube 的视频,它还可以通过语音与用户交流。
- chatpdf:通过给 chatGPT 提供 PDF 文档,然后可以针对此文档进行问答,或者总结文档内容。类似的开源实现有:guangzhengli/ChatFiles 与 arc53/DocsGPT。
- Copilot Hub:和上面的项目类似,不过多了能公开分享根据自己录入数据打造的问答机器人,比如能以乔布斯口吻回答问题的机器人。
- binary-husky/chatgpt_academic:科研工作专用 ChatGPT 拓展,特别优化学术 Paper 润色体验。
这些应用大多以 Embedding 为核心,当然也都存在共同的问题:因为 Embedding 是根据相似度去搜索相关文本的,如果问题非常宽泛,那么很难有效搜索到相关的问题,因此使用这些应用需要用户提供尽可能相关的问题,这样才能得到比较好的答案,也就是说需要用户提供好的 Prompt。
当然 openAI 官方也提供了插件市场,这些功能也可以在插件中实现,但目前插件仅能在网页版使用,而且插件现在并没有完全开放,只有一些特定的用户才能使用。
资源
我在这里分享这两个月使用 ChatGPT 给我的灵感产生的一个开源项目,你可以从中了解到 ChatGPT 官方插件:chatgpt-retrieval-plugin[3|3] ,微软 ChatGPT多模态:VisualChatGPT[4|4] 以及最近火爆的 Auto-GPT[5|5] 里面插件 (plugin) 和命令 (command) 与 ChatGPT 交互的工作原理,并且你可以通过本项目,自己也能开发一个新的工具来让 LLM(希望是国内的)也能获取外部知识、事务控制。
Plugin 官方文档
Plugin 测评
此外,我们也发现,联网、实时信息获取和阅读网页/PDF 功能是刚需。Wolfram(数学计算)、WebPilot(网页阅读)、Speak(专业翻译)、Prompt Perfect(提示词润色)、Show Me(流程图绘制)、AskYourPDF(PDF 阅读)、CreatiCode Scratch(少儿编程)、Chess(国际象棋游戏教练)、edX(公开课学习)、FiscalNote(政策咨询与分析)等插件商业化属性弱,功能强大,值得一试。
简单描述三
它是如何选择插件的
- 要想了解一个这个插件系统如何运行,最好的方法就是看看这些插件都是怎么生成出来的。
- 官方给我们演示了一个用 ChatGPT 生成 ChatGPT 插件的示例,但是这些不是我们关注的点,我只需要关心产物即可。
- 正好官方把 Retrieval 插件的代码开源了,我们可以根据官方示例与这个仓库的代码查个所以然。
清单文件🧾
- 我们可以看到示例首先会生成一个
manifest清单文件,并将该文件托管在yourdomain.com/.well-known/ai-plugin.json。 - 其中包含了其中包括插件功能的机器可读描述以及如何调用它们,以及面向用户的文档。
其中这个 json 文件有两个字段我们需要特别注意:
description_for_model:给 ChatGPT 看的描述。api: 存放了你可提供给 ChatGPT 调用 API 的 OpenAPI 规范文件。
OpenAPI 规范文件📃
- OpenAPI 规范 文件是一种机器可读的格式,用于描述 RESTful API 的设计和功能。它使用
YAML或JSON格式的文档,包括 API 的所有端点、操作和参数,并提供了对每个端点和操作的详细说明。 - 目的是提供一个标准的方式来描述和交互 RESTful API,以促进不同技术平台之间的互操作性和集成。
- 查阅 chatgpt-retrieval-plugin 的
openapi.yaml我们可以看到,这其实就是一个标准的 OpenAPI 规范文件。 - 那么说明每个插件只需要提供一份标准的、接口描述准确的 OpenAPI 规范文件即可让 ChatGPT 了解你的 API 的入参出参并加以调用。
- 如何正确规范的写好一份 OpenAPI 描述文件,我们可以参考 OpenAPI 规范 (中文版)
- 当然啦,现在的 OpenAPI 文件都可以自动生成了,你可以使用 Apifox 利用可视化的界面来编写你的 API 文档,并且加以自然语言的接口描述信息,选择导出 OpenAPI 格式就可以得到一份非常标准的 OpenAPI 格式描述文件,大大提升你的效率。
现在我们知道了 ❗️
搞懂了一个插件是如何开发的,这么看下来就很清晰了:
- 用户使用自然语言向 ChatGPT 提问。
- ChatGPT 根据用户的需求去查找符合描述的插件系统。
- 根据插件系统的 API 描述文档来选择符合当前上下文的 API 进行调用。
- 得到结果后会将它继续「喂」给上下文,由此判断需不需要进行使用下一个插件。
- 最终会得到一个满足用户预期的自然语言回答,包括图表、代码等信息。
- 这样一来,就完成了该系统神奇的所有部分。